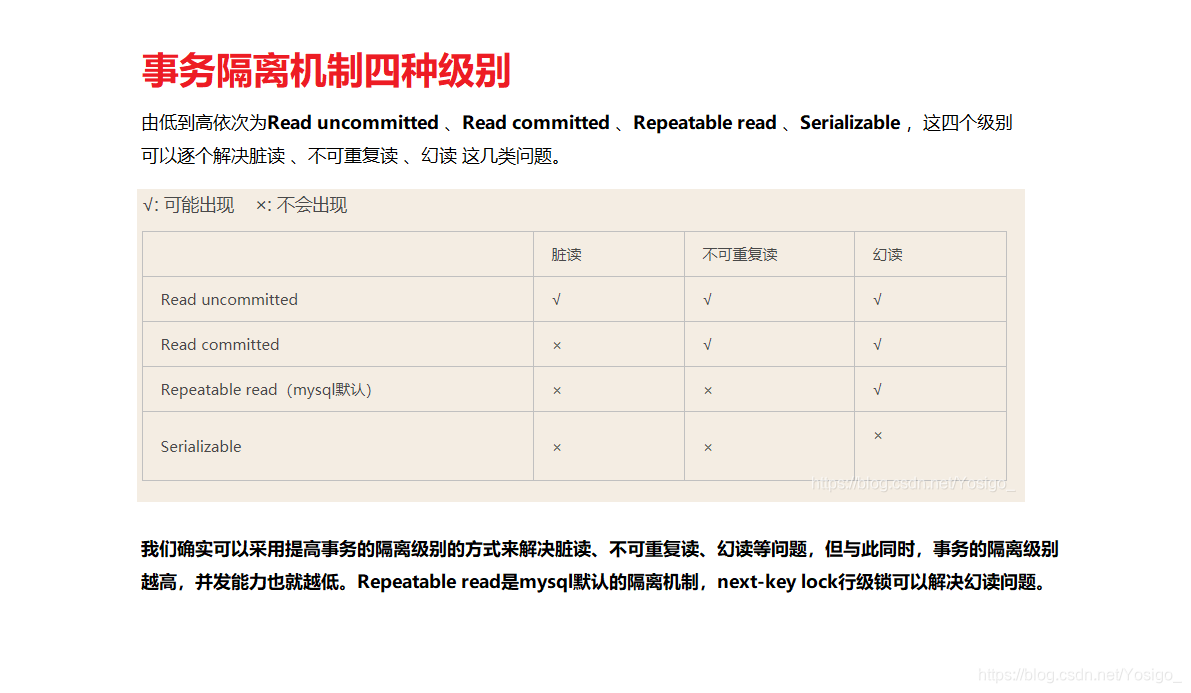
数据库读现象
数据库管理软件的“读现象”指的是当多个事务并发执行时,在读取数据方面可能碰到的问题,包括有脏读、不可重复读和幻读。
创建数据表
# 创建数据表
create table t1(
id int primary key auto_increment,
name varchar(20) not null,
age int(3) unsigned not null default 20
);
insert into t1(name) values
('nana'),('lala'),('haha'),
('xixi'),('dudu'),('xiexie'),
('jiujiu'),('牛牛'),('局局'),
('丫丫'),('猪猪'),('珠珠'),
('竹竹'),('噔噔'),('流川枫'),
('樱木花道'),('三井寿'),('宫田');
update t1 set age = 18 where id <=3;
mysql> select * from t1;
+----+--------------+-----+
| id | name | age |
+----+--------------+-----+
| 1 | nana | 18 |
| 2 | lala | 18 |
| 3 | haha | 18 |
| 4 | xixi | 20 |
| 5 | dudu | 20 |
| 6 | xiexie | 20 |
| 7 | jiujiu | 20 |
| 8 | 牛牛 | 20 |
| 9 | 局局 | 20 |
| 10 | 丫丫 | 20 |
| 11 | 猪猪 | 20 |
| 12 | 珠珠 | 20 |
| 13 | 竹竹 | 20 |
| 14 | 噔噔 | 20 |
| 15 | 流川枫 | 20 |
| 16 | 樱木花道 | 20 |
| 17 | 三井寿 | 20 |
| 18 | 宫田 | 20 |
+----+--------------+-----+
18 rows in set (0.00 sec)
脏读
事务A更新了一行记录的内容,但是并没有提交所做的修改。
事务B读取更新后的行,然后事务A执行回滚操作,取消了刚才所做的修改。此时事务B所读取的行就无效了,称之为脏数据。
一些数据库管理软件会自带相应的机制去解决脏读现象,所以该实验无法演示。
不可重复读
事务A读取一行记录,紧接着事务B修改了事务A刚才读取的那一行记录并且提交了。
然后事务A又再次读取这行记录,发现与刚才读取的结果不同。这就称为"不可重复"读,因为事务A原来读取的那行记录已经发生了变化。
- 在基于锁的并发控制中"不可重复读"现象发生在当执行select操作时没有获得读锁,或者select操作执行完后马上释放了读锁。
- 多版本并发控制中当没有要求一个提交冲突的事务回滚也会发生"不可重复读"现象。
事务A:
mysql> select * from t1 where id=1;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 18 |
+----+------+-----+
1 row in set (0.00 sec)
事务B:
mysql> update t1 set age=20 where id=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
事务A:
mysql> select * from t1 where id=1;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
