语言模型
- 什么是语言模型
语言模型 就是估测一些词的序列的概率,即预测 p(w1, w2, w3 ... wn),
一个应用就是句子的生成。
2. 语言模型的种类
- Ngram
ngram是一种统计的方法,它相当于固定了一个窗口,在这个窗口内的词是相关的,也就是第n个词和前n个词相关:P(s) = p(w1) p(w2|w1) p(w3| w1, w2) ... p(wn|w1, w2 ...wn-1)
所以要求这个概率P(s), 就得求所有的条件概率,这就要求数据要足够大,能包含所有的这些词,如果有的条件概率是0,要就行平滑处理
优点:考虑了词的顺序
缺点:没法考察词向量之间关系,同时向量太稀疏
与连续空间的词表示法语言学规则模型对比(例如word2vec构建出的词向量),N-gram语言模型还有以下的局限性:
N-gram模型是根据相互之间没有任何遗传属性的离散单元词而构建,从而不具备连续空间中的词向量所满足的语义上的优势:相似意义的词语具有相似的词向量,从而当系统模型针对某一词语或词序列调整参数时,相似意义的词语和词序列也会发生改变。
n-gram中平滑处理方法
1、加1法
![]()
2、加k法
![]()
加法平滑,会给未出现的词语赋予一定的权重,这就使得之前出现的词语的频次与平滑后的相比变小了,有点劫富济贫的感觉
3、Interpolation 插值算法
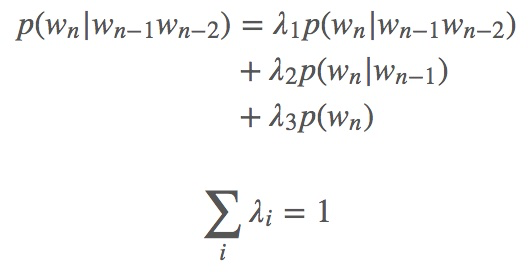
将所以小于等于n的gram进行线性累加,lambda如何选择与更新?
将训练集分为三类:训练集、验证集或叫hold out,测试集
在训练集上的lambda是自己设置的,然后在验证集上进行更新,更新的一种方法,以当前的lambda(自己设置的)为中心,上下选择一个范围,可以得到在这个范围里的lambda的一个组合,对于每个组合求其困惑度或者概率P,最优解就是其中使得困惑度最小或者概率最大的那对lambda,
4、backoff

如果高阶模型计数结果为0,可以转向使用低阶模型代替
- 基于神经网络的语言模型
它对于每一部分相乘概率P(wi|wj)不是通过统计得来的,而是通过神经网络预测出来的

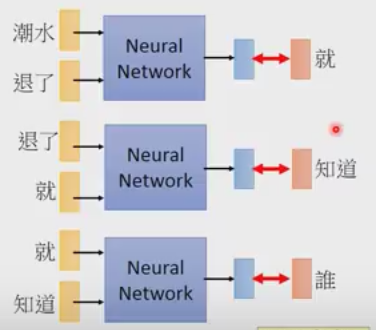
如图所示,训练一个神经网络,它的功能就是根据前两个词预测下一个词,输入 ‘潮水’ 和 ‘退了’,输出 预测出 ‘就’ 的概率, 然后利用 优化交叉熵函数(为什么是交叉熵,应该是应为求得是分布,衡量两个分布用的是交叉熵)
有了上述预测函数,就可以算句子的概率了,这里的每个条件概率都是通过神经网络进行预测出来的

