一、Hadoop原理介绍
1、请参考原理篇:Hadoop1-认识Hadoop大数据处理架构
二、centos7单机部署hadoop 前期准备
1、创建用户
[root@web3 ~]# useradd -m hadoop -s /bin/bash #---创建hadoop用户 [root@web3 ~]# passwd hadoop #---创建密码 Changing password for user hadoop. New password: BAD PASSWORD: The password is a palindrome Retype new password: passwd: all authentication tokens updated successfully. [root@web3 ~]#
2、添加用户权限
[root@web3 ~]# chmod u+w /etc/sudoers #---给sudo文件写权限 [root@web3 ~]# cat /etc/sudoers |grep hadoop #---这里自行vim添加,这里是用cat命令展示为添加后的效果 hadoop ALL=(ALL) ALL [root@web3 ~]# [root@web3 ~]# chmod u-w /etc/sudoers #---给sudo去掉写权限
3、安装软件openssh,生成授权,免密码
1)安装
[root@web3 ~]# su hadoop #切换用户hadoop [hadoop@web3 root]$ sudo yum install openssh-clients openssh-server #---安装openssh
1)操作步骤
cd .ssh/ ssh-keygen -t rsa cat id_rsa.pub >> authorized_keys chmod 600 ./authorized_keys
4、安装java
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
#---用rpm -ql查看java相关目录
[hadoop@web3 bin]$ rpm -ql java-1.8.0-openjdk.x86_64 1:1.8.0.222.b10-1.el7_7 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/bin/policytool /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/lib/amd64/libawt_xawt.so /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/lib/amd64/libjawt.so /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/lib/amd64/libjsoundalsa.so /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/lib/amd64/libsplashscreen.so /usr/share/applications/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64-policytool.desktop /usr/share/icons/hicolor/16x16/apps/java-1.8.0-openjdk.png /usr/share/icons/hicolor/24x24/apps/java-1.8.0-openjdk.png /usr/share/icons/hicolor/32x32/apps/java-1.8.0-openjdk.png /usr/share/icons/hicolor/48x48/apps/java-1.8.0-openjdk.png package 1:1.8.0.222.b10-1.el7_7 is not installed [hadoop@web3 bin]$
5、添加环境变量
[hadoop@web3 bin]$ cat ~/.bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER=
# User specific aliases and functions
#---添加此环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64
#---输出检查
[hadoop@web3 jvm]$ echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64
#---输出jave版本
[hadoop@web3 jvm]$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
#---使用变量输出java版本
[hadoop@web3 jvm]$ $JAVA_HOME/bin/java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
[hadoop@web3 jvm]$
java -version 与$JAVA_HOME/bin/jave -version运行一直即代表添加成功
6、开始安装hadoop 3.1.2
下载路径:http://mirror.bit.edu.cn/apache/hadoop/common/
上传到服务器