+----+------+-----+
1 row in set (0.00 sec)
幻读
幻读是不可重复读的一种特殊场景
事务A读取或修改了指定的where子句所返回的结果集。
然后事务B新插入一行记录,这行记录刚好满足事务A所使用的查询条件中where子句的条件。
这时,事务A又使用相同的查询再次对表进行检索,但是此时却看到事务B刚才插入的新行;或者发现了where子句范围内,有着未曾修改过的记录。就好像"幻觉"一样,因为对事务A来说这一行就像突然出现的一样。
一般解决幻读的方法是增加范围锁,锁定检锁范围为只读,这样就避免了幻读。
# 建表
create table t2(
id int,
name varchar(16)
);
mysql> insert t2 values(1,"aaa"),(5,"bbb"),(7,"ccc"),(9,"haha");
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from t2;
+------+------+
| id | name |
+------+------+
| 1 | aaa |
| 5 | bbb |
| 7 | ccc |
| 9 | haha |
+------+------+
4 rows in set (0.01 sec)
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update t2 set name="nana" where 1<id<10;
Query OK, 4 rows affected (0.00 sec)
Rows matched: 4 Changed: 4 Warnings: 0
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
# 假设事务B在事务A执行update语句的同时,也提交了insert语句,且插入成功了。
-- 处于阻塞状态,原因是因为mysql默认的锁机制解决了幻读问题。
mysql> insert t2 values(6,"xixi");
事务A:
# 事务A这个时候查看t2表数据更新的状态,发现sql语句执行成功了,但是where条件中有一条数据没有执行成功。
# 这种现象对于事务A来说就是幻读现象。
mysql> select * from t2 where 1<id<10;
+------+------+
| id | name |
+------+------+
| 1 | nana |
| 5 | nana |
| 7 | nana |
| 9 | nana |
| 6 | xixi |
+------+------+
5 rows in set (0.00 sec)
解决方案
-
脏写、脏读、不可重复读、幻读,都是因为业务系统会多线程并发执行,每个线程可能都会开启一个事务,每个事务都会执行增删改查操作。然后数据库会并发执行多个事务,多个事务可能会并发地对缓存页里的同一批数据进行增删改查操作,于是这个并发增删改查同一批数据的问题,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。
-
所以这些问题的本质,都是数据库的多事务并发问题,那么为了解决多事务并发带来的脏读、不可重复读、幻读等读等问题,数据库才设计了锁机制、事务隔离机制、MVCC多版本隔离机制,用一整套机制来解决多事务并发问题。
数据库锁机制
什么是锁?
- 锁是为了协调多个进程或线程并发访问某一资源的机制,主要是为了保障数据安全。
为何要加入锁机制?
