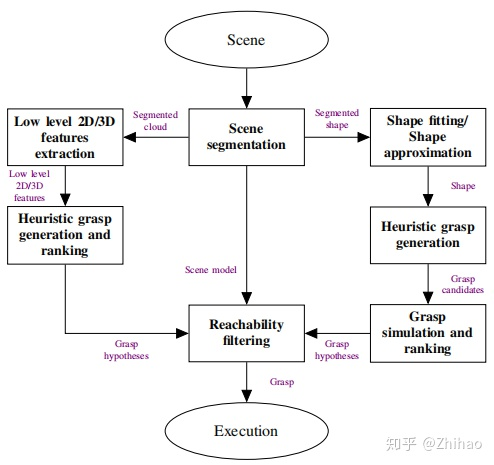
整个流程涉及很多技术。底层控制不做考虑。包含3D视觉,机器人规划,抓取位置的选择等。
链接:https://www.zhihu.com/question/419218982/answer/1500494094
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
机械臂抓取需要确定每段机械臂的位姿
首先,机械臂需要视觉伺服系统,来确定物体的位置,根据末端执行器(手)和视觉传感器(眼)的相对位置,可分为Eye-to-Hand和Eye-in-Hand两种系统。
Eye-to-Hand的分离式分布,视野固定不变,如果相机的标定精度高的话,那么视觉定位于抓取的精度也越高。
Eye-in-Hand则将机械臂与视觉传感器固定在一起,视野随机械臂的移动而改变,传感器越近时精度越高,但过于靠近时则可能使目标超出视野范围。
精密的视觉系统与灵活机械臂的配合,才能完成一次完美的抓取,而这正是当前机器人操作中的核心难题,归纳起来就是这么一件事:找到合适的抓取点(或吸附点),抓住它。之后的转运执行,则属于运动规划的分支。
目前几种主流的解决方案
Model-based(基于模型的方法)
这种方法很好理解,即知道要抓什么,事先采用实物扫描的方式,提前将模型的数据给到机器人系统,机器在实际抓取中就只需要进行较少的运算:
1. 离线计算:根据搭载的末端类型,对每一个物体模型计算局部抓取点;
2. 在线感知:通过RGB或点云图,计算出每个物体的三维位姿;
3. 计算抓取点:在真实世界的坐标系下,根据防碰撞等要求,选取每个物体的最佳抓取点。
RGB颜色空间由红绿蓝三种基本色组成,叠加成任意色彩,同样地,任意一种颜色也可以拆解为三种基本色的组合,机器人通过颜色坐标值来理解“颜色”。这种方式与人眼识别颜色的方向相似,在显示屏上广泛采用。
Half-Model-based(半模型的方法)
在这种训练方式中,不需要完全预知抓取的物体,但是需要大量类似的物体来训练算法,让算法得以在物品堆中有效对图像进行“分割”,识别出物体的边缘。这种训练方式,需要这些流程:
1.离线训练图像分割算法,即把图片里的像素按物体区分出来,此类工作一般由专门的数据标注员来处理,按工程师的需求,标注出海量图片中的不同细节;
2.在线处理图像分割,在人工标注出的物体上,寻找合适的抓取点。
这是一种目前应用较为广泛的方式,也是机械臂抓取得以推进的主要推力。机械臂技术发展缓慢,但计算机视觉的图像分割则进展迅速,也从侧面撬动了机器人、无人驾驶等行业的发展。
Model-free(自由模型)
这种训练方式不涉及到“物体”的概念,机器直接从RGB图像或点云图上计算出合适的抓取点,基本思路就是在图像上找到Antipodal(对映点),即有可能“抓的起来”的点,逐步训练出抓取策略。这种训练方式往往让机器手大量尝试不同种类的物品,进行self-supervisedlearning,Google的Arm Farm,即为其中的代表之一。
从抓取方法上分类可以分成两种:基于分析方法(Analytical),基于数据驱动(Data-driven)。
分析方法:主要是基于动力学及几何学的分析,一般要求知道物体的模型(known object),集大成之作为李泽湘教授的《机器人操作的数学导论》。书中基于旋量理论,介绍了很多机器人manipulation的基础。分析方法有助于我们理解整个抓取过程,理解哪些物理量会影响抓取的稳定性。
数据驱动:主要是基于深度学习、强化学习方法。允许机械臂抓取未知模型的物体(Unknown object)和熟悉的物体(familiar object)。由于是基于深度学习的兴起而发展的,还属于比较新的研究领域,目前还没有发现相关的著作(如果有希望能够推荐一下)。比较经典的入门系列是:的研究领域,目前还没有发现相关的著作(如果有希望能够推荐一下)。比较经典的入门系列是:Dex-net系列。提供了代码、数据集、工程视频,论文也讲的比较清楚。(Dex-Net by BerkeleyAutomation) 数据驱动又可以分为三种方式:learning from human demonstration、learning from labeled training data、trail and error. 分别涉及到的技术为:imitation learning、deep learning、reinforcement learning.
同时根据抓取物体的特点分类,我们可以分成三类: know object、familiar object、unknown object。
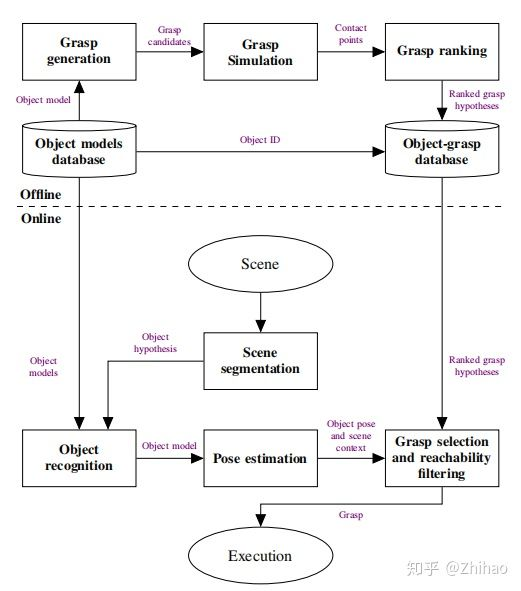
对于known object一般的pipeline为:
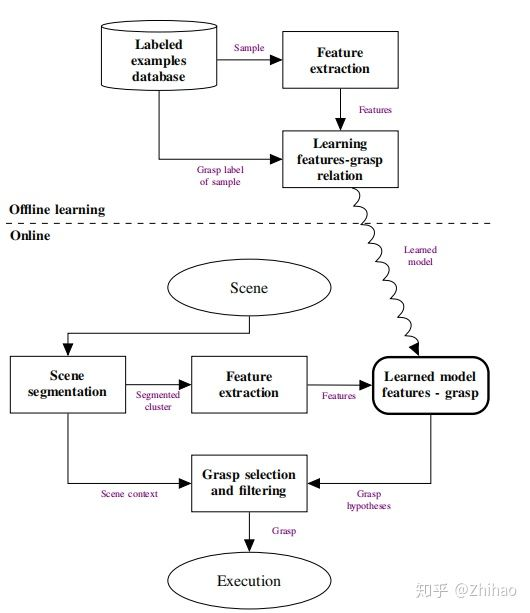
对于familiar object, pipeline为:
对于unknown object, pipeline为: