浅谈数据库索引的结构设计与优化
一. 了解数据库索引的必要性
对于稍微数据量大一点的表,如果不适用索引,那么性能效率都会很低;如果绕开了索引,直接进行分区分表,数据库集群读写分离来解决性能问题的话,那么未免也太小题大做了。
对于大多数中小型系统,索引能够帮你解决90%的性能问题,所以索引是解决关系型数据库非常有利的武器。
二. 表和索引结构
1.索引页和表页
表和索引都是存在页中。页的大小一般是4KB.页的大小仅仅决定了一个页能存储多少个索引行,表行。
2.索引行
索引行是很有用的一个概念对于访问路径的时候。索引行的概念可以通过下图来了解:
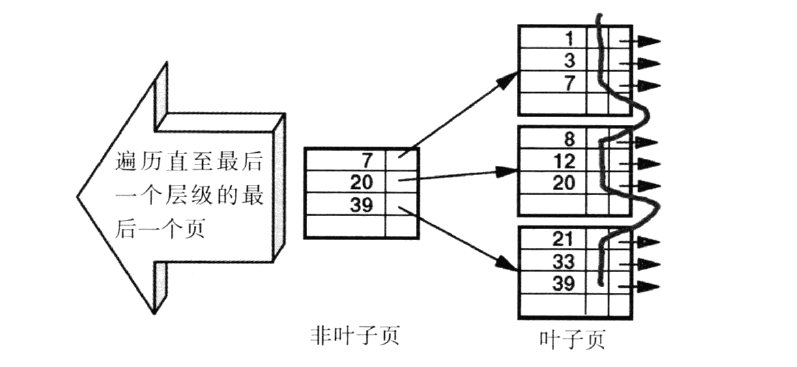
每一个页上包含了很多索引行,每个索引行里存储着索引条目和指向下一层的页,这种数据结构为B-tree结构。
3.缓冲池和磁盘I/O
我们可以使用内存的缓冲池来减小到磁盘的访问。这一策略对sql性能表现至关重要。下图展示了磁盘读取到缓冲区的巨大成本:
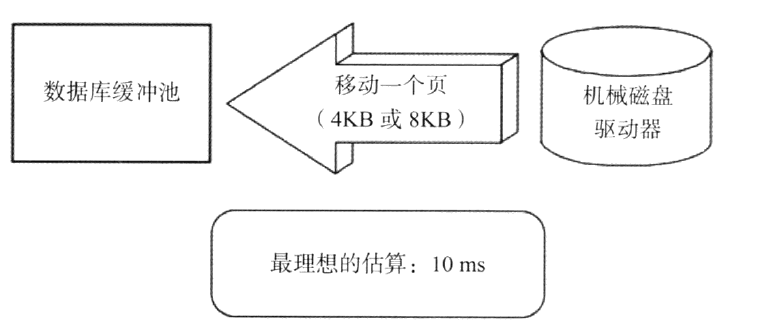
当我们需要某一页的一行数据时,和需要这一页的数据时,所花费的时间是相等的。可以通过执行:show global status like 'innodb%read%';来判断缓存命中的情况,具体的参数可以自行在网上查找:
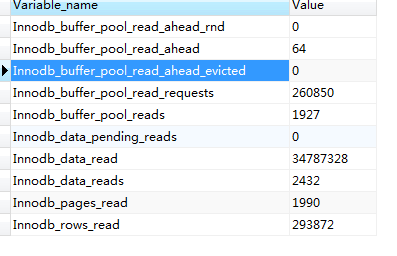
可以算出来缓存命中率为=260850/(64+260850+1927)=99.24%,是很高的命中率了。
4.硬件特性
硬盘磁盘的图可以用下图简单表示:

我们的数据库表里的数据就保存在磁盘上,如果要读取数据,就要砖头磁盘,用磁头和磁盘的磁力来改变状态,来读取数据,所以,我们应该尽量少的转动磁盘,来优化数据库性能。
三.SQL处理过程
我们现在先讨论基础的处理过程,先来谈谈处理过程的一些基本概念。
1.关键字(谓词)
where子句由一个或者多个谓词组成,比如说:
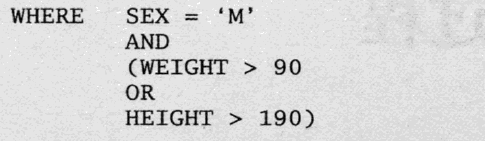
那么这个就有一个组合谓词,组合谓词是索引设计的主要入手点。
2.过滤因子
过滤因子是描述谓词的选择性,它主要依赖于列值的分布情况。它是一个计算值,公式为:

用来计算谓词结果集的返回大小估算。
3.物化结果集
是执行数据库访问来构建结果集。最好的情况下,是从数据库缓冲池返回一条记录,最坏的情况就是访问大量的磁盘读取数据。
物化结果集有2种方式:
1.一次FETCH物化返回一条数据
2.提前物化
四.为SELECT语句创建理想索引
1.三星索引
三星索引是指一条sql所能达到索引的最优设计。
第一颗星:
如果与一个查询相关的索引行是相邻的,那么这个索引就为第一颗星。
第二颗星:
如果索引行的顺序与查询语句一致,则为第二颗星。
第三颗星:
查询的数据为索引的信息,不需要额外的磁盘随机读。这一颗星能大大改善性能。
假设有一条sql语句如下所示:

如果要满足一星索引:索引的顺序可以是LNAME,CITY或者CITY,LNAME
如果要满足第二星索引:FNAME加在LNAME,CITY或者CITY,LNAME后面
如果要满足第三索引:CNO也要在索引里面
那么组合起来得三星索引就是:LNAME,CITY,FNAME,CNO或者CITY,LNAME,FNAME,CNO
五.前瞻性索引
1.发现不合适的索引
有两种基本的方法来发现不合适的索引:
1.基本问题法(BQ)
2.快速上线评估法(QUBE)
在这里我仅仅讨论一下快速上线评估法(QUBE)
2.快速上线评估法(QUBE)
QUBE是悲观上限,它的目的是在早期发现程序设计的缺陷,并且及时更改。QUBE忽略了排队时间,锁竞争时间等,把问题单一化来评估sql的性能问题。
下图就是QUBE计算评估sql时间公式:

可以发现,TR和TS存在巨大的时间差距,随机访问会消耗大量的时间,那么来说说随机和顺序访问。
随机访问:
先说一说磁盘读和访问的区别。读是读取一页的信息,访问时访问一行的信息。所以单次随机访问的时间与一次磁盘随机读取的时间相同,都是10ms。
顺序访问:
一次顺序读是指物理上读取连续的下一行,这一行要么在同一页中,要么在下一页中,估算出来时间是0.01ms。
FETCH:
是FETCH调用次数来确定被接收行的数量。F的时间数量级要比TS大一级,但是要比TR小2级。
下面给出一个简单的事例来说明QUBE计算方法:
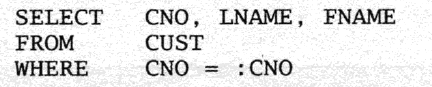
那么可以根据上面的公式得到:

QUBE算法其实可以多结合自己的项目事例来计算判断一下,因为这个公式是很多年前的了,现在磁盘读写能力肯定有了显著提升,但是判断sql性能的方式是一致的。