余弦计算相似度度量
相似度度量(Similarity),即计算个体间的相似程度,相似度度量的值越小,说明个体间相似度越小,相似度的值越大说明个体差异越大。
对于多个不同的文本或者短文本对话消息要来计算他们之间的相似度如何,一个好的做法就是将这些文本中词语,映射到向量空间,形成文本中文字和向量数据的映射关系,通过计算几个或者多个不同的向量的差异的大小,来计算文本的相似度。下面介绍一个详细成熟的向量空间余弦相似度方法计算相似度
向量空间余弦相似度(Cosine Similarity)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。

上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:

如上图二:可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向。如下图
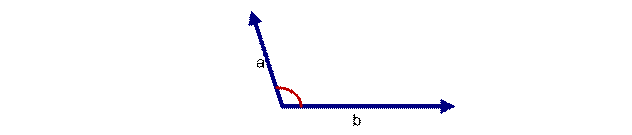
如上图三: 两个向量a,b的夹角很大可以说a向量和b向量有很底的的相似性,或者说a和b向量代表的文本基本不相似。那么是否可以用两个向量的夹角大小的函数值来计算个体的相似度呢?
向量空间余弦相似度理论就是基于上述来计算个体相似度的一种方法。下面做详细的推理过程分析。
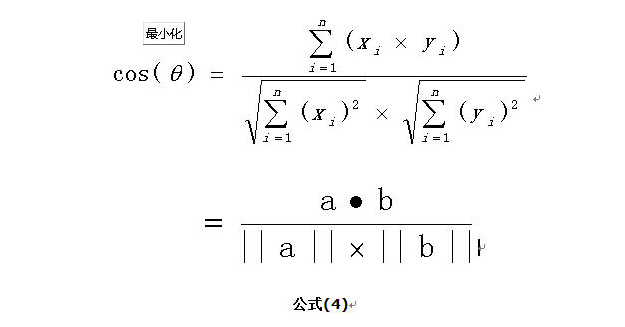
想到余弦公式,最基本计算方法就是初中的最简单的计算公式,计算夹角

图(4)
的余弦定值公式为:

但是这个是只适用于直角三角形的,而在非直角三角形中,余弦定理的公式是
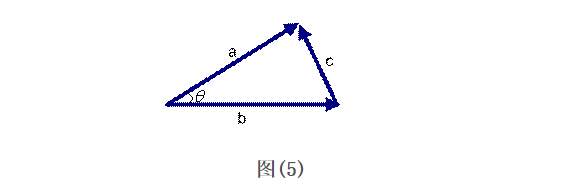
图(5)
三角形中边a和b的夹角 的余弦计算公式为:
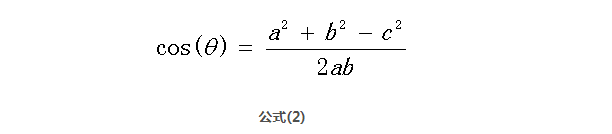
在向量表示的三角形中,假设a向量是(x1, y1),b向量是(x2, y2),那么可以将余弦定理改写成下面的形式:

向量a和向量b的夹角 的余弦计算如下
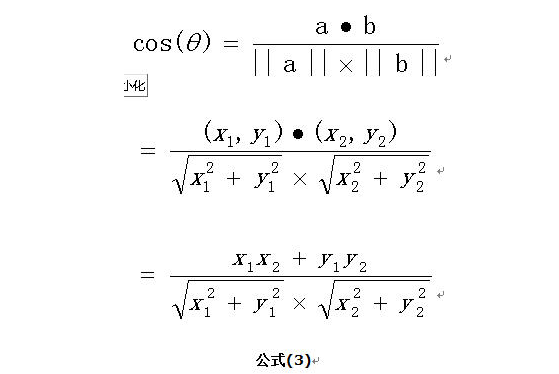
扩展,如果向量a和b不是二维而是n维,上述余弦的计算法仍然正确。假定a和b是两个n维向量,a是 ,b是 ,则a与b的夹角 的余弦等于:
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,夹角等于0,即两个向量相等,这就叫"余弦相似性"。
【下面举一个例子,来说明余弦计算文本相似度】
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
使用上面的公式(4)

计算两个句子向量
句子A:(1,1,2,1,1,1,0,0,0)
和句子B:(1,1,1,0,1,1,1,1,1)的向量余弦值来确定两个句子的相似度。
计算过程如下:

