分布式系统
身为二十一世纪的一名程序员,没听说过分布式系统就显得自己好像没有女票一样尴尬。无论是出去面试跟面试官吹水,还是在工作中和同事吹水,分布式系统永远是你显得高人一等的筹码。分布式系统已经诞生了好几十年,说起来比我们八零后程序员好要老成,随着现代互联网的崛起,对于系统在性能,可靠性上的要求大大提高。
分布式系统的定义其实很简单,也很抽象:任何由处于不同物理位置的多个进程提供相同服务的系统都可以称之为分布式系统,退一万步讲,同一台服务器上的不同进程也可以组成分布式系统
分布式系统的首要目标是提高系统的整体性能,但不仅限于吞吐量,可靠性,响应时间,数据一致性等,其中提高性能指标是最重要的。如果最终设计出来的分布式系统占用了更多的资源却还比不上单机的性能,那这个分布式系统是失败的,理论上没有存在的价值
一个分布式系统的整体性能提高并不是单单依靠扩展来实现,提高单机的处理性能仍然很重要,一个把单机性能发挥到极致的分布式系统,在同等性能的需求下,采用的资源要远远小于其他系统。
分布式系统痛点
一个好的分布式系统在性能方面要远超单机系统,但是在数据行为方面要表现的和单机系统一样优秀,其中包括数据的一致性,硬件的故障发生率,网络的不稳定性等。
无论是单机系统还是分布式系统都存在无法回避并且无法彻底去除的风险,比如:硬盘发生故障,网络发生瘫痪,光纤被挖.....分布式系统随着节点的增加,把这些故障的发生率也随之增大,所以分布式系统其中一个目标是要尽量降低这些风险,也就是所谓的容错性。
既要快还要不出错,这在“伦理”上是冲突的。就像我们平时说的分布式锁,如果要保证对一个资源的修改不会发生线程安全问题,就要付出降低性能的代价。至于性能和容错性怎样选择,还需要具体到每个业务场景中,比如支付场景中,数据的正确性可能要比性能指标更重要,而那些日志型数据,比如用户的登录日志,这些数据的最大特点就是允许小部分丢失,在这样的日志系统设计中,可能性能指标要大于容错性。
目前烂大街的CAP原则的讲解,是针对分布式系统的一个抽象理论,包括之后BASE理论,也是针对分布式系统的一种指导方案。
设计分布式系统
分布式系统的特性就决定了它自出生之日起,就有多个节点如何协同工作的难题。就像一个团队,如果让这个团队有条不紊的工作本来就是个难题。一堆节点为了完成同样的任务,注定需要一个规范方圆的规则。就目前已知的方案中,主要有中心化和去中心化两种解决方案
中心化
中心化的分布式设计理念是目前主流的方案,在中心化的设计方案中,节点是有角色区分的:Leader节点和Work节点,即:领导和干活的。就和现实中类似,leader只负责分发任务和监督,Work节点只负责领取任务干活,多说一句,这里Work节点领取任务,当然从通信的角度来说,又可以分为push和pull(推和拉)方式。推方式是指,leader节点主动将任务分发给Work节点,拉方式是指:Work节点主动去申请任务。至于push和pull的优缺点,不作为今天的主题展开讨论。
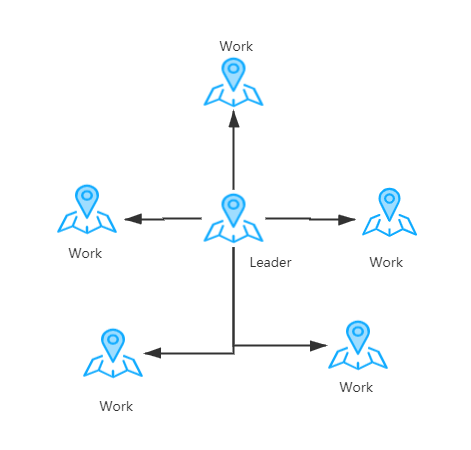