[hadoop@web3 root]$ cd [hadoop@web3 ~]$ ll total 324644 -rw-r--r-- 1 hadoop hadoop 332433589 Oct 17 19:57 hadoop-3.1.2.tar.gz drwxrwxr-x 2 hadoop hadoop 6 Oct 18 03:43 ssh [hadoop@web3 ~]$ sudo tar -zxf hadoop-3.1.2.tar.gz -C /usr/local [sudo] password for hadoop: [hadoop@web3 ~]$ cd /usr/local [hadoop@web3 local]$ sudo mv hadoop-3.1.2/ ./hadoop [hadoop@web3 local]$ ll total 0 drwxr-xr-x. 2 root root 6 Nov 5 2016 bin drwxr-xr-x. 2 root root 6 Nov 5 2016 etc drwxr-xr-x. 2 root root 6 Nov 5 2016 games drwxr-xr-x 9 hadoop 1002 149 Jan 29 2019 hadoop drwxr-xr-x. 2 root root 6 Nov 5 2016 include drwxr-xr-x. 2 root root 6 Nov 5 2016 lib drwxr-xr-x. 2 root root 6 Nov 5 2016 lib64 drwxr-xr-x. 2 root root 6 Nov 5 2016 libexec drwxr-xr-x. 2 root root 6 Nov 5 2016 sbin drwxr-xr-x. 5 root root 49 Aug 16 2017 share drwxr-xr-x. 2 root root 6 Nov 5 2016 src [hadoop@web3 local]$ chown -R hadoop:hadoop ./hadoop [hadoop@web3 local]$ cd hadoop/
[hadoop@web3 hadoop]$ ./bin/hadoop version Hadoop 3.1.2 Source code repository https://github.com/apache/hadoop.git -r 1019dde65bcf12e05ef48ac71e84550d589e5d9a Compiled by sunilg on 2019-01-29T01:39Z Compiled with protoc 2.5.0 From source with checksum 64b8bdd4ca6e77cce75a93eb09ab2a9 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.2.jar [hadoop@web3 hadoop]$ pwd /usr/local/hadoop [hadoop@web3 hadoop]$
三、Hadoop单机配置-非分布式
hadoop默认模式为非分布式模式,无需进行其他配置即可运行,非分布式即但java进程,方便进行调试
hadoop附带了丰富的例子(./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar 可以看到所有例子),包括wordcount、terasort、join、grep等
1、现在运行grep测试一下
这个实例是运行grep例子,将input文件夹所有文件作为输入,筛选当中符合正则表达式dfs[a-z.]+的单词并统计出现的次数,最后输出结果到output文件夹中
mkdir ./input cp ./etc/hadoop/*.xml ./input #---将配置文件作为输入文件 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar grep ./input ./output 'dfs[a-z.]+'
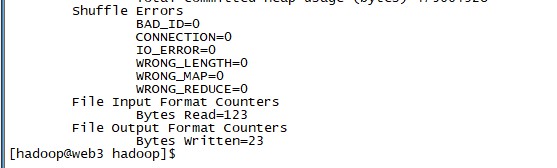
2、正确的运行结果
运行hadoop实例,成功的话会输出很多作业的相关信息,最后的输出信息就是下面图示,作业结果会输出在指定的output文件夹中,通过命令cat ./output/* 查看结果,符合正则的单词dfsadmin出现了一次。
[hadoop@web3 hadoop]$ cat ./output/* #如果要重新运行 1 dfsadmin [hadoop@web3 hadoop]$
四、Hadoop伪分布式配置
hadoop可以在单台节点以伪分布式运行,hadoop进程以分离的java进程来运行,节点作为namenode也作为datanode,同时,读取的时HDFS中的文件
1、设置环境变量
[hadoop@web3 hadoop]$ vim ~/.bashrc # .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions #Java environment variables export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64 #Hadoop environment Variables export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin ~
更新环境变量
2、修改被指文件
配置文件位于/usr/local/hadoop/etc/hadoop/中,伪分布式需要两个配置文件core-site.xml和hdfs-site.xml,hadoop的配置文件时xml格式,每个配置声明property的name和value的方式来实现
core-site.xml
修改标注红色字体部分
[hadoop@web3 hadoop]$ vim ./etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> ~ ~
hdfs-site.xml
[hadoop@web3 hadoop]$ vim ./etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
3、执行namenode的格式化
