问题描述
应用部发现机器load一直飙升达到600%多, 但IO与CPU都处于正常值状态, 业务流量也没有上升, 机器资源是CPU:2核 内存:8G, 应用: 2个tomcat应用, 需要查找什么原因导致load飙升.
处理过程
查看uptime, 发现load值已处于600%多, 如下:

查看vmstat 与iostat查看IO都处于0值,表现业务并没有什么流量.
在使用top命令检查系统负载的时候,可以看到Load averages字段,但是这个字段并不是表示CPU的繁忙程度,而是度量系统整体负载。系统有很高的负载但是CPU使用率却很低,或者负载很低而CPU利用率很高,这两者没有直接关系.
找出运行队列中的进程
每隔1秒统计:
#!/bin/bash LANG=C PATH=/sbin:/usr/sbin:/bin:/usr/bin interval=1 length=86400 for i in $(seq 1 $(expr ${length} / ${interval}));do date LANG=C ps -eTo stat,pid,tid,ppid,comm --no-header | sed -e 's/^ *//' | perl -nE 'chomp;say if (m!^S*[RD]+S*!)' date cat /proc/loadavg echo -e " " sleep ${interval} done
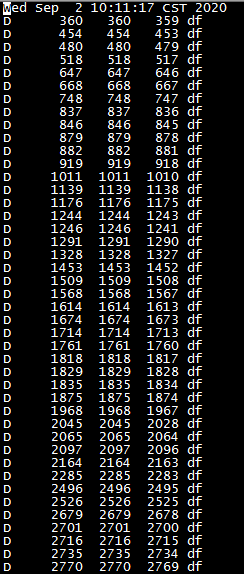
发现有大量的df命令处于D状态, 他们才是造成load上伤的元凶,和我们的应用没有关系. 但是为什么都是df命令呢, 在机器执行df命令发现一直卡起, 马上能定位到业务部查看文件
系统使用时都是直接退出, 找到卡其的原因, 发现这台机器上有nfs, 但是没有挂载所以才会造成执行df 一直卡起.
D代表不可中断的睡眼进程. 找出这些df的进程, 进行kill. load慢慢就降下来了.
检查CPU使用率比较高的线程脚本
#!/bin/bash LANG=C PATH=/sbin:/usr/sbin:/bin:/usr/bin interval=1 length=86400 for i in $(seq 1 $(expr ${length} / ${interval}));do date LANG=C ps -eT -o%cpu,pid,tid,ppid,comm | grep -v CPU | sort -n -r | head -20 date LANG=C cat /proc/loadavg { LANG=C ps -eT -o%cpu,pid,tid,ppid,comm | sed -e 's/^ *//' | tr -s ' ' | grep -v CPU | sort -n -r | cut -d ' ' -f 1 | xargs -I{} echo -n "{} + " && echo ' 0'; } | bc -l sleep ${interval} done fuser -k $0