1. 原理
通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
2. b+数性质
索引字段尽可能小
索引的最左匹配(从左到右查找)
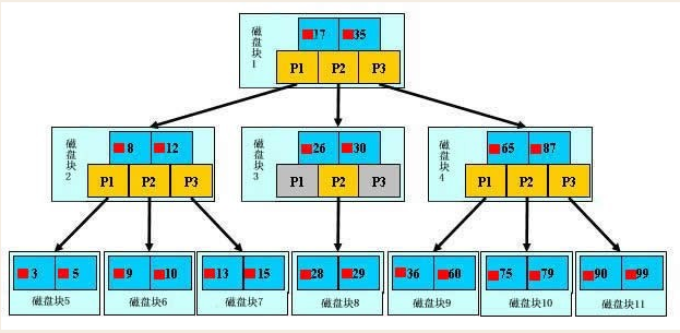
3. 索引分类
1.普通索引index :加速查找
2.唯一索引
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3.联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引 -index(id,name):联合普通索引
4.全文索引fulltext :
用于搜索很长一篇文章的时候,效果最好。
5.空间索引spatial :
了解就好,几乎不用
4. 索引的两大类型hash与btree
hash类型的索引:查询单条快,范围查询慢 btree类型的索引
b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引
5. 正确使用索引
覆盖索引 select的字段为*,除了id以外还需要其他字段,这就意味着,我们通过索引结构取到id还不够, 还需要利用该id再去找到该id所在行的其他字段值
最左前缀匹配原则
尽量选择区分度高的列作为索引(不重复度高)
6. 无法命中情况
like '%at'(后百分号可以)
使用函数
or(当or条件中有未建立索引的列才失效)
类型不一致
!=(如果是主键,则还是会走索引)
排序条件为索引,则select字段必须也是索引字段,否则无法命中