1.为什么需要好的权重初始化
网络训练的过程中, 容易出现梯度消失(梯度特别的接近0)和梯度爆炸(梯度特别的大)的情况,导致大部分反向传播得到的梯度不起作用或者起反作用. 研究人员希望能够有一种好的权重初始化方法: 让网络前向传播或者反向传播的时候, 卷积的输出和前传的梯度比较稳定. 合理的方差既保证了数值一定的不同, 又保证了数值一定的稳定.(通过卷积权重的合理初始化, 让计算过程中的数值分布稳定)
2.kaiming初始化的两个方法
2.1先来个结论
- 前向传播的时候, 每一层的卷积计算结果的方差为1.
- 反向传播的时候, 每一 层的继续往前传的梯度方差为1(因为每层会有两个梯度的计算, 一个用来更新当前层的权重, 一个继续传播, 用于前面层的梯度的计算.)
2.2再来个源码
方差的计算需要两个值:gain和fan. gain值由激活函数决定. fan值由权重参数的数量和传播的方向决定. fan_in表示前向传播, fan_out表示反向传播.
def kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
fan = _calculate_correct_fan(tensor, mode)
# 通过mode判断是前向传播还是反向传播, 生成不同的一个fan值.
gain = calculate_gain(nonlinearity, a)
# 通过判断是哪种激活函数生成一个gain值
std = gain / math.sqrt(fan) # 通过fan值和gain值进行标准差的计算
with torch.no_grad():
return tensor.normal_(0, std)
下面的代码根据网络设计时卷积权重的形状和前向传播还是反向传播, 进行fan值的计算.
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.dim() # 返回的是维度
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions")
if dimensions == 2: # Linear
fan_in = tensor.size(1)
fan_out = tensor.size(0)
else:
num_input_fmaps = tensor.size(1) # 卷积的输入通道大小
num_output_fmaps = tensor.size(0) # 卷积的输出通道大小
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel() # 卷积核的大小:k*k
fan_in = num_input_fmaps * receptive_field_size # 输入通道数量*卷积核的大小. 用于前向传播
fan_out = num_output_fmaps * receptive_field_size # 输出通道数量*卷积核的大小. 用于反向传播
return fan_in, fan_out
def _calculate_correct_fan(tensor, mode):
mode = mode.lower()
valid_modes = ['fan_in', 'fan_out']
if mode not in valid_modes:
raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes))
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
return fan_in if mode == 'fan_in' else fan_out
下面是通过不同的激活函数返回一个gain值, 当然也说明了是recommend. 可以自己修改.
def calculate_gain(nonlinearity, param=None):
r"""Return the recommended gain value for the given nonlinearity function.
The values are as follows:
================= ====================================================
nonlinearity gain
================= ====================================================
Linear / Identity :math:`1`
Conv{1,2,3}D :math:`1`
Sigmoid :math:`1`
Tanh :math:`\frac{5}{3}`
ReLU :math:`\sqrt{2}`
Leaky Relu :math:`\sqrt{\frac{2}{1 + \text{negative\_slope}^2}}`
================= ====================================================
Args:
nonlinearity: the non-linear function (`nn.functional` name)
param: optional parameter for the non-linear function
Examples:
>>> gain = nn.init.calculate_gain('leaky_relu', 0.2) # leaky_relu with negative_slope=0.2
"""
linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d']
if nonlinearity in linear_fns or nonlinearity == 'sigmoid':
return 1
elif nonlinearity == 'tanh':
return 5.0 / 3
elif nonlinearity == 'relu':
return math.sqrt(2.0)
elif nonlinearity == 'leaky_relu':
if param is None:
negative_slope = 0.01
elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float):
# True/False are instances of int, hence check above
negative_slope = param
else:
raise ValueError("negative_slope {} not a valid number".format(param))
return math.sqrt(2.0 / (1 + negative_slope ** 2))
else:
raise ValueError("Unsupported nonlinearity {}".format(nonlinearity))
下面是kaiming初始化均匀分布的计算. 为啥还有个均匀分布? 权重初始化推导的只是一个方差, 并没有限定是正态分布, 均匀分布也是有方差的, 并且均值为0的时候, 可以通过方差算出均匀分布的最小值和最大值.
def kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
fan = _calculate_correct_fan(tensor, mode)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan)
bound = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation
with torch.no_grad():
return tensor.uniform_(-bound, bound)
3.推导的先验知识
3.1用变量来看待问题
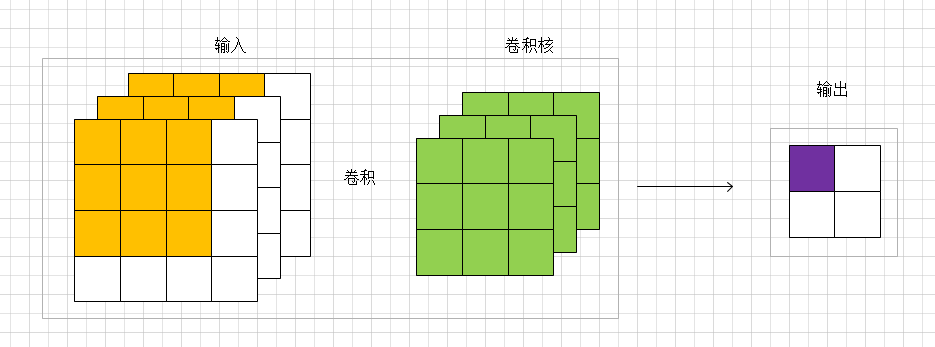
参照上面的卷积图, 对输入的特征图进行的卷积. 具体要研究的是输出的一个点的方差(紫色点). 所以是通过黄色的输入(
个)和绿色的卷积参数(
个)去计算一个输出值(紫色输出)的方差. 一个点对应于原论文里面的说法为a response. 感觉这个是理解权重初始化的重点. 基于独立同分布的强假设: 输入的每个值都是独立同分布的, 所以和独立同分布的参数进行卷积得到结果的分布也是相同的. 所以其他的3个输出点的方差也是一样的. 进一步说, 虽然输入是
个不同的值. 但是我们可以这样认为: 有一个满足某分布的随机变量
, 然后随机抽样48次, 这48个值就可以组成了输入, 且独立同分布(也可称输入的每个像素点是独立同分布的). 卷积的参数也可以这么认为. 那么我们可以用一个随机变量
表示48个输入, 也可以用一个随机变量
表示27个卷积参数, 亦可以用一个随机变量
表示4个输出值.
3.2几个公式
式表示独立随机变量之和的方差等于各变量的方差之和, 如果
和
还是同分布的,那么
. 将这个应用在卷积求和的那一步(卷积先相乘, 再求和).
式是通过期望求方差的公式, 方差等于平方的期望减去期望的平方. 如果
, 那么
.
式是独立变量乘积的一个公式(协方差为0). 如果
, 那么
.
4.kaiming初始化
kaiming初始化的推导过程只包含卷积和ReLU激活函数, 默认是vgg类似的网络, 没有残差, concat之类的结构, 也没有BN层.
此处,表示某个位置的输出值,
表示被卷积的输入,有
形状(对应于上图的黄色部分),
表示卷积核的大小,
表示输入的通道.令
,则
的大小表示一个输出值是由多少个输入值计算出来的(求方差的时候用到).
有
形状,
表示的输出通道的数量.下标
表示第几层.
,
表示激活函数ReLU, 表示前一层的输出经过激活函数变成下一层的输入.
表示网络下一层的输入通道数等于上一层的输出通道数.(这里是对应原论文的翻译了)
4.1前向传播时每层的方差都是1
因为一个输出的是由
个输入的
和其
个权重相乘再求和得到的(卷积的过程), 且假设权重数值之间是独立同分布的,
数值之间也是独立同分布的,且
和权重相互独立。那么根据(1)式得
其中的都表示随机变量,
表示第几层. 举个例子
, 其中,
看作一个整体, 且1到6之间相互独立, 就能得到
, 又如果
之间又是同分布的, 那么他们的方差就是相同的, 就能得到
.
进一步,因为是相互独立的, 所以根据(3)式,可将(4)式推导为
初始化的时候令权重的均值是0, 且假设更新的过程中权重的均值一直是0,则,但是
是上一层通过ReLU得到的,所以
.
通过(2)式可得,则(6)式推导为
接下来求, 通过第
层的输出来求此期望, 我们有
, 其中
表示ReLU函数.
因为的时候
, 所以可以去掉小于0的区间, 并且大于0的时候
, 所以可得
现因为是假设在0周围对称分布且均值为0, 所以
也是在0附近分布是对称的, 并且均值为0(此处假设偏置为0,). 则
, 进一步可以得到
现在通过公式(2), ,其中
的均值是0, 则
,那么(10)式可进一步推导为
将(11)式带入(7)式则为
然后从第一层一直往前进行前向传播, 可以得到某层的方差为
这里的就是输入的样本, 我们会将其归一化处理, 所以
, 现在让每层输出方差等于1, 即
举例层卷积, 输入大小为, 分别表示通道数量、高、宽, 卷积核大小为
, 分别表示输出通道数量、输入通道数量、卷积核高、卷积核宽. 则该层的权重
, 偏置初始化为0.
个参数都是从这个分布里面采样. 也对应了Pytorch里面的kaiming初始化只要传卷积核的参数进去就行了, 可以看下源码对应的计算.
4.2反向传播时梯度的方差都是1
其中, 表示损失函数对其求导. 与正常的反向传播推导不一样, 这里假设
表示
个通道,每个通道
大小,
,与正向传播的时候一样,
有
个通道,
有
个通道.
的大小为
,所以
的形状为
.
和
只差了一个转置(涉及到反向传播). 同样的想法是, 一个
的值是很多个
求得到, 继续通过多个独立同分布变量求一个变量(梯度)的方差. 假设随机变量
都是独立同分布的,
的分布在0附近对称的, 则
对每层
,均值都是0, 即
. 因为前向传播的时候
所以反向传播则为
又因为是ReLU, 导数要么是0要么是1, 那么假设两者各占一半, 同时假设
和
相互独立.那么
其中, 将概率分为了两部分,一部分对应的ReLU导数为0,一部分对应的ReLU导数为1 (且这两部分假设都是50%的可能). 公式(16)表示对于一个的取值, 有一半概率对应ReLU导数为0,一般对应为1. 根据(2)式又得
(18)式也可以通过(10)式用类似的方法求出. 那么,
所以,按照前向推导的方法,最后得出的公式是
按照前向传播最后的示例, 此处的应该为