计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
由此,我们就得到了文本相似度计算的处理流程是:
-
找出两篇文章的关键词;
-
每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
-
生成两篇文章各自的词频向量;
-
计算两个向量的余弦相似度,值越大就表示越相似。
python实现


def cosin_distance(vector1, vector2): """ K(X, Y) = <X, Y> / (||X||*||Y||) :param vector1: :param vector2: :return: """ dot_product = 0.0 normA = 0.0 normB = 0.0 for a, b in zip(vector1, vector2): dot_product += a * b normA += a ** 2 normB += b ** 2 if normA == 0.0 or normB == 0.0: return None else: return dot_product / ((normA * normB) ** 0.5)
import numpy as np from sklearn.metrics.pairwise import cosine_similarity user_tag_matric = np.matrix(np.array([vect1, vect2])) user_similarity = cosine_similarity(user_tag_matric) print(user_similarity)
import functools import math import re import time text1 = "This game is one of the very best. games ive played. the ;pictures? " "cant descripe the real graphics in the game." text2 = "this game have/ is3 one of the very best. games ive played. the ;pictures? " "cant descriPe now the real graphics in the game." text3 = "So in the picture i saw a nice size detailed metal puzzle. Eager to try since I enjoy 3d wood puzzles, i ordered it. Well to my disappointment I got in the mail a small square about 4 inches around. And to add more disappointment when I built it it was smaller than the palm of my hand. For the price it should of been much much larger. Don't be fooled. It's only worth $5.00.Update 4/15/2013I have bought and completed 13 of these MODELS from A.C. Moore for $5.99 a piece, so i stand by my comment that thiss one is overpriced. It was still fun to build just like all the others from the maker of this brand.Just be warned, They are small." text4 = "I love it when an author can bring you into their made up world and make you feel like a friend, confidant, or family. Having a special child of my own I could relate to the teacher and her madcap class. I've also spent time in similar classrooms and enjoyed the uniqueness of each and every child. Her story drew me into their world and had me laughing so hard my family thought I had lost my mind, so I shared the passage so they could laugh with me. Read this book if you enjoy a book with strong women, you won't regret it." def timeit(func): @functools.wraps(func) def wrap(*args, **kwargs): start = time.time() res = func(*args, **kwargs) print('运行时间为: {0:.4f}' .format(time.time() - start)) return res return wrap def preprocess(text): """ 文本预处理,可根据具体情况书写逻辑 :param text: :return: """ return text.split() @timeit def compute_cosine(words1, words2): """ 计算两段文本的余弦相似度 :param text_a: :param text_b: :return: """ # 1. 统计词频 words1_dict = {} words2_dict = {} for word in words1: # word = word.strip(",.?!;") word = re.sub('[^a-zA-Z]', '', word) word = word.lower() # print(word) if word != '' and word in words1_dict: num = words1_dict[word] words1_dict[word] = num + 1 elif word != '': words1_dict[word] = 1 else: continue for word in words2: # word = word.strip(",.?!;") word = re.sub('[^a-zA-Z]', '', word) word = word.lower() if word != '' and word in words2_dict: num = words2_dict[word] words2_dict[word] = num + 1 elif word != '': words2_dict[word] = 1 else: continue # nltk统计词频 # 方式一 # words1_dict2 = FreqDist(words1) # 方式二 # from collections import Counter # Counter(text1.split()) # print(words1_dict) # print(words2_dict) # 2. 按照频率排序 dic1 = sorted(words1_dict.items(), key=lambda x: x[1], reverse=True) dic2 = sorted(words2_dict.items(), key=lambda x: x[1], reverse=True) # print(dic1) # print(dic2) # 3. 得到词向量 words_key = [] list(map(lambda x: words_key.append(x[0]), dic1)) list(map(lambda x: words_key.append(x[0]), filter(lambda x: x[0] not in words_key, dic2))) # print(words_key) vect1 = [] vect2 = [] for word in words_key: if word in words1_dict: vect1.append(words1_dict[word]) else: vect1.append(0) if word in words2_dict: vect2.append(words2_dict[word]) else: vect2.append(0) # print(vect1) # print(vect2) # 4. 计算余弦相似度 sum = 0 sq1 = 0 sq2 = 0 for i in range(len(vect1)): sum += vect1[i] * vect2[i] sq1 += pow(vect1[i], 2) sq2 += pow(vect2[i], 2) try: result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2) except ZeroDivisionError: result = 0.0 # skleran实现 import numpy as np # from sklearn.metrics.pairwise import cosine_similarity # user_tag_matric = np.matrix(np.array([vect1, vect2])) # user_similarity = cosine_similarity(user_tag_matric) # print(user_similarity) return result def cosin_distance(vector1, vector2): """ K(X, Y) = <X, Y> / (||X||*||Y||) :param vector1: :param vector2: :return: """ dot_product = 0.0 normA = 0.0 normB = 0.0 for a, b in zip(vector1, vector2): dot_product += a * b normA += a ** 2 normB += b ** 2 if normA == 0.0 or normB == 0.0: return None else: return dot_product / ((normA * normB) ** 0.5) if __name__ == '__main__': text1 = preprocess(text1) text2 = preprocess(text2) print(compute_cosine(text1, text2))