前言
在上一篇文章 Kubernetes 弹性伸缩全场景解析 (一):概念延伸与组件布局中,我们介绍了在 Kubernetes 在处理弹性伸缩时的设计理念以及相关组件的布局,在今天这篇文章中,会为大家介绍在 Kubernetes 中弹性伸缩最常用的组件 HPA(Horizontal Pod Autoscaler)。HPA 是通过计算 Pod 的实际工作负载进行重新容量规划的组件,在资源池符合满足条件的前提下,HPA 可以很好的实现弹性伸缩的模型。HPA 到目前为止,已经演进了三个大版本,本文将会为大家详细解析 HPA 底层的原理以及在 Kubernetes 中弹性伸缩概念的演变历程。
HPA 基本原理
HPA 是根据实际工作负载水平伸缩容器数目的组件,从中可以提炼出两个非常重要的关键字:负载和数目。我们可以用一个非常简单的数学公式进行归纳:
下面举一个实际例子进行上述公式的阐述。
假设存在一个叫 A 的 Deployment,包含3个 Pod,每个副本的 Request 值是 1 核,当前 3 个 Pod 的 CPU 利用率分别是 60%、70% 与 80%,此时我们设置 HPA 阈值为 50%,最小副本为 3,最大副本为 10。接下来我们将上述的数据带入公式中:
- 总的
Pod的利用率是 60%+70%+80% = 210%; - 当前的
Target是 3; - 算式的结果是 70%,大于50%阈值,因此当前的
Target数目过小,需要进行扩容; - 重新设置
Target值为 5,此时算式的结果为 42% 低于 50%,判断还需要扩容两个容器; - 此时 HPA 设置
Replicas为 5,进行Pod的水平扩容。
经过上面的推演,可以协助开发者快速理解 HPA 最核心的原理,不过上面的推演结果和实际情况下是有所出入的,如果开发者进行试验的话,会发现 Replicas 最终的结果是 6 而不是 5。这是由于 HPA 中一些细节的处理导致的,主要包含如下三个主要的方面:
- 噪声处理
通过上面的公式可以发现,Target 的数目很大程度上会影响最终的结果,而在 Kubernetes 中,无论是变更或者升级,都更倾向于使用 Recreate 而不是 Restart 的方式进行处理。这就导致了在 Deployment 的生命周期中,可能会出现某一个时间,Target 会由于计算了 Starting 或者 Stopping 的 Pod 而变得很大。这就会给 HPA 的计算带来非常大的噪声,在 HPA Controller 的计算中,如果发现当前的对象存在 Starting 或者 Stopping 的 Pod 会直接跳过当前的计算周期,等待状态都变为 Running 再进行计算。
- 冷却周期
在弹性伸缩中,冷却周期是不能逃避的一个话题,很多时候我们期望快速弹出与快速回收,而另一方面,我们又不希望集群震荡,所以一个弹性伸缩活动冷却周期的具体数值是多少,一直被开发者所挑战。在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。
- 边界值计算
