基于Merlin的英文语音合成实战
Installation
Merlin不是一个完整的TTS系统,它只是提供了TTS核心的声学建模模块(声学和语音特征归一化,神经网络声学模型训练和生成)。前端文本处理(frontend)和声码器(vocoder)需要其他软件辅助。
Merlin uses the following dependencies:
- numpy, scipy
- matplotlib
- bandmat
- theano
- tensorflow (optional, required if you use tensorflow models)
- sklearn, keras, h5py (optional, required if you use keras models)
1.download Merlin
2.install辅助软件
(frontend:festival,festvox,hts,htk;vocoder:WORLD,SPTK)
merlin封装了相关安装脚本,在merlin/tools文件夹下
其中htk 需要注册登陆后才可下载,建议在web端下载到本地[HTK,HDecode,HTS PATCH]三个文件,注释掉compile_htk.sh中Row 3-9,25-34
cd merlin/
bash tools/compile_tools.sh #SPTK, WORLD
bash tools/compile_other_speech_tools.sh #speech tools, festival and festvox
bash tools/compile_htk.sh #HTK
此处的小坑在HTK的安装,顺利安装就继续, else参考最后遇见的问题。
3.模型训练软件
merlin默认调用theano,也支持tensorflow和keras,NN工具的安装不赘述。
运行merlin demo
sh merlin/egs/slt_arctic/s1/run_full_voice.sh
demo使用的是CMU ARCTIC数据库中US English女性(slt_arctic_full_data.zip) 播音员的1132条文本和语音,包含了16kHzd waveform语音,全部的labeling由festvox或hts的labeling脚本完成。
由于Merlin没有自带frontend,所以demo中直接使用的事先经过frontend转换的label文件作为输入数据。通过脚本文件01_setup.sh在当前文件夹下创建experiments和experiments/slt_arctic_full,将下载解压后的数据分别放到以下目录,分别用于duration model和acoustic model的训练。
experiments/slt_arctic_full/duration_model
