一 .爬虫
爬虫,向网站发送请求,获取资源后分析 并提取有用的数据 的程序
爬虫本质就是:本质就是cosplay,将爬虫模拟成各种【USER_AGENT】浏览器,甚至还模拟成别人【ip代理】的浏览器。自动提取网页的程序。
二.流程

#1、发起请求 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体等 #2、获取响应内容 如果服务器能正常响应,则会得到一个Response Response包含:html,json,图片,视频等 #3、解析内容 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等 解析json数据:json模块 解析二进制数据:以b的方式写入文件 #4、保存数据 数据库 文件
三 请求与响应
#Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server) #Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等) #ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四 request
#1、请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k4=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后
#2、请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
#3、请求头
User-agent:请求头中如果没有user-agent客户端配置,
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息
一般做爬虫都会加上请求头
#4、请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post


from urllib.parse import urlencode import requests headers={ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Cookie':'BIDUPSID=A477AA56C3F17BC59A75C1EC2457CE9D; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=AD7BBA497F7F14FB30E8AA7E2BBAD53C:FG=1; PSTM=1510744992; BD_HOME=0; H_PS_PSSID=1420_21096_24880_20927; BD_UPN=12314753', 'Host':'www.baidu.com', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3253.3 Safari/537.36' } # response=requests.get('https://www.baidu.com/s?'+urlencode({'wd':'啤酒'}),headers=headers) response = requests.get('https://www.baidu.com/s',params={'wd':'啤酒'},headers=headers) with open('e.html','w',encoding='utf8') as f: f.write(response.text) # print(response.text)
五 response
#1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误