在任何系统中,都无可避免的需要考虑节点down掉的问题,分布式系统也一样。在中心化分布式设计中,leader和Work也一样都存在down掉的可能性。如果leader掉的话,整个系统都陷入瘫痪,按照最简单的设计思路,leader节点需要一个从节点或者备用节点,在主节点down掉之后,从主节点或者备用主节点可以手动或者自动实现leader节点服务。至于一个Work节点down掉,一般不会使整个系统陷入瘫痪,除非全部Work节点同时down掉。一个Work节点down掉,但是会影响这个节点当前正在执行的任务,所以在必要的条件下可以设计成任务需要Ack才好,即:一个任务的完成需要确认,如果长时间没有确认,leader会发起重新分配任务的操作。
说到leader的问题,现在目前大多数分布式系统都具备了自动选举leader的功能,这还要感谢paxos,raft等选举算法。在leader不可用的时候,这些系统会自动根据节点情况选举出新的leader节点来继续提供服务,这大大提高了系统可用性。
在所有的中心化设计中,数据的写操作都发生在leader节点,这在某种程度上类似于单机系统,所以这种中心化设计并不适合那些大量写的操作。
去中心化
在去中心化分布式系统设计中,节点类型并不区分Leader和Work,所有节点都是相等的。所以任何一个节点down掉都不会导致整个系统瘫痪,这是它的优势。但是获取系统中每个节点的信息却比中心化设计要难很多,在中心化设计中,leader节点存储着系统中所有的节点信息,并可以实时把这些信息同步到其他节点,同时可以利用相应算法来达到一致性的要求。去中心化的设计中,每个节点只能依靠和其他节点不断通信来获取整个系统的节点信息,这在技术难度上要比中心化高出很多。
在网络中,网络是不可靠的。恰恰是这个原因,又加大了每个节点互相通信的难度。在极限情况下,去中心化的设计方案会出现多个小范围的“团伙”,这就是所说的脑裂。比如:现在一个由10个节点组成的分布式系统,有可能由于网络原因会划分为两个5节点互相通信的两个“团伙”
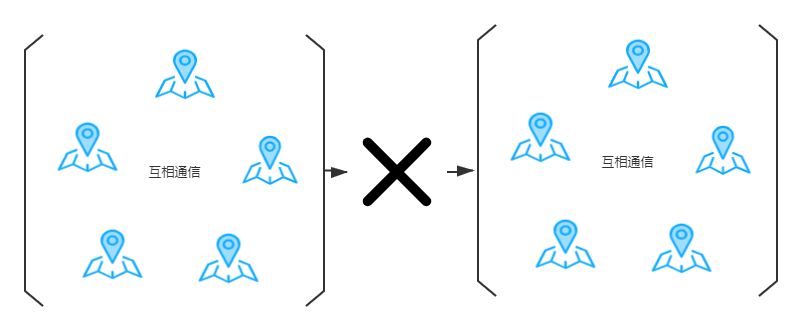
如果出现脑裂的情况,目前主流的解决方案和数据库死锁的处理情况类似,自爆一个对系统影响比较小的。
完全中心化和去中心化的系统并不常见,反而现在慢慢出现的是二者的搭配者,表面看似去中心化,设计理念却是中心化的思路,在这种架构下,leader是程序根据某种算法选举出来的,而且在系统leader发生故障的时候,系统会自动重新选举leader节点。
写在最后
对于每个系统来说,可靠性是它要实现的主要目标之一,尤其是分布式系统。在网络通信,硬件设备等条件都非100%可靠的情况下,如何提高分布式系统的可用性是一个很深的话题。就算是国内顶尖的BAT等大厂,也没有一个系统能达到100%的可用性,4个9的可用性已经是很巅峰了。
分布式系统本质上是多个节点通过网络IO组成的,其中夹杂着一些不可抗拒的元素,所以请记住一句话:
分布式系统是不可靠的,我们只能尽量减小故障发生率,却根除不了,如果你的老板要你设计一套100%可用性的系统,要么他是二货,要么他是二B