experiments/slt_arctic_full/acoustic_model
给出两张图,一张是merlin的tts流程图,另外一张是source code的代码流程。
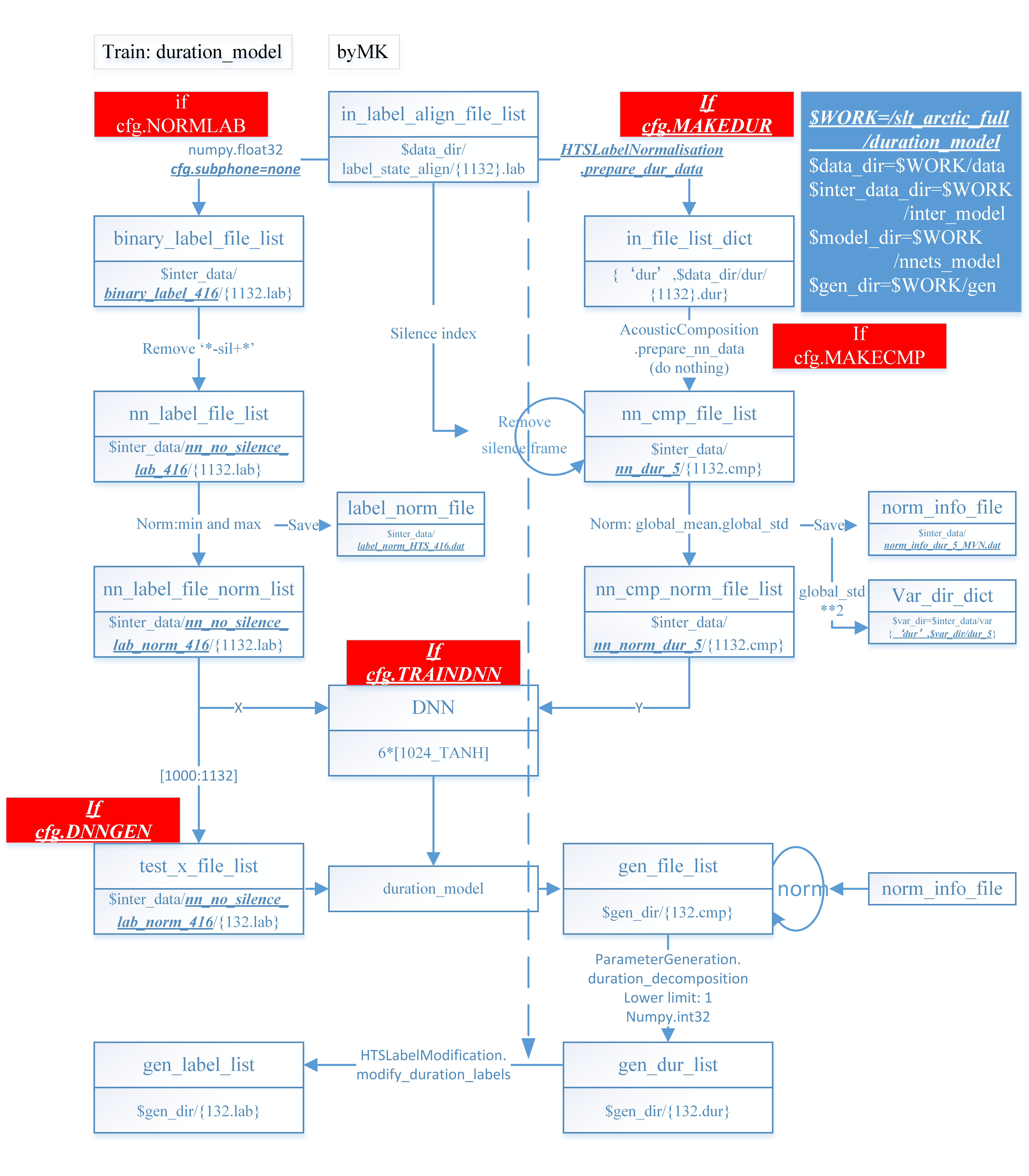
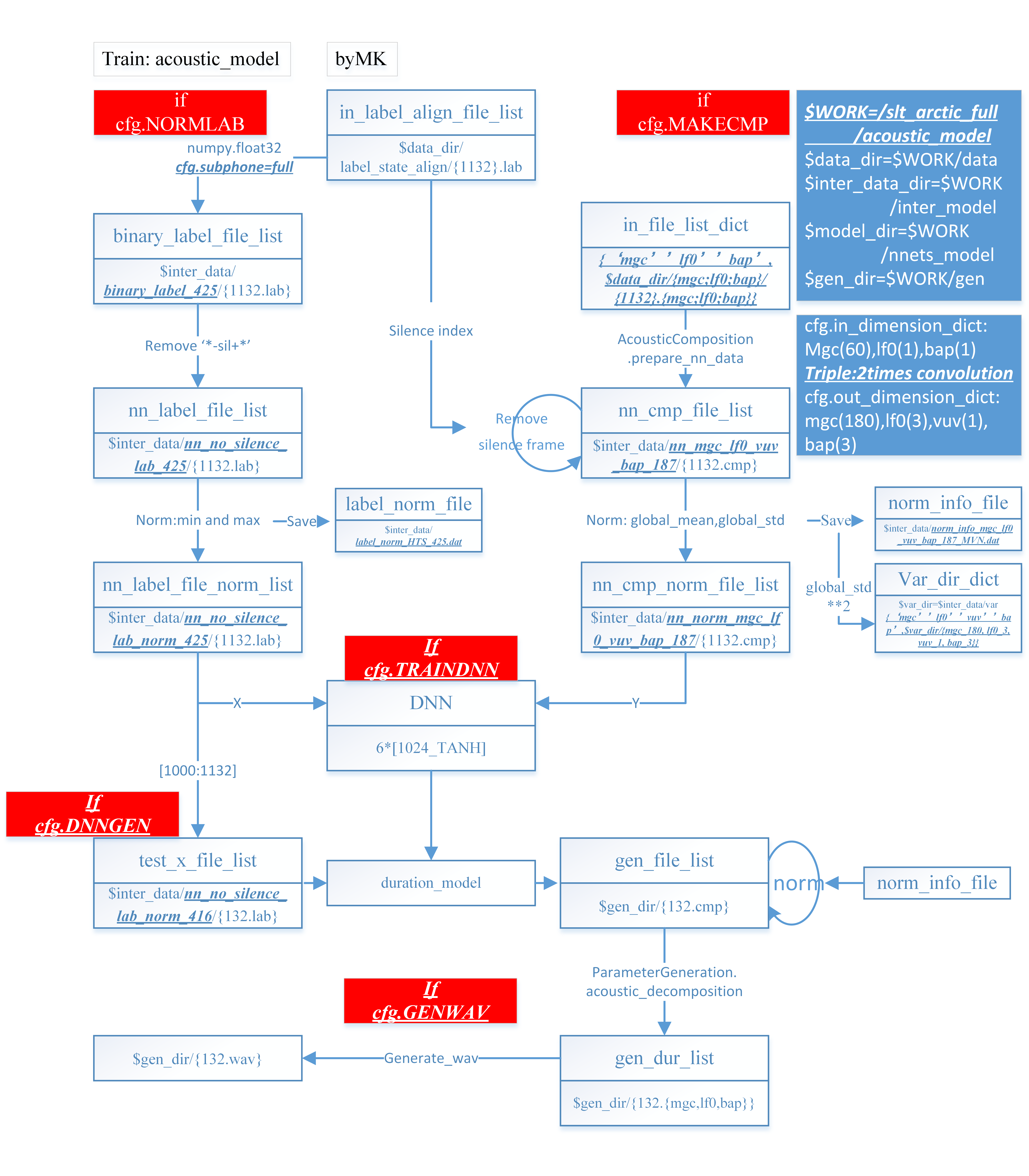
source code中只展示了train model流程,synthesis与之相似,只是减少了几个part。
cfg.NORMLAB: True
cfg.DNNGEN: True
cfg.GENWAV : True
synthesis只有一下三个cfg,在duration_step生成的结果送进acoustic_step,需要注意的一点是在cfg.NORMLAB时不去除静音直接norm。
构建自己的demo
当只有txt和对应的wav时,需要自己生成alignment label,acoustic label,用于train model. 已经能够跑通全部流程的work demo[https://github.com/zhanxiage1994/merlin_workdemo]。
对于英文语音合成,merlin需要首先通过duration模型确定音素的发音时间,然后根据声学模型合成完整的语音。英文语音合成分成训练和合成阶段。
训练阶段:
1.文本分析---对应frontend
2.音频特征参数---对应vocoder
3.HMM模型聚类---对应Question file
4.NN模型训练---对应NN model
合成阶段:
1.文本分析---对应frontend
2.NN解码---对应NN模型训练
3.语音合成---对应vocoder
前端frontend
语音合成前端(frontend)实际上是一个文本分析器,属于 NLP(Natural Language Processing)的研究范畴,其目的是
- 对输入文本在语言层、语法层、语义层的分析
- 将输入的文本转换成层次化的语音学表征
- 包括读音、分词、短语边界、轻重读等
- 上下文特征(context feature)
1.Label的分类
在Merlin中,Label有两种类别,分别是
- state align(使用HTK来生成,以发音状态为单位的label文件,一个音素由几个发音状态组成)
- phoneme align(使用Festvox来生成,以音素为单位的label文件)
2.txt to utt
Festival 使用了英文词典,语言规范等文件,将txt转换成包含了文本特征(如上下文,韵律等信息)的utt文件
3.utt to label
在获得utt的基础上,需要对每个音素的上下文信息,韵律信息进行更为细致的整理。label文件的格式请参见:lab_format.pdf
