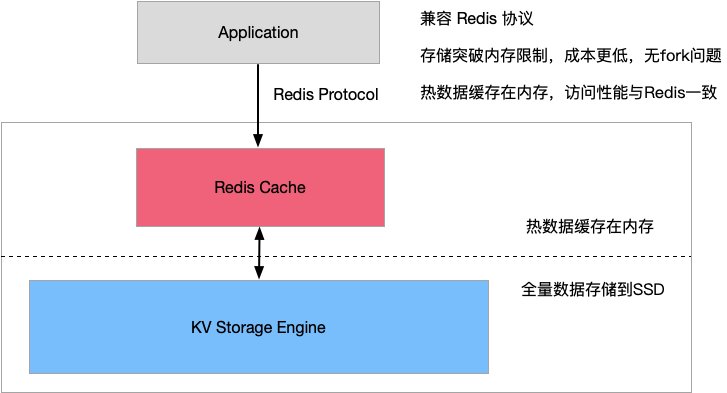
Redis 混合存储实例是阿里云自主研发的兼容Redis协议和特性的云数据库产品,混合存储实例突破 Redis 数据必须全部存储到内存的限制,使用磁盘存储全量数据,并将热数据缓存到内存,实现访问性能与存储成本的完美平衡。
架构及特性
命令兼容
混合存储兼容绝大多数 Redis 命令,与原生 Redis 相比,如下命令不支持或受限制;不支持的主要原因是考虑到性能,如业务中有使用到,请提交工单。
| Keys(键) | List(链表) | Scripting(Lua脚本) |
|---|---|---|
| RENAME | LINSERT | SCRIPT 不支持LOAD和DEBUG子命令 |
| RENAMENX | LREM | |
| MOVE | ||
| SWAPDB | ||
| SORT 不支持STORE选项 |
选型指南 - 场景

选型指南 - 规格
选择混合存储实例时,需要选择合适的【内存配置 + 磁盘配置】;磁盘决定能存储的数据总量,内存决定能存储的热数据总量,实例生产时会根据存储的规格配置选择合适的CPU资源配置,目前暂不支持自定义CPU核数。
比如【64GB内存 + 256GB磁盘】实例,意思是实例最多能存储 256GB 的数据(以KV存储引擎的物理文件总大小为准),其中 64GB 数据可以缓存在内存。
案例1:用户A 使用 Redis Cluster 存储了 100GB 的数据,总的访问QPS不到2W,其中80%的数据都很少访问到。用户A 可以使用 【32GB内存 + 128GB磁盘】 混合存储实例,节省了近 70GB 的内存存储,存储成本下降50%+。
案例2:用户B 在IDC自建 Pika/SSDB 实例,解决Redis存储成本高的问题,存储了约 400GB 的数据,其中活跃访问的在10%左右,集群运维负担很重,想迁移至云数据库;用户B 可以使用 【64GB内存 + 512GB磁盘】混合存储实例,来保证免运维的同时,服务质量不下降。
注:因 Redis 数据存储到 KV 存储引擎,每个key都会额外元数据信息,存储空间占用会有一定的放大,建议在磁盘空间选择上,留有适当余量,按实际存储需求的 1.2 - 1.5倍预估。
性能指标
Redis 混合存储的性能与内存磁盘配比,以及业务的访问高度相关;根据规格配置及业务访问模式的不同,简单 set/get 的性能可在几千到数万之间波动。最好情况所有的访问都内存命中,性能与 Redis 内存版基本一致;最差情况所有的访问都需要从磁盘读取。
测试场景:2000w key,value大小为1KB,25%的热key能存储在内存,get 请求测试数据如下
| 测试集 | 内存版(100%数据在内存) | 混合存储版(25%数据在内存) |
|---|---|---|
| 随机访问 | 12.3(万) | 1.5 |
| 高斯分布80%的概率访问20%的key | 12.0 | 5.4 |
| 高斯分布99%的概率访问1%的key | 13.5 | 11.4 |
应用场景
视频直播类
视频直播类业务往往存在大量热点数据,大部分的请求都来自于热门的直播间。使用 Redis 混合存储型实例,内存中保留热门直播间的数据,不活跃的直播间数据被自动存储到磁盘上,可以达到对有限内存的最佳利用效果。
电商类
电商类应用有大量的商品数据,新上架的商品会被频繁访问,而较老的商品访问热度不高;使用 Redis 混合存储型实例,可以轻松突破内存容量限制,将大量的商品数据存储到磁盘,在正常业务请求中,活跃的商品数据会逐步缓存在内存中,以最低的成本满足业务需求。
在线教育类
在线教育类的场景,有大量的课程、题库、师生交流信息等数据,通常只有热门课程、最新题库题库会被频繁访问; 使用 Redis 混合存储型,将大量的课程信息存储到磁盘,活跃的课程、题库信息会换入到内存并常驻内存,保证高频访问数据的性能,实现性能与存储成本的平衡。
其他场景
其他数据访问有明显冷热特性,对性能要求不高的场景均可使用Redis混合存储来降低存储成本。
一种稳定可靠、性能卓越、可弹性伸缩的数据库服务。基于飞天分布式系统和全SSD盘高性能存储,支持主备版和集群版两套高可用架构。
本文作者:张友东
本文为云栖社区原创内容,未经允许不得转载。