[hadoop@web3 hadoop]$ ./bin/hdfs namenode -format WARNING: /usr/local/hadoop/logs does not exist. Creating. 2019-10-18 18:56:45,336 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = web3/192.168.216.53 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.1.2 STARTUP_MSG: classpath = /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/accessors-smart-1.2.jar:/usr/local/hadoop/share/hadoop/common/lib/asm- 。。。。。。。。。。。。。。。。。这里省略一堆。。。。。。。。。。。。。。。。。。。。。。。。。 2019-10-18 18:56:47,031 INFO namenode.FSDirectory: XAttrs enabled? true 2019-10-18 18:56:47,032 INFO namenode.NameNode: Caching file names occurring more than 10 times 2019-10-18 18:56:47,046 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536 2019-10-18 18:56:47,049 INFO snapshot.SnapshotManager: SkipList is disabled 2019-10-18 18:56:47,057 INFO util.GSet: Computing capacity for map cachedBlocks 2019-10-18 18:56:47,057 INFO util.GSet: VM type = 64-bit 2019-10-18 18:56:47,057 INFO util.GSet: 0.25% max memory 411 MB = 1.0 MB 2019-10-18 18:56:47,058 INFO util.GSet: capacity = 2^17 = 131072 entries 2019-10-18 18:56:47,083 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2019-10-18 18:56:47,084 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2019-10-18 18:56:47,084 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2019-10-18 18:56:47,090 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2019-10-18 18:56:47,090 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2019-10-18 18:56:47,094 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2019-10-18 18:56:47,094 INFO util.GSet: VM type = 64-bit 2019-10-18 18:56:47,094 INFO util.GSet: 0.029999999329447746% max memory 411 MB = 126.3 KB 2019-10-18 18:56:47,094 INFO util.GSet: capacity = 2^14 = 16384 entries 2019-10-18 18:56:47,154 INFO namenode.FSImage: Allocated new BlockPoolId: BP-178131724-192.168.216.53-1571396207141 2019-10-18 18:56:47,182 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted. 2019-10-18 18:56:47,201 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 2019-10-18 18:56:47,421 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds . 2019-10-18 18:56:47,443 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2019-10-18 18:56:47,454 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at web3/192.168.216.53 ************************************************************/ [hadoop@web3 hadoop]$
执行后查看最后几行的info信息,查看是否成功
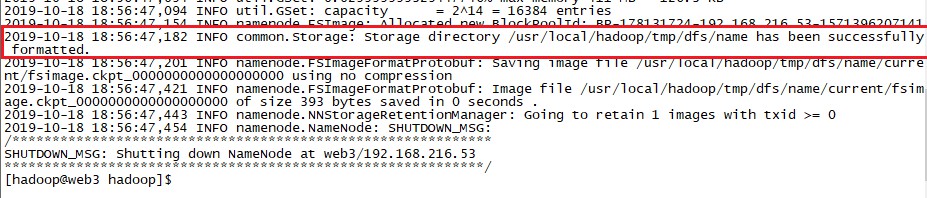
可以看到已经成功格式化
4、开启namenode和datanode守护进程
[hadoop@web3 hadoop]$ ./sbin/start-dfs.sh #--开启namenode和datanode守护进程 Starting namenodes on [localhost] localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Starting datanodes Starting secondary namenodes [web3] web3: Warning: Permanently added 'web3,fe80::9416:80e8:f210:1e24%ens33' (ECDSA) to the list of known hosts. 2019-10-18 19:21:54,710 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@web3 hadoop]$ jps #--检查是否启动,jps 看到namenode和datanode就说明启动了 15153 NameNode 15270 DataNode 15478 SecondaryNameNode 15646 Jps [hadoop@web3 hadoop]$