cd merlin/misc/scripts/alignment/state_align
./setup.sh
./run_aligner.sh
#your labels ready in: label_state_align
声码器Vocoder
Merlin中自带的vocoder工具有以下三类:Straight,WORLD,WORLD_v2。
这三类工具可以在Merlin的文件目录下找到,具体的路径如下merlin/misc/scripts/vocoder。
声码特征:
1.MGC特征:通过语音提取的MFCC特征由于维度太高,并不适合直接放到网络上进行训练,所以就出现了MGC特征,将提取到的MFCC特征降维(在这三个声码器中MFCC都被统一将低到60维),以这60维度的数据进行训练就形成了我们所说的MGC特征。
2.BAP特征: Band Aperiodicity的缩写
3.LF0:LF0是语音的基频特征
Straight
音频文件通过Straight声码器产生的是:60维的MGC特征,25维的BAP特征,以及1维的LF0特征。
通过 STRAIGHT 合成器提取的谱参数具有独特 特征(维数较高), 所以它不能直接用于 HTS 系统中, 需要使用 SPTK 工具将其特征参数降维, 转换为 HTS 训练中可用的 mgc(Mel-generalized cepstral)参数, 即, 就是由 STRAIGHT 频谱计算得到 mgc 频谱参数, 最后 利用原 STRAIGHT 合成器进行语音合成
World
音频文件通过World声码器产生的是:60维的MGC特征,可变维度的BAP特征以及1维的LF0特征,对于16kHz采样的音频信号,BAP的维度为1,对于48kHz采样的音频信号,BAP的维度为5。
World_v 2
音频文件通过World_v2声码器产生的是:60维的MGC特征,5维的BAP特征以及1维的LF0特征,现World_v2版本还处在一个测试的阶段,存在着转换过程不稳定这一类的问题。
cd merlin/misc/scripts/vocoder/world
bash extract_features_for_merlin.sh <path_to_merlin_dir> <path_to_wav_dir> <path_to_feat_dir> <sampling frequency>
训练模型——Duration和声学模型
语音合成和语音识别是一个相反的过程, 在语音 识别中, 给定的是一个 HMM 模型和观测序列(也就是 特征参数, 是从输入语音中提取得到), 要计算的是这 些观测序列对应的最有可能的音节序列, 然后根据语 法信息得到识别的文本. 而在合成系统中, 给定的是 HMM 模型和音节序列(经过文本分析得到的结果), 要计算的是这些音节序列对应的观测序列, 也就是特征参数.
