oracle和mysql目前数据库中的巨头,之前公司一直使用的是mysql,今年对oracle有了初步的接触,简单介绍使用过程中的一些总结
特殊sql
distinct
- 通过distinct关键字针对字段去重。 正常后面跟一个字段。就已该字段去重。
项目中遇到表中无主键,但是某个字段不能重复。
正常sql:
select t.*,t.rowid from stage t where t.intersection_id=2;
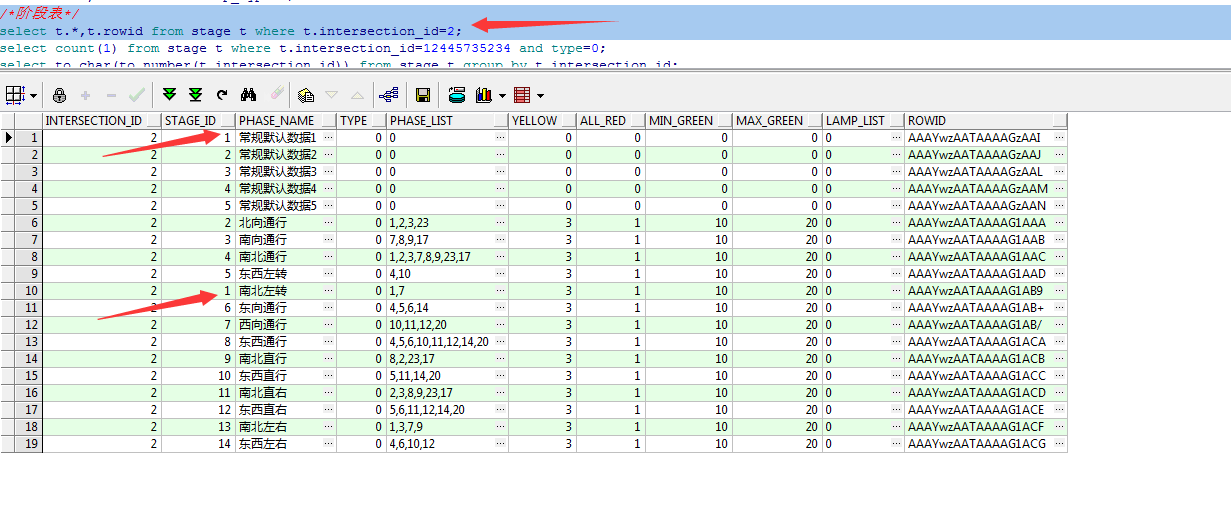
去重sql:
select tt.*
from stage tt
where tt.rowid in (select
max(t.rowid)
from stage t
where t.intersection_id = 2
group by t.stage_id)
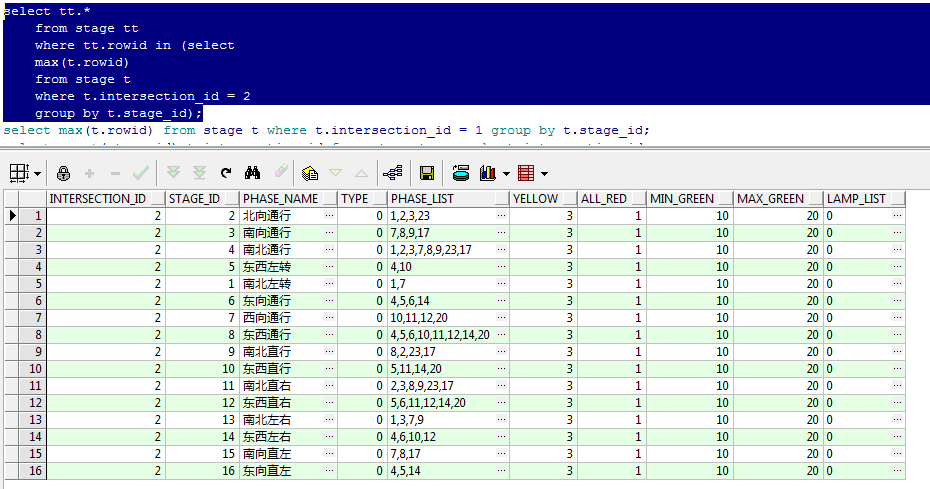
需要匹配id串里的内容
select
*
from stage
where stage_id in (1,9,10,5)
and intersection_id = 1031739143323648;
现在需要按照stage_id 1,9,10,5的顺序排列 '1,1,9,2,10,3,5,4'奇偶分离得到'1,9,10,5'和'1,2,3,4'前者是stageid后者是顺序序号
select
*
from stage
where stage_id in (1,9,10,5)
and intersection_id = 1031739143323648
order by decode(stage_id , 1,1,9,2,10,3,5,4);
批量更新,但是批量成功返回的是-1
开始认为很是奇怪,批量更新成功了,按照道理来说应该是返回批量操作的条数.