如提示WARN util.NativeCodeLoader,整个提示不会影响正常启动
5、查看监听端口并访问web界面
1)查看监听端口
如下:应该是43332整个端口
[hadoop@web3 hadoop]$ netstat -unltop (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer tcp 0 0 0.0.0.0:9866 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 0.0.0.0:9867 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 0.0.0.0:9868 0.0.0.0:* LISTEN 17770/java off (0.00/0/0) tcp 0 0 0.0.0.0:9870 0.0.0.0:* LISTEN 17423/java off (0.00/0/0) tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 127.0.0.1:43332 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 0.0.0.0:9864 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 17423/java off (0.00/0/0) tcp6 0 0 :::111 :::* LISTEN - off (0.00/0/0) tcp6 0 0 :::22 :::* LISTEN - off (0.00/0/0) tcp6 0 0 ::1:631 :::* LISTEN - off (0.00/0/0) tcp6 0 0 ::1:25 :::* LISTEN - off (0.00/0/0) tcp6 0 0 ::1:6010 :::* LISTEN - off (0.00/0/0) udp 0 0 0.0.0.0:5353 0.0.0.0:* - off (0.00/0/0) udp 0 0 0.0.0.0:50666 0.0.0.0:* - off (0.00/0/0) udp 0 0 192.168.122.1:53 0.0.0.0:* - off (0.00/0/0) udp 0 0 0.0.0.0:67 0.0.0.0:* - off (0.00/0/0) [hadoop@web3 hadoop]$
2)访问web端
成功启动后web访问一下,可以查看namenode和datanode信息,还可以在线查看hdfs中的文件如下图:
http://localhost:43332

五、Hadoop伪分布式实例
1、HDFS中创建用户目录
#--HDFS中创建用户目录
[hadoop@web3 hadoop]$ ./bin/hdfs dfs -mkdir -p /user/hadoop
2019-10-18 22:56:44,350 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2、创建一个input目录,并复制/usr/local/hadoop/etc/hadoop文件中的所有xml文件
[hadoop@web3 hadoop]$ ./bin/hdfs dfs -mkdir input
2019-10-18 22:58:03,745 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@web3 hadoop]$ ./bin/hdfs dfs -put ./etc/hadoop/*.xml input
2019-10-18 22:58:39,703 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
3、查看HDFS文件列表
[hadoop@web3 hadoop]$ ./bin/hdfs dfs -ls input 2019-10-18 22:59:04,118 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 9 items -rw-r--r-- 1 hadoop supergroup 8260 2019-10-18 22:58 input/capacity-scheduler.xml -rw-r--r-- 1 hadoop supergroup 1075 2019-10-18 22:58 input/core-site.xml -rw-r--r-- 1 hadoop supergroup 11392 2019-10-18 22:58 input/hadoop-policy.xml -rw-r--r-- 1 hadoop supergroup 1133 2019-10-18 22:58 input/hdfs-site.xml -rw-r--r-- 1 hadoop supergroup 620 2019-10-18 22:58 input/httpfs-site.xml -rw-r--r-- 1 hadoop supergroup 3518 2019-10-18 22:58 input/kms-acls.xml -rw-r--r-- 1 hadoop supergroup 682 2019-10-18 22:58 input/kms-site.xml -rw-r--r-- 1 hadoop supergroup 758 2019-10-18 22:58 input/mapred-site.xml -rw-r--r-- 1 hadoop supergroup 690 2019-10-18 22:58 input/yarn-site.xml [hadoop@web3 hadoop]$
4、实例演示
伪分布式运行mapreduce作业的方式和单机一样,区别在于伪分布式读取的是HDFS中的文件
[hadoop@web3 hadoop]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar grep input output 'dfs[a-z.]+'