对每一个单词用 one-hot编码,然后放入网络会得到下一个词出现的概率,最后累乘得到句子的概率。
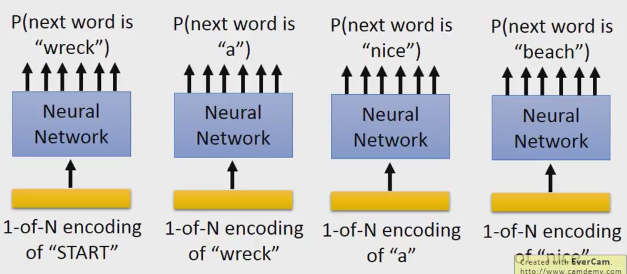
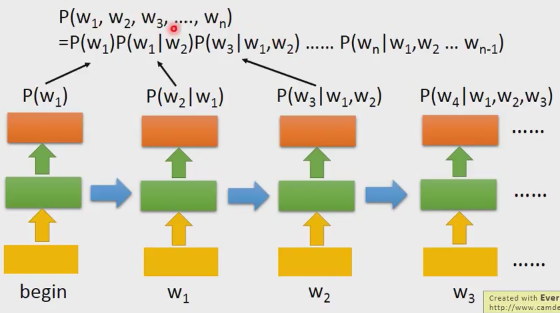
- 基于RNN的语言模型
可以看出上图中是基于 bigram 模型的,因为他的输入是有要求的,只能是有限的个数,如要要是基于 ngram,就要借助RNN的特点了
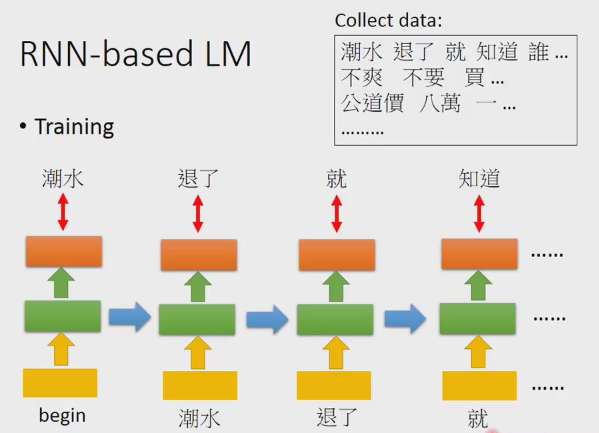
第一步:输入 begin得到潮水的概率,P(潮水|begin)
第二步:输入潮水得到退了的概率,P(退了|潮水)
第三步:输入退了得到就得概率, P(就|退了,潮水)
第四步:输入就得到知道的概率, P(知道|就,退了,潮水)
连乘起来就是ngram的形式。
3、为什么用NN
1、数据不够,一些概率会为0,这就要求数据量很多,数据很多出现结果就是数据稀疏,解决方法平滑

如上述例子,dog 是可以 jump的, cat也是可以 ran 的,但是语料中缺不存在,所以这个概率是一定的值的,通过smoothing赋予一个很小的概率,这种平滑很粗糙
以bigram为例,统计每个单词下一个出现的概率,会出现数据稀疏问题
矩阵分解解决数据稀疏问题:

横轴代表历史,纵轴代表词汇,P(ran|dog) = 0.2, 在表中好多都是0,这是因为在原来的语料库中不存在。这个好比是推荐系统,横轴代表用户,纵轴代表物品,表示0的地方代表曾经用户没有购买过该产品,但并不表示以后都不购买
所以,我们可以将历史表示成 h1, 将词汇表示成 v1, 概率值我们用n来表示,根据已有的数据,我们构造成下面的损失函数,优化该函数得到vi 和 hj
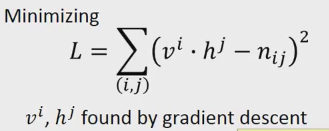
通过上面的训练,我们可以得到vi, hj, 对于 p(jumped | cat) = 0.2, p(jumped | dog) = 0, 我们训练出来的cat 和 dog是有一定相似性的,因此可以预测出 p(jumped | dog) = v2 h1
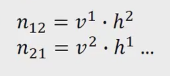

总之,矩阵分解相当于平滑处理,只不过ngram 中是手动平滑,矩阵分解中是自动平滑。
矩阵分解可以用神经网络方法来做

第二次表示dog的历史h(dog),v(ran),v(cried)分别表示ran和cried的向量,h(dog)v(ran) = p(ran | dog), 通过与目标构造交叉熵损失函数
其中cat dog都是通过 one-hot 进行编码得到。
与ngram相比,参数减少了
RNN
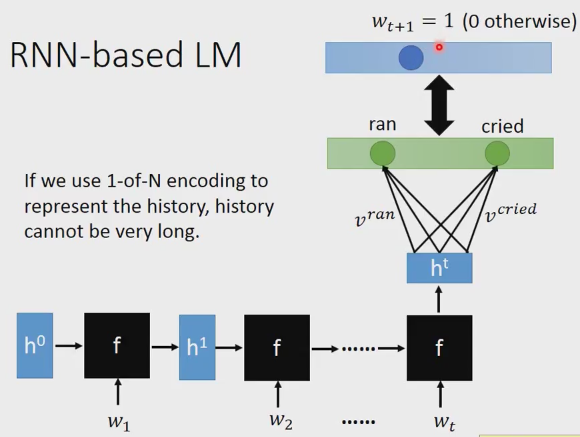
输入 预测的是 P(W t+1 | W1, W2 ... Wt), 将w1放入网络,得到h1, 再放入w2得到h2 ... 最后得到ht, ht与vocabulary进行相乘,得到Wt+1
参考:
https://blog.csdn.net/w5688414/article/details/78012409