- 锁机制可以将并发的数据访问顺序化,以保证数据库中数据的一致性与有效性。
- 以互斥锁为例,可以让多个并发的任务同一时间只有一个运行(注意这不是串行),牺牲了效率但是换来了数据安全。
锁的优点和缺点
- 优点:保证了并发场景下的数据安全。
- 缺点:降低了效率。
因此我们在使用锁的时候应该尽可能的缩小锁的范围,即锁住的数据越小越好,并发能力越高。
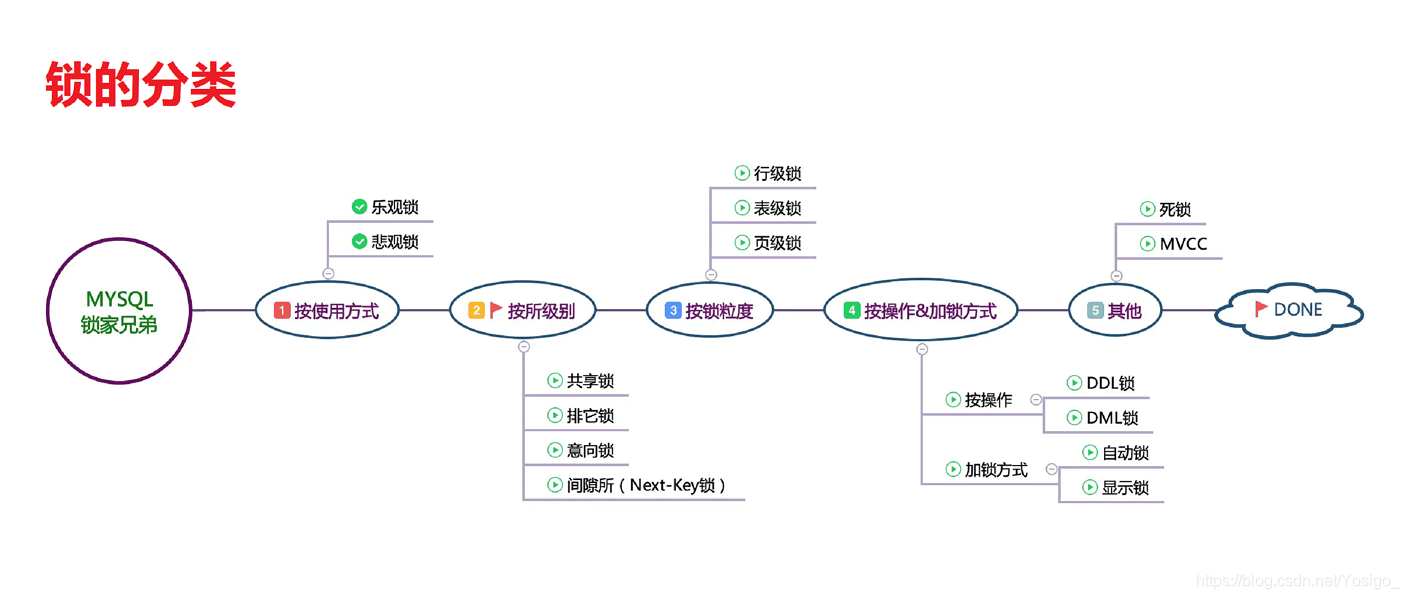
锁的分类
按锁的粒度划分,可分为行级锁、表级锁、页级锁。(mysql支持)
按锁级别划分,可分为共享锁、排他锁
按使用方式划分,可分为乐观锁、悲观锁
按加锁方式划分,可分为自动锁、显式锁
按操作划分,可分为DML锁、DDL锁
MySQL中的锁按粒度分类
在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
行级锁
行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。
其加锁粒度最小,但加锁的开销也最大。特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 支持引擎:InnoDB。
分类:行级锁分为共享锁和排他锁。
表级锁(偏向于读)
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。
最常使用的MYISAM与INNODB都支持表级锁定。特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。 支持引擎:MyISAM、MEMORY、InnoDB。
分类:表级锁分为共享锁和排他锁。-- 加了写表锁之后,只有加锁的事务可以进行读写操作。 -- 其他事务不可以读,也不可以写 lock table t1 write; -- 加了读表锁之后,只有加锁的事务可以进行读行为,但是无法进行数据的写行为。 -- 其他事务可以读,但是不可以写 lock table t1 read; -- 释放表级锁 unlock tables;
事务A:
# 锁住t1表的写操作
mysql> lock table t1 write;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t1 where id<3;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 18 |
+----+------+-----+
2 rows in set (0.00 sec)
mysql> update t1 set name="lili" where id=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t1 where id<3;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lili | 18 |
+----+------+-----+
2 rows in set (0.00 sec)
事务B:
# 无法读t1表
mysql> select * from t1 where id<3;
# 无法写t1表
mysql> update t1 set name="kiki" where id=2;
事务A:
# 释放表锁
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
事务A:
# 锁住t1表的读操作
mysql> lock table t1 read;
Query OK, 0 rows affected (0.00 sec)
# 可以查看t1表的数据
mysql> select * from t1 where id<3;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lili | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
# 无法进行写操作
mysql> update t1 set name="lala" where id=2;
ERROR 1099 (HY000): Table 't1' was locked with a READ lock and can't be updated
事务B:
# 可以查看t1表的数据
mysql> select * from t1 where id<3;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lili | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
# 对t1表进行写行为,阻塞在原地
mysql> update t1 set name="lala" where id=2;
页级锁
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级锁冲突少,但速度慢。所以取了折中的页级锁(一页为一个block块,16k),一次锁定相邻的一组记录。BDB支持页级锁。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
行级锁按照锁级别分类
行级锁分为共享锁和排他锁两种
与行处理相关的sql语句有:insert、update、delete、select,这四类sql在操作记录行时,可以为行加上锁,但需要知道的是:
对于insert、update、delete(写操作相关)语句,InnoDB会自动给涉及的数据加锁,而且是排他锁(X);
对于普通的select(读操作相关)语句,InnoDB不会加任何锁,需要我们手动自己加,可以加两种类型的锁,如下所示:
共享锁(S):select ... lock in share mode; -- 查出的记录行都会被锁住 排他锁(X):select ... for update; -- 查出的记录行都会被锁住
验证insert、update、delete(写相关操作)是默认加排他锁的
事务A:
# 显示开启,显示提交
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select name from t1 where id=1;
+------+
| name |
+------+
| nana |
+------+
1 row in set (0.00 sec)
事务B:
# 显示开启,显示提交
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select name from t1 where id=1;
+------+
| name |
+------+
| nana |
+------+
1 row in set (0.00 sec)
-- 这里事务B运行update语句,抢到了排他锁(X)
mysql> update t1 set name="NANA" where id=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select name from t1 where id=1;
+------+
| name |
+------+
| NANA |
+------+
1 row in set (0.00 sec)
事务A:
-- 此处的update会阻塞在原地,因为事务B并未提交事务,即尚未释放排他锁(X)
mysql> update t1 set name=concat(name,"_MM") where id=1
事务B:
-- 事务B一旦提交,阻塞状态的事务A操作立即会运行成功
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
事务A:
-- 事务A操作自动会运行成功
mysql> update t1 set name=concat(name,"_MM") where id=1;
Query OK, 1 row affected (14.60 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 此处查询到的结果为NANA_MM
mysql> select name from t1 where id=1;
+---------+
| name |
+---------+
| NANA_MM |
+---------+
1 row in set (0.00 sec)
-- 提交之后,name持久化为NANA_MM
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select name from t1 where id=1;
+---------+
| name |
+---------+
| NANA_MM |
+---------+
1 row in set (0.00 sec)
验证select(读相关操作)默认是没有加任何锁机制的
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁,锁住id<3的所有行
mysql> select * from t1 where id<3 for update;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
事务A:
-- 加排他锁,阻塞在原地
mysql> select * from t1 where id=1 for update;
-- 加共享锁,阻塞在原地
mysql> select * from t1 where id=1 lock in share mode;
# 使用普通select可以正常看到数据内容,证明普通select查询没有任何锁机制
mysql> select name from t1 where id=1;
+------+
| name |
+------+
| nana |
+------+
1 row in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务B
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
共享锁(Share Lock)
共享锁又称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,获准共享锁的事务只能读数据,不能修改数据直到已释放所有共享锁,所以共享锁可以支持并发读。
如果事务A对数据加上共享锁后,则其他事务只能对数据再加共享锁或不加锁(在其他事务里一定不能再加排他锁,但是在事务A自己里面是可以加的),反之亦然。
select ... lock in share mode; -- 查出的记录行都会被锁住
验证共享锁(读锁)只支持其他事务再加共享锁或不加锁,不支持其他事务加排他锁
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加共享锁,锁住id<3的所有行
mysql> select * from t1 where id < 3 lock in share mode;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁,会阻塞在原地
mysql> select * from t1 where id = 1 for update;
-- 加共享锁,可以查出结果,不会阻塞在原地
mysql> select * from t1 where id = 1 lock in share mode;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
+----+------+-----+
1 row in set (0.00 sec)
-- 不加锁,必然也可以查出结果,不会阻塞在原地
mysql> select * from t1 where id = 1;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
+----+------+-----+
1 row in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
排他锁(eXclusive Lock)
排他锁又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再对该行加任何类型的其他他锁(共享锁和排他锁),但是获取排他锁的事务是可以对数据就行读取和修改。
select ... for update; -- 查出的记录行都会被锁住
验证加了排他锁(写锁)不支持其他事务再加排他锁或者共享锁的方式查询数据,但可以直接通过select ...from...(默认不加锁)查询数据。
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁,锁住id<3的所有行