2019-10-18 23:06:38,782 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2019-10-18 23:06:40,494 INFO impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-10-18 23:06:40,809 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2019-10-18 23:06:40,810 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2019-10-18 23:06:41,480 INFO input.FileInputFormat: Total input files to process : 9
2019-10-18 23:06:41,591 INFO mapreduce.JobSubmitter: number of splits:9
2019-10-18 23:06:42,290 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1738759870_0001
2019-10-18 23:06:42,293 INFO mapreduce.JobSubmitter: Executing with tokens: []
。。。。。。。。。。。。。。#省略若干#。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=219 File Output Format Counters Bytes Written=77
#---检查运行结果
[hadoop@web3 hadoop]$ ./bin/hdfs dfs -cat output/* 2019-10-18 23:07:19,640 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 1 dfsadmin 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.datanode.data.dir [hadoop@web3 hadoop]$
5、实例2,也可以把结果取回本地
删除本地output
rm -r ./output
将hdfs中的output拷贝到本机
./bin/hdfs dfs -get output ./output
查看
cat ./output/*
[hadoop@web3 hadoop]$ rm -r ./output [hadoop@web3 hadoop]$ ./bin/hdfs dfs -get output ./output 2019-10-18 23:31:21,062 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [hadoop@web3 hadoop]$ cat ./output/* 1 dfsadmin 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.datanode.data.dir [hadoop@web3 hadoop]$
删除hdfs output
注意hadoop运行程序时,输出目录不能存在,否则会提示错误
[hadoop@web3 hadoop]$ ./bin/hdfs dfs -rm -r output 2019-10-18 23:35:55,620 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Deleted output [hadoop@web3 hadoop]$
六、启动YARN
伪分布式启动YARN也可以,一般不会影响程序执行,上面./sbin/start-dfs.sh启动hadoop,仅仅时启动了MapReduce环境,还可以启动YARN,让YARN来复制资源管理与任务调度。
还有上面例子未见JobTracker和TaskTracker,这时因为新版hadoop使用了新的MapReduce框架(MapReduce V2,也称为YARN,Yet Another Resource Negotiator)
YARN是从MapReduce中分离出来的,复制资源管理与任务调度。YARN运行于MapReduce之上,提供了高可用性、高扩展性
1、编辑mapred-site.xml
[hadoop@web3 hadoop]$ cat ./etc/hadoop/mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
2、编辑yarn-site.xml
[hadoop@web3 hadoop]$ cat ./etc/hadoop/yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
3、启动YARN
[hadoop@web3 hadoop]$ ./sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [hadoop@web3 hadoop]$ jps 17553 DataNode 24982 ResourceManager #---启动后多了一个ResourceManager 25448 Jps 25097 NodeManager #---启动后多了一个NodeManager 17770 SecondaryNameNode 17423 NameNode #---开启历史服务器,能在web中查看任务运行情况
[hadoop@web3 hadoop]$ ./sbin/mr-jobhistory-daemon.sh start historyserver
4、提示
启动YARN之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志可以发现,不启用YARN时,是“mapred.LocalJobRunner”在跑,启用YARN之后,是“mapred.YARNRuner”在跑任务,启用YARN有个好处是可以通过web界面查看任务情况