HTS的训练部分的作用就是由最初的原始语料库经过处理和模型训练后得到这些训练语料的HMM模型。建模方式的选择首先是状态数的选择,因为语音的时序特性,一个模型的状态数量将影响每个状态持续的长短,一般根据基元确定。音素或半音节的基元,一般采用5状态的HMM;音节的基元一般采用10个状态。在实际的建模中,为了模型的简化,可以将HMM中的转移矩阵用一个时长模型(dur)替代,构成半隐马尔可夫模型HSMM hidden semi-Markov Model。用多空间概率分布对清浊音段进行联合建模,可以取得很好的效果。HTS的合成部分相当于训练部分的逆过程,作用在于由已经训练完成的HMM在输入文本的指导下生成参数,最终生成语音波形。具体的流程是:
通过一定的语法规则、语言学的规律得到合成所需的上下文信息,标注在合成label中。
待合成的label经过训练部分得到的决策树决策,得到语境最相近的叶结点HMM就是模型的决策。
由决策出来的模型解算出合成的基频、频谱参数。根据时长的模型得到各个状态的帧数,由基频、频谱模型的均值和方差算出在相应状态的持续时长帧数内的各维参数数值,结合动态特征,最终解算出合成参数。
由解算出的参数构建源-滤波器模型,合成语音。源的选取如上文所述:对于有基频段,用基频对应的单一频率脉冲序列作为激励;对于无基频段,用高斯白噪声作为激励
遇见的问题
1.HTK安装
致命错误:X11/Xlib.h:没有那个文件或目录

按照网上所说,是缺少Libx11-dev这个库,安装库文件后重试shell脚本。
不成功的话会报
致命错误:X11/X.h 没有那个文件或目录
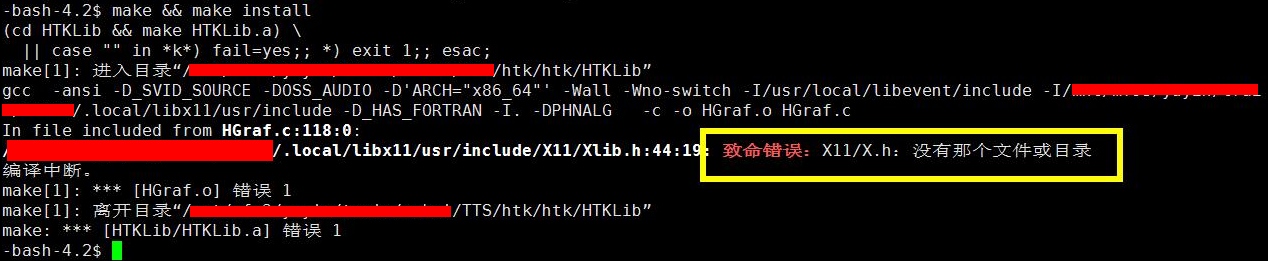
此时需要修改脚本代码,compile_htk.sh的Row47
./configure --prefix=$PWD/build --without-x --disable-hslab;
禁止一些启动。
2.alignment label生成
vim merlin/egs/slt_arctic/s1/merlin_synthesis.sh
./scripts/prepare_labels_from_txt.sh $global_config_file
这一步也会生成*.lab文件,仅仅是对txt文件做了文本分析,没有于waveform文件做alignment,因此是不能用于train model的输入。
Reference
http://blog.csdn.net/lujian1989/article/category/6735359
http://www.speech.zone/exercises/
https://github.com/Jackiexiao/merlin/blob/93390c382d8033dd393b8d12bf35f1abcd089c7b/manual/merlin_statistical_parametric_speech_synthesis_chinese.md#merlin的安装与运行
https://github.com/CSTR-Edinburgh/merlin
http://blog.csdn.net/u010157717/article/details/60189132
http://ssw9.net/papers/ssw9_PS2-13_Wu.pdf
http://blog.csdn.net/lujian1989/article/details/56008786
https://github.com/Jackiexiao/merlin/blob/master/manual/Create_your_own_label_Using_Festival.md