mysql> select * from t1 where id < 3 for update;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 阻塞在原地
mysql> select * from t1 where id =1 for update;
-- 阻塞在原地
mysql> select * from t1 where id =1 lock in share mode;
-- 不加锁,必然也可以查出结果,不会阻塞在原地
mysql> select name from t1 where id = 1;
+------+
| name |
+------+
| nana |
+------+
1 row in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
验证同一个事务可以使用共享锁+排他锁,其他事务无法使用排他锁或者共享锁的方式查询数据,但可以直接通过select查询数据。
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加共享锁,锁住id<3的所有行
mysql> select * from t1 where id < 3 lock in share mode;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
-- 在共享锁的范围内,使用update默认是加了排他锁
mysql> update t1 set name="NANA" where id=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 修改成功,结果为NANA
mysql> select * from t1 where id = 1;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | NANA | 20 |
+----+------+-----+
1 row in set (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁,阻塞在原地,因为事务A刚才对id=1的行加了排他锁
mysql> select * from t1 where id=1 for update;
-- 也无法加共享锁,加上共享锁,同样阻塞在原地
mysql> select * from t1 where id=1 lock in share mode;
-- 不加锁,必然也可以查出结果,不会阻塞在原地
mysql> select * from t1 where id=1 ;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
+----+------+-----+
1 row in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
行级锁的特性
在Mysql中,行级锁并不是直接锁记录,而是锁索引。InnoDB 行锁是通过给索引项加锁实现的,而索引分为主键索引和非主键索引两种:
- 如果一条sql 语句命中了主键索引,Mysql 就会锁定这条语句命中的主键索引行(或称聚簇索引);
- 如果一条语句命中了非主键索引(或称辅助索引),MySQL会先锁定该非主键索引(辅助索引的叶子节点存放的是[非主键索引:主键索引]),再通过回表操作锁定相关的主键索引行。
- 如果没有命中索引,InnoDB 会通过隐藏的聚簇索引来对记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表级锁一样。
在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。
1. 在不通过索引条件查询的时候,InnoDB 的效果就相当于表锁。 2. 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行。 另外,不论是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。 3. 由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁。 所以即便你的sql语句访问的是不同的字段名,但如果命中的是相同的被锁住的索引键,也还是会出现锁冲突的。
- 即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的。
如果MySQL认为全表扫描的效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将锁住所有行,相当于表锁。
因此,在分析锁冲突时, 别忘了检查SQL的执行计划(explain),以确认是否真正使用了索引。
# 创建索引表
create table t1(
id int primary key auto_increment,
name varchar(20) not null,
age int(3) unsigned not null default 20
);
insert into t1(name) values
('nana'),('lala'),('haha'),
('xixi'),('dudu'),('xiexie'),
('jiujiu'),('牛牛'),('局局'),
('丫丫'),('猪猪'),('珠珠'),
('竹竹'),('噔噔'),('流川枫'),
('樱木花道'),('三井寿'),('宫田');
mysql> update t1 set age=16 where id=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set age=18 where id in (2,3,4);
Query OK, 3 rows affected (0.01 sec)
Rows matched: 3 Changed: 3 Warnings: 0
mysql> select * from t1;
+----+--------------+-----+
| id | name | age |
+----+--------------+-----+
| 1 | nana | 16 |
| 2 | lala | 18 |
| 3 | haha | 18 |
| 4 | xixi | 18 |
| 5 | dudu | 20 |