我们回到刚才的计算公式,第一次我们算出需要弹出的容器数目是 5,此时扩容后整体的负载是 42%,但是我们似乎忽略了一个问题:一个全新的 Pod 启动会不会自己就占用了部分资源?此外,8% 的缓冲区是否就能够缓解整体的负载情况?要知道当一次弹性扩容完成后,下一次扩容要最少等待 3 分钟才可以继续扩容。为了解决这些问题,HPA 引入了边界值 △,目前在计算边界条件时,会自动加入 10% 的缓冲,这也是为什么在刚才的例子中最终的计算结果为 6 的原因。
HPA 的演进历程
在了解了 HPA 的基本原理后,我们来聊一下 HPA 的演进历程,目前 HPA 已经支持了 autoscaling/v1、autoscaling/v1beta1 和 autoscaling/v1beta2 三个大版本。大部分的开发者目前比较熟悉的是autoscaling/v1 的版本,这个版本的特点是只支持 CPU 一个指标的弹性伸缩,大致的 yaml 内容如下:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
接下来我们再来看一下 v2beta1 与 v2beta2 的 yaml,会发现里面支持的 metrics 类型增加了很多,结构也复杂了很多。
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
kind: AverageUtilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
targetAverageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: extensions/v1beta1
kind: Ingress
name: main-route
target:
kind: Value
value: 10k
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50而这些变化的产生不得不提的是 Kubernetes 社区中对监控与监控指标的认识与转变。在 Kubernetes 中,有两个核心的监控组件 Heapster 与 Metrics Server。Heapster 是早期 Kubernetes 社区中唯一的监控组件,它所包含的功能很强大,通过采集 kubelet 提供的 metrics 接口,并支持监控数据的离线与归档。
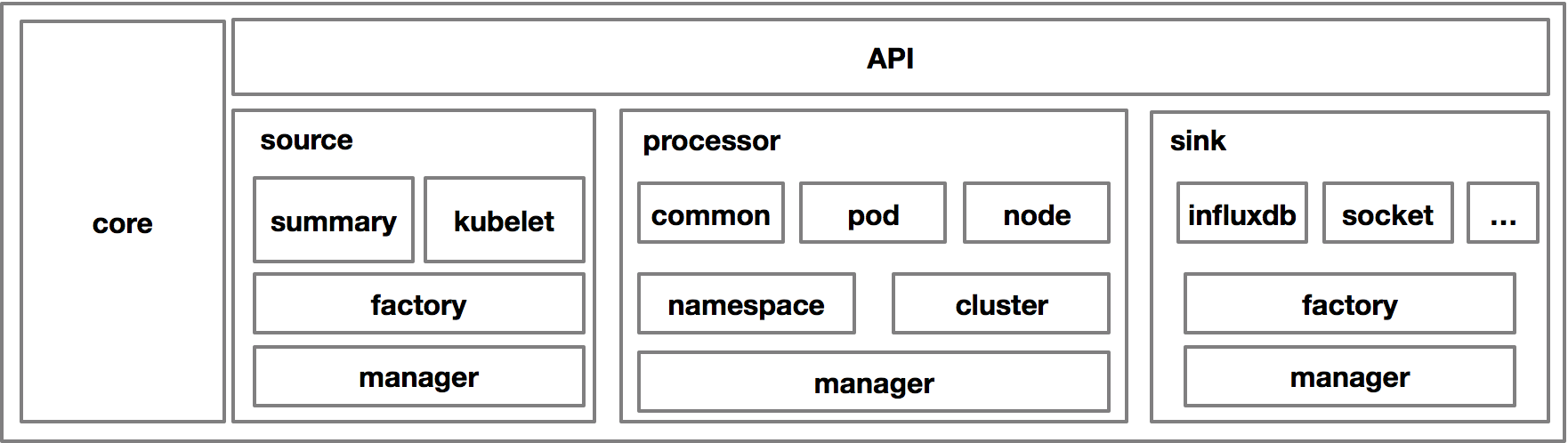
大致的架构图如上:source 的部分是不同的数据来源,主要是 kubelet 的 common api 与后来提供的 summary api;processor 的作用是将采集的数据进行处理,分别在 namespace 级别、cluster 级别进行聚合,并创建新的聚合类型的监控数据;sink 的作用是数据离线与归档,常见的归档方式包括 influxdb、kafka 等等。Heapster 组件在相当长时间成为了 Kubernetes 社区中监控数据的唯一来源,也因此有非常多的和监控相关的组件通过 Heapster 的链路进行监控数据的消费。但是后来,Kubernetes 社区发现了 Heapster 存在非常严重的几个问题:
- 强大繁多的 Sink 由不同的 Maintainer 进行维护,50% 以上的 Heapster Issues 都是关于 Sink 无法使用的,而由于 Maintainer 的活跃度不同造成 Heapster 社区有大量的 issues 无法解决;
- 对于开发者而言,监控数据的类型已经不再是 CPU、Memory 这么简单的几个指标项了,越来越多的开发者需要应用内或者接入层的监控指标,例如 ingress 的 QPS、应用的在线活跃人数等等。而这些指标的获取是 Heapster 无法实现的;
- Prometheus 的成熟让 Heapster 的生存空间不断被挤压,自从 Prometheus 被 CNCF 收录为孵化项目,Heapster 的不可替代地位被正式移除。
社区经过反思后,决定将监控的指标边界进行划分,分为 Resource、Custom 和 External 三种不同的 Metrics,而 Heapster(Metrics Server) 的定位就只关心 Resource 这一种指标类型。为了解决代码维护性的问题,Metrics Server 对 Heapster 进行了裁剪,裁剪后的架构如下:
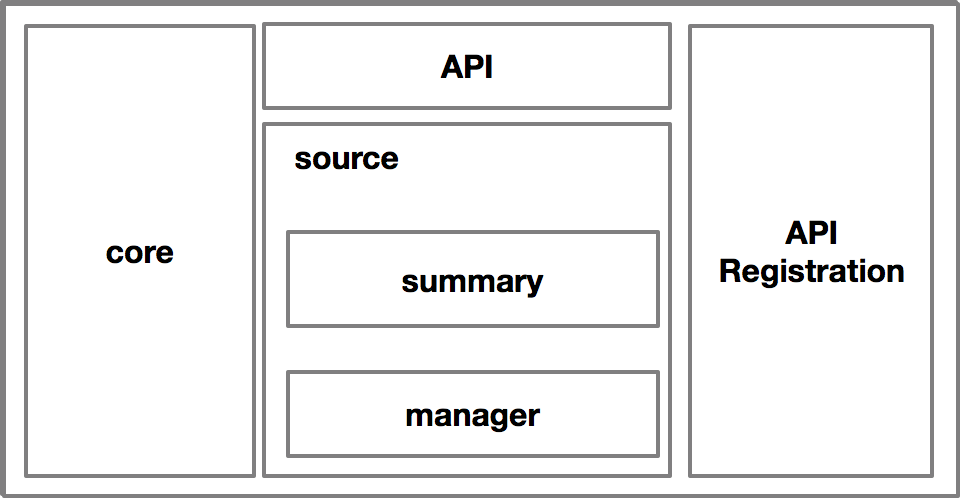
去掉了 Sink 的机制,并将调用方式改为标准的 API 注册的方式,这样的好处是既精简了核心代码的逻辑又提供了替代的可能,也就是说此时 Metrics Server 也是可以替代的,只要实现了相同的 API 接口,并注册到 API Server 上,就可以替代 Metrics Server。
接下来我们解析一下三种不同的 Metrics 与使用的场景:
| API | 注释 | |
|---|---|---|
| Resource | metrics.k8s.io | Pod的资源指标,计算的时要除以Pod数目再对比阈值进行判断 |
| Custom | custom.metrics.k8s.io | Object: CRD等对象的监控指标,直接计算指标比对阈值 Pods : 每个Pod的自定义指标,计算时要除以Pods的数目 |
| External | external.metrics.k8s.io | External:集群指标的监控指标,通常由云厂商实现 |
其中 autoscaling/v2beta1 支持 Resource 与 Custom 两种指标,而 autoscaling/v2beta2 中增加了 External 的指标的支持。
最后
HPA 目前已经进入了 GA 阶段,在大体的功能上面不会进行过多的变化,目前社区的主要发力点在如何配置化的调整细节参数、丰富监控 adapter 的实现等等。在本文中,我们在概念上给大家介绍了 HPA 的一些原理以及发展的趋势,在下一篇文章中,我们会为大家讲解如何开启 v2beta1 与 v2beta2 的。
本文作者:一绿舟
本文为云栖社区原创内容,未经允许不得转载。