http://localhost:8088/cluster
通过netstat -untlop可以看到监听到了8088
[hadoop@web3 hadoop]$ netstat -untlop (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer tcp 0 0 0.0.0.0:8042 0.0.0.0:* LISTEN 25097/java off (0.00/0/0) tcp 0 0 0.0.0.0:9866 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 0.0.0.0:9867 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 0.0.0.0:9868 0.0.0.0:* LISTEN 17770/java off (0.00/0/0) tcp 0 0 0.0.0.0:9870 0.0.0.0:* LISTEN 17423/java off (0.00/0/0) tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 24982/java off (0.00/0/0) tcp 0 0 0.0.0.0:37849 0.0.0.0:* LISTEN 25097/java off (0.00/0/0) tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 0.0.0.0:13562 0.0.0.0:* LISTEN 25097/java off (0.00/0/0) tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN - off (0.00/0/0) tcp 0 0 0.0.0.0:8030 0.0.0.0:* LISTEN 24982/java off (0.00/0/0) tcp 0 0 0.0.0.0:8031 0.0.0.0:* LISTEN 24982/java off (0.00/0/0) tcp 0 0 0.0.0.0:8032 0.0.0.0:* LISTEN 24982/java off (0.00/0/0) tcp 0 0 0.0.0.0:8033 0.0.0.0:* LISTEN 24982/java off (0.00/0/0) tcp 0 0 127.0.0.1:43332 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 0.0.0.0:8040 0.0.0.0:* LISTEN 25097/java off (0.00/0/0) tcp 0 0 0.0.0.0:9864 0.0.0.0:* LISTEN 17553/java off (0.00/0/0) tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 17423/java off (0.00/0/0) tcp6 0 0 :::111 :::* LISTEN - off (0.00/0/0) tcp6 0 0 :::22 :::* LISTEN - off (0.00/0/0) tcp6 0 0 ::1:631 :::* LISTEN - off (0.00/0/0) tcp6 0 0 ::1:25 :::* LISTEN - off (0.00/0/0) tcp6 0 0 ::1:6010 :::* LISTEN - off (0.00/0/0) udp 0 0 0.0.0.0:5353 0.0.0.0:* - off (0.00/0/0) udp 0 0 0.0.0.0:50666 0.0.0.0:* - off (0.00/0/0) udp 0 0 192.168.122.1:53 0.0.0.0:* - off (0.00/0/0) udp 0 0 0.0.0.0:67 0.0.0.0:* - off (0.00/0/0) [hadoop@web3 hadoop]$
5、访问web界面

6、运行一个任务
提示错误
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
看到如下提示,下面排错就按照提示修改mapred-site.xml


[2019-10-18 16:47:52.678]Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> [2019-10-18 16:47:52.679]Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property>
7、排错
修改配置文件mapred-site.xml,
[root@web3 hadoop]# cat ./etc/hadoop/mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration> [root@web3 hadoop]#
7、再次运行
运行成功
[hadoop@web3 hadoop]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar grep input output 'dfs[a-z.]+'

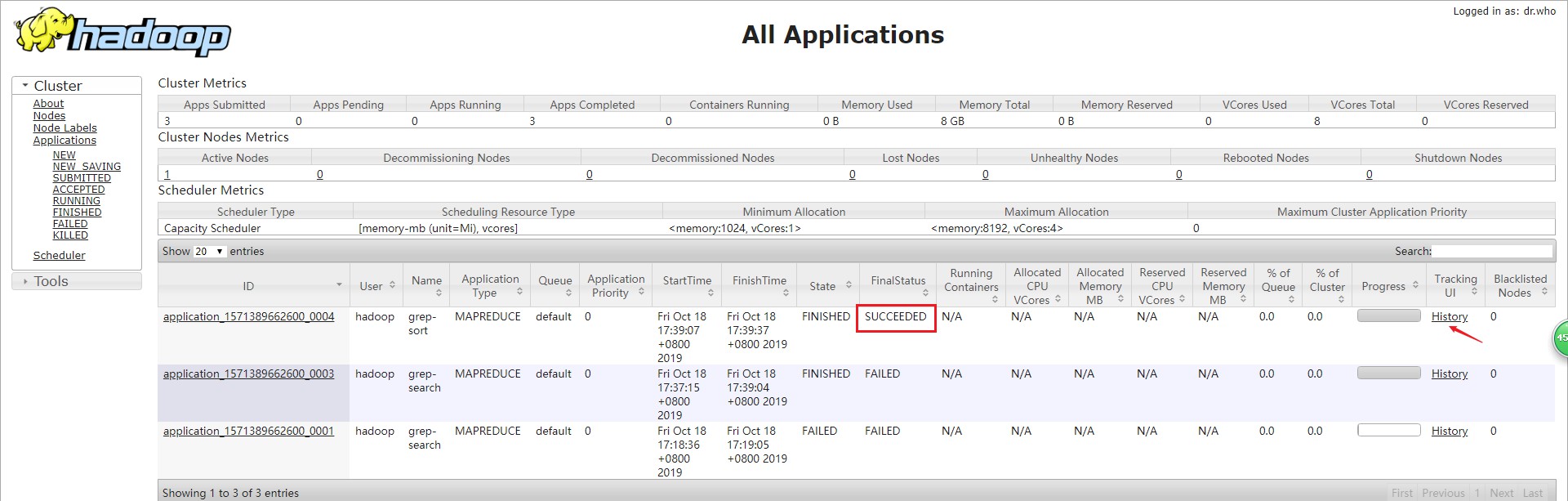
很明显,YARN主要是为集群提供更好的资源管理与任务调度,在单机上反之会使程序跑的更慢,所以单机是否开启YARN要看实际情况
8、关闭YARN
./sbin/stop-yarn.sh ./sbin/mr-jobhistory-daemon.sh stop historyserver
本文参考1:http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/
本文参考2:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
转载请注明出处:https://www.cnblogs.com/zhangxingeng/p/11675760.html