| 6 | xiexie | 20 |
| 7 | jiujiu | 20 |
| 8 | 牛牛 | 20 |
| 9 | 局局 | 20 |
| 10 | 丫丫 | 20 |
| 11 | 猪猪 | 20 |
| 12 | 珠珠 | 20 |
| 13 | 竹竹 | 20 |
| 14 | 噔噔 | 20 |
| 15 | 流川枫 | 20 |
| 16 | 樱木花道 | 20 |
| 17 | 三井寿 | 20 |
| 18 | 宫田 | 20 |
+----+--------------+-----+
18 rows in set (0.00 sec)
验证给区分度不高的字段加索引,索引是无法命中的。
-- age字段没有索引的情况下的查询计划,条件为age = 20
mysql> explain select * from t1 where age=20;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t1 | ALL | NULL | NULL | NULL | NULL | 18 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
-- age字段没有索引的情况下的查询计划,条件为age = 18
mysql> explain select * from t1 where age=18;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t1 | ALL | NULL | NULL | NULL | NULL | 18 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
-- 为age字段添加索引
mysql> create index xxx on t1(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
# 此时满足age=20的行太多,即便是为age字段加了索引也是无法命中的。key字段为NULL,证明虽然建立了索引,但压根没用上。
mysql> explain select * from t1 where age=20;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t1 | ALL | xxx | NULL | NULL | NULL | 18 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
# 查看计划,key字段为xxx,命中了索引,因为age=18的行总共才3行,其实我们通常就应该给那些区分度高的字段加索引。
mysql> explain select * from t1 where age=18;
+----+-------------+-------+------+---------------+------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------+------+-------+
| 1 | SIMPLE | t1 | ref | xxx | xxx | 4 | const | 3 | NULL |
+----+-------------+-------+------+---------------+------+---------+-------+------+-------+
1 row in set (0.00 sec)
验证未命中索引则锁表
事务A:
-- 因为条件age=20无法命中索引,所以会锁住整张表。
mysql> select * from t1 where age=20 for update;
+----+--------------+-----+
| id | name | age |
+----+--------------+-----+
| 5 | dudu | 20 |
| 6 | xiexie | 20 |
| 7 | jiujiu | 20 |
| 8 | 牛牛 | 20 |
| 9 | 局局 | 20 |
| 10 | 丫丫 | 20 |
| 11 | 猪猪 | 20 |
| 12 | 珠珠 | 20 |
| 13 | 竹竹 | 20 |
| 14 | 噔噔 | 20 |
| 15 | 流川枫 | 20 |
| 16 | 樱木花道 | 20 |
| 17 | 三井寿 | 20 |
| 18 | 宫田 | 20 |
+----+--------------+-----+
14 rows in set (0.00 sec)
事务B:
-- 阻塞
mysql> select * from t1 where age=16 for update;
-- 阻塞
mysql> select * from t1 where age=18 for update;
-- 阻塞
mysql> select * from t1 where id>4 for update;
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
验证命中索引则锁行
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 因为条件age=18命中了索引,所以会锁住行而不是表
mysql> select * from t1 where age=18 for update;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 2 | lala | 18 |
| 3 | haha | 18 |
| 4 | xixi | 18 |
+----+------+-----+
3 rows in set (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 不阻塞
mysql> select * from t1 where age=16 for update;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 16 |
+----+------+-----+
1 row in set (0.00 sec)
-- 阻塞,因为事务A里锁住了age=18的行
mysql> select * from t1 where age=18 for update;
-- 阻塞,???,不是说只锁age=18的行吗!!!