返回负数,是由于mybatis的defaultExecutorType的引起的,defaultExecutorType有三个执行器SIMPLE、REUSE和BATCH。
其中BATCH可以批量更新操作缓存SQL以提高性能,但是有个缺陷就是无法获取update、delete返回的行数
如果确定要拿到更新条数,defaultExecutorTypes设置成SIMPLE就可以
<update id="updateBatch" parameterType="java.util.List">
<foreach collection="list" item="item" index="index" open="begin" close=";end;" separator=";">
update T_CITY_INDEX t
set
t.city_name= #{item.cityName,jdbcType=VARCHAR} ,
t.district_name= #{item.districtName,jdbcType=VARCHAR} ,
where t.id = #{item.id,jdbcType=NUMERIC}
</foreach>
</update>
时间格式化
oracle 和 mysql 中对时间格式化都是这样,和我们Java中的格式化时间格式有所不同,YYYY-MM-DD hh24:mi:ss , 不区分大小写
to_char(t.start_time , 'YYYYMMDDHH24mmss')<=to_char(#{endTime},'YYYYMMDDHH24mmss') 将date格式时间格式化字符串比较
to_number() 将数字型字符串格式化成数字
行列互转
- 在实际开发中我们可能遇到行列互转的情况,这个时候如果先查出来通过Java做转换,最终是可以实现效果,但是效率将会大大降低.
oracle提供了 pivot 和 unpivot 关键字 ,mysql中没有尝试过 , 有兴趣的可以尝试下mysql中是否有这两个关键字 .下面看看实际的操作
应用场景
列转行
首先我们看下图中的sql查出来的数据是我再业务开发中需要的一个汇总数据.
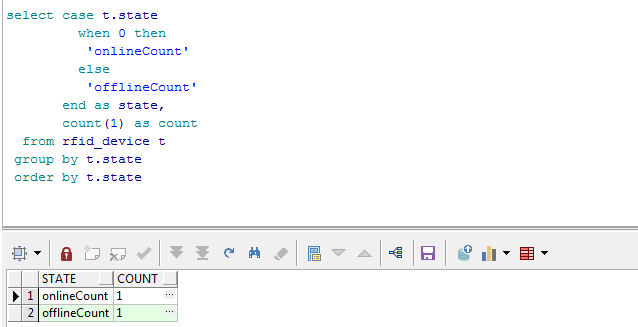
但是这个数据不是完全符合我们的需求.我们在外层(Java)中是用实体接受onlineCount,offlineCount数据的,我们提供到web端也是通过这两个字段.但是
现在的情况我们Java接受到的是个集合,集合中的实体的属性是state,count这个两个数据,state的值是onlineCount或offlineCount.这很明显不符合业务需求.
但是我们发现只需要将列转成行我们就很容易完成实体的映射.下面的格式才是我们需要的

那么如何列转行呢,oracle提供了我们方式(pivot),我们通过这个关键字可以将列名转成行名.默认是会将列的值加上"",这个时候我们正常都需要为行名(属性名)添加别名
具体sql
select *
from (select case t.state
when 0 then
'onlineCount'
else
'offlineCount'
end as state,
count(1) as count
from rfid_device t
group by t.state
order by t.state)
pivot(sum(count)
for state in('onlineCount' onlineCount, 'offlineCount' offlineCount))
ps: pivot(func for field in ("col1" col1,"col2" col2,...,"coln" coln))
着我们可以理解成语法来记忆
pivot : 关键字
for : 关键字 (固定语法)
field : 列名(原本的属性名)
in : 关键字
coln : 是源数据中的field属性的具体值,就是我们转换后的属性值
func : 是个聚合函数(聚合函数里的对象正常就是转换后的内容)
建议大家对照数据查看,这样比较容易理解 , 上面的coln 是 "coln" 的别名
行转列
上面通过pivot关键字我们是实现了列转行,有来必有往,所以我们有必要了解一下行转列的情况,oracle提供的也很有意思unpivot , 顾名思义就是列转行的反向-->行转列
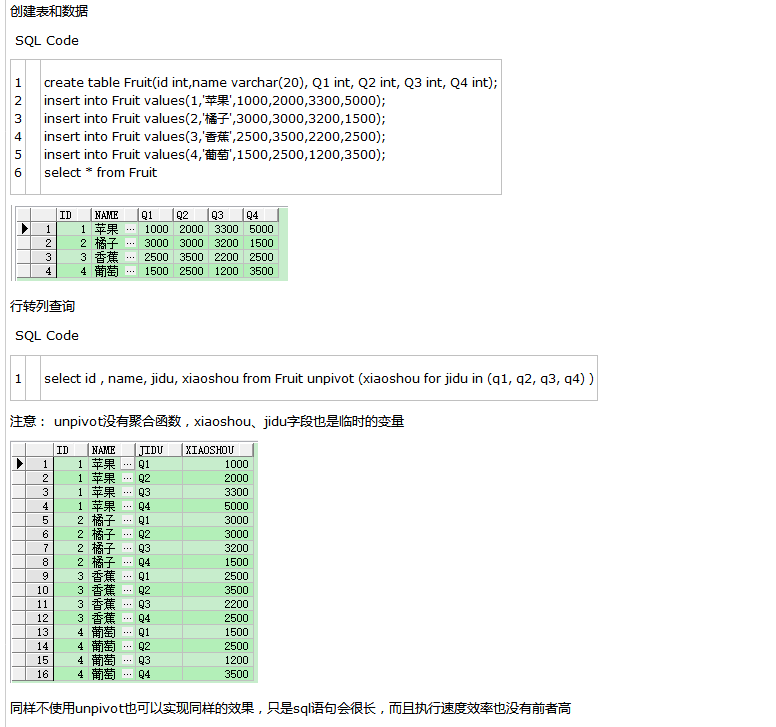
总结
我们通过上面两个案例可以发现,这两个是通用的.意思是说可以通过unpivot 将pivot的数据转回去.因为pivot后的属性其实是列值,而unpivot就是将属性名转成列值