#2、respone header
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来
#3、preview就是网页源代码
最主要的部分,包含了请求资源的内容
如网页html,图片
二进制数据等
六.总结
#1、总结爬虫流程:
爬取--->解析--->存储
#2、爬虫所需工具:
请求库:requests,selenium
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongodb,Redis
#3、爬虫常用框架:
scrapy
2.HTTP概述
HTTP(hypertext transport protocol),即超文本传输协议。这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式。其实我们要学习的就是这个两个格式!客户端发送给服务器的格式叫“请求协议”;服务器发送给客户端的格式叫“响应协议”。
特点:
- HTTP叫超文本传输协议,基于请求/响应模式的!
- HTTP是无状态协议。
URL:统一资源定位符,就是一个网址:协议名://域名:端口/路径,例如:http://www.baidu.com
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据,准确理解它的含义对爬虫学习有很大帮助。
3.状态码
响应头对浏览器来说很重要,它说明了响应的真正含义。例如200表示响应成功了,302表示重定向,这说明浏览器需要再发一个新的请求。
- 200:请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
- 404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;
- 500:请求资源找到了,但服务器内部出现了错误;
- 302:重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location,它指定了新请求的URL地址;
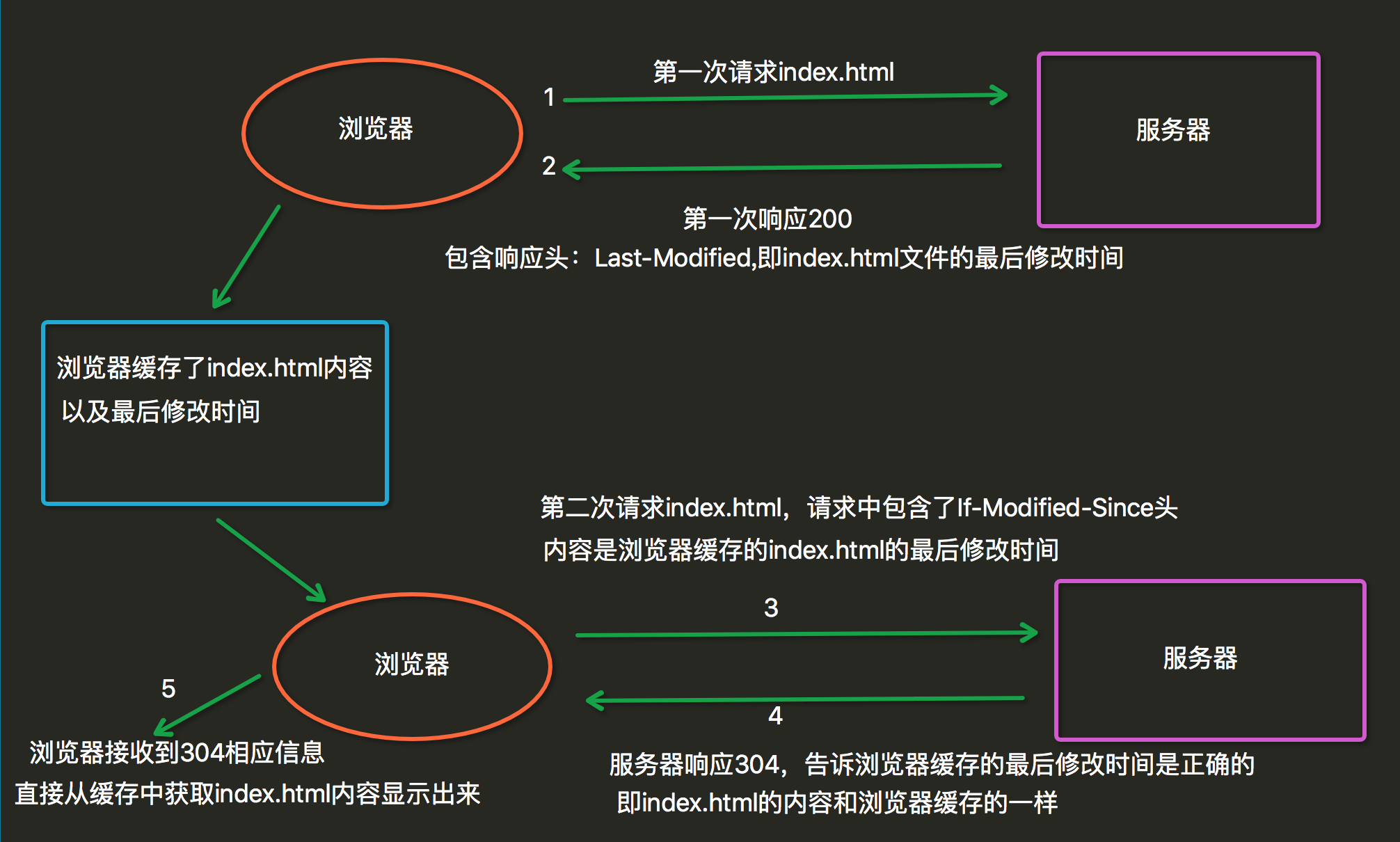
- 304:
当用户第一次请求index.html时,服务器会添加一个名为Last-Modified响应头,这个头说明了 index.html的最后修改时间,浏览器会把index.html内容,以及最后响应时间缓存下来。当用户第 二次请求index.html时,在请求中包含一个名为If-Modified-Since请求头,它的值就是第一次请 求时服务器通过Last-Modified响应头发送给浏览器的值,即index.html最后的修改时间, If-Modified-Since请求头就是在告诉服务器,我这里浏览器缓存的index.html最后修改时间是这个, 您看看现在的index.html最后修改时间是不是这个,如果还是,那么您就不用再响应这个index.html 内容了,我会把缓存的内容直接显示出来。而服务器端会获取If-Modified-Since值,与index.html 的当前最后修改时间比对,如果相同,服务器会发响应码304,表示index.html与浏览器上次缓存的相 同,无需再次发送,浏览器可以显示自己的缓存页面,如果比对不同,那么说明index.html已经做了修 改,服务器会响应200。
4.浏览网页
浏览网页的过程,用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析,发动给用户的浏览器HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的内容。
因此,用户看到到的网页实质是由HTML代码构成的,爬虫爬的便是这些内容,经过分析和过滤这些HTML代码,实现对图片,文字等资源的获取。