# Next-Key Lock
mysql> select * from t1 where age = 20 for update;
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
InnoDB行锁的三种算法
InnoDB的行锁有三种算法,都属于排他锁:
- record lock:单个行记录上的锁
- gap lock:间隙锁,锁带一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的的情况。
- next-key lock:等于record lock结合gap lock,也就说next-key lock既锁定记录本身也锁定一个范围,特别需要注意的是,InnoDB存储引擎还会对辅助索引下一个键值加上gap lock。
Next-Key Lock算法
对于行查询,innodb默认采用的都是Next-Key Lock算法,主要目的是解决幻读的问题,以满足相关隔离级别以及恢复和复制的需要。
# 创建普通索引表格
create table t2(
id int,
key idx_id(id)
)engine=innodb;
insert t2 values(1),(5),(7),(11);
-- key字段为idx_id,命中索引,即会采用行锁而不是表锁
mysql> explain select * from t2 where id=7 for update;
+----+-------------+-------+------+---------------+--------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+--------+---------+-------+------+-------------+
| 1 | SIMPLE | t2 | ref | idx_id | idx_id | 5 | const | 1 | Using index |
+----+-------------+-------+------+---------------+--------+---------+-------+------+-------------+
1 row in set (0.00 sec)
验证命中了非唯一索引,无论是等值查询还是范围查询,innodb采用算法默认的都是next-key lock算法
mysql> select * from t2;
+------+
| id |
+------+
| 1 |
| 5 |
| 7 |
| 11 |
+------+
4 rows in set (0.00 sec)
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁
# 1. 上述语句命中了索引,所以加的是行锁
# 2. InnoDB对于行的查询都是采用了Next-Key Lock的算法,锁定的不是单个值,而是一个范围(GAP)
# 表记录的索引值为1,5,7,11,其记录的GAP区间如下:
# (-∞,1],(1,5],(5,7],(7,11],(11,+∞]
# 因为记录行默认就是按照主键自增的,所以是一个左开右闭的区间
# 其中上述查询条件id=7处于区间(5,7]中,所以Next-Key lock会锁定该区间的记录,但是还没完
# 3. InnoDB存储引擎还会对辅助索引下一个键值加上gap lock。
# 区间(5,7]的下一个Gap是(7,11],所以(7,11]也会被锁定
# Next-key算法对非唯一索引的下一个区间最后一个值11是取不到的,因此11并不会被锁定。
# 综上所述,最终确定5-10之间的值都会被锁定。
mysql> select * from t2 where id=7 for update;
# select * from t2 where 5<id and id<11 for update; 这条sql语句实验效果同上一样
+------+
| id |
+------+
| 7 |
+------+
1 row in set (0.00 sec)
事务B:
-- 以下sql全都会阻塞在原地
# Next-key算法对非唯一索引的下一个区间最后一个值11是取不到的,因此11并不会被锁定。
mysql> insert t2 values(5);
mysql> insert t2 values(6);
mysql> insert t2 values(7);
mysql> insert t2 values(8);
mysql> insert t2 values(9);
mysql> insert t2 values(10);
-- 以下sql均执行成功
mysql> insert t2 values(11);
mysql> insert t2 values(1);
mysql> insert t2 values(2);
mysql> insert t2 values(3);
mysql> insert t2 values(4);
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
Record Lock算法
InnoDB对于行的查询都是采用了Next-Key Lock的算法,锁定的不是单个值,而是一个范围。
但是当查询的索引含有unique(唯一)属性的时候,next-key lock会进行优化,将其降级为record lock,即仅锁住索引本身,不是范围。
# 创建主键索引表格
mysql> create table t3(a int primary key)engine =innodb;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t3 values(1),(3),(5),(8),(11);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from t3;
+----+
| a |
+----+
| 1 |
| 3 |
| 5 |
| 8 |
| 11 |
+----+
5 rows in set (0.00 sec)
验证查询的索引含有unique属性的时候,并且是等值查询,Innodb默认使用record lock算法。
事务A:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁
mysql> select * from t3 where a = 8 for update;
+---+
| a |
+---+
| 8 |
+---+
1 row in set (0.00 sec)
事务B:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
# 当查询的索引含有唯一属性的时候,Next-Key Lock会进行优化,将其降级为Record Lock,即仅锁住索引本身,不是范围。
mysql> insert into t3 values(6);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(7);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(9);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(10);
Query OK, 1 row affected (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
验证查询的索引含有unique属性的时候,并且是范围查询,Innodb默认使用Next-key lock算法。
事务A:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
# 区间如下:
# (-∞,1],(1,3],(3,5],(5,8],(8,11],(11,+∞]
# InnoDB存储引擎还会对唯一索引下一个键值加上gap lock。
# 区间(5,8]的下一个Gap是(8,11],所以(8,11]也会被锁定。
# Next-key算法对唯一索引第一个区间的第一个值5是取不到的,因此5并不会被锁定。
mysql> select * from t3 where 5<a and a<11 for update;
+---+
| a |
+---+
| 8 |
+---+
1 row in set (0.00 sec)
事务B:
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
-- 以下sql全都会阻塞在原地
# Next-key算法对唯一索引第一个区间的第一个值5是取不到的,因此5并不会被锁定。
mysql> insert into t3 values(6);
mysql> insert into t3 values(7);
mysql> insert into t3 values(8);
mysql> insert into t3 values(9);
mysql> insert into t3 values(10);
mysql> insert into t3 values(11);
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
Gap Lock锁算法
间隙锁,锁定一个范围,但不包括记录本身。
通过主键或则唯一索引来锁定不存在的值,也会产生GAP锁定
mysql> select * from t3;
+----+
| a |
+----+
| 1 |
| 3 |
| 5 |
| 8 |
| 11 |
+----+
5 rows in set (0.00 sec)
事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加排他锁
# 相当于select * from t3 where a>11 for update;
# 区间为12到正无穷之间的值都会被锁定
mysql> select * from t3 where a = 15 for update;
Empty set (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 阻塞
mysql> insert into t3 values(12);
-- 阻塞
mysql> insert into t3 values(14);
-- 阻塞
mysql> insert into t3 values(15);
-- 阻塞
mysql> insert into t3 values(16);
mysql> insert into t3 values(10);
Query OK, 1 row affected (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
总结
如果没有命中索引,无论你筛选出哪一行,都会将整张表锁住
如果命中了非唯一索引,并且是等值查询,会锁行还有间隙
如果命中了非唯一索引,但是是范围查询,会锁行还有间隙
如果命中了唯一索引,并且是等值查询,只会锁定行
如果命中了唯一索引,并且是范围查询,会所行还有间隙
- Next-key Lock算法对唯一索引第一个区间的第一个值取不到的,因此第一个区间的第一个值不会锁定。
- Next-key Lock算法对非唯一索引的下一个区间最后一个值是取不到的,因此第二个区间的最后一个值不会被锁定。
死锁现象

事务A:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加共享锁,锁住id<3的所有行
mysql> select * from t1 where id<3 lock in share mode;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
事务B:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
-- 加共享锁,锁住id<3的所有行
mysql> select * from t1 where id < 3 lock in share mode;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 1 | nana | 20 |
| 2 | lala | 20 |
+----+------+-----+
2 rows in set (0.00 sec)
事务A:
-- 在共享锁的范围内,使用update默认是加了排他锁,阻塞在原地
mysql> update t1 set name="NANA" where id=1;
事务B:
# 出现死锁现象,事务B报错。innodb存储引擎默认结束了事务B,并且释放了事务B的锁
# 因此,事务A上一步直接执行成功了。
mysql> update t1 set name="NANA" where id=1;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
事务A:
mysql> rollback;
Query OK, 0 rows affected (0.01 sec)
行级锁按照锁使用方式分类
悲观锁与乐观锁相当于锁的使用方式,考虑到效率问题,现在主要是使用乐观锁。
悲观锁
当我们要对一个数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加排他锁以防止并发。
- 悲观锁的优点:保证数据安全
- 悲观锁缺点:降低了数据库的使用效率
乐观锁
乐观锁相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测。如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
事务隔离机制
mvcc多版本并发控制
在MVCC并发控制中,读操作可以分成两类:快照读与当前读。
快照读
简单的select操作,属于快照读,不加锁。
select * from table where id=1;当前读
特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
select * from table where id=1 lock in share mode; select * from table where id=1 for update; --增删改(写操作)默认加排他锁 insert into table values(2,"nana"); update table set name="nana" where id=2; delete from table where id=1;以上所有的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁(共享锁)外,其他的操作,都加的是X锁 (排他锁)。