一、简介
ACL2017年中,腾讯AI-lab提出了Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN)。论文中提出了一种基于word-level级别的网络-DPCNN,由于上一篇文章介绍的TextCNN 不能通过卷积获得文本的长距离依赖关系,而论文中DPCNN通过不断加深网络,可以抽取长距离的文本依赖关系。实验证明在不增加太多计算成本的情况下,增加网络深度就可以获得最佳的准确率。
DPCNN结构
究竟是多么牛逼的网络呢?我们下面来窥探一下模型的芳容。
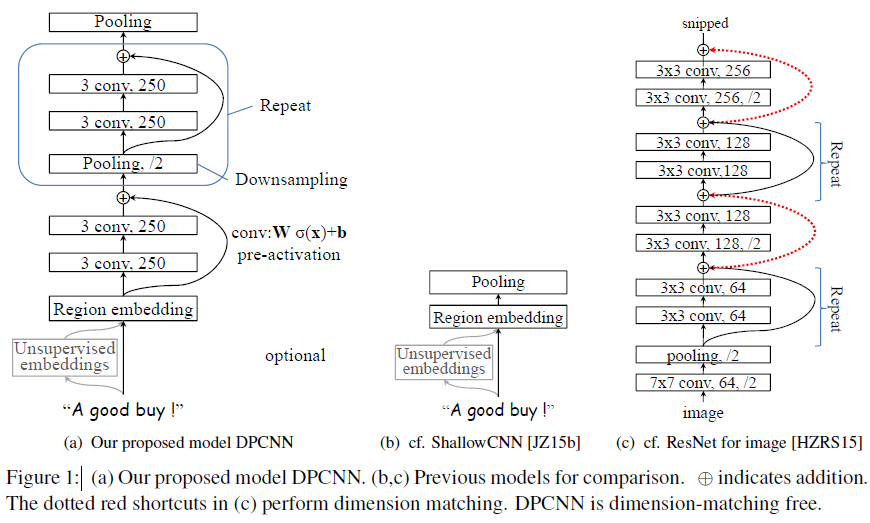
DPCNN结构细节
模型是如何通过加深网络来捕捉文本的长距离依赖关系的呢?下面我们来一一道来。为了更加简单的解释DPCNN,这里我先不解释是什么是Region embedding,我们先把它当作word embedding。
等长卷积
首先交代一下卷积的的一个基本概念。一般常用的卷积有以下三类:
假设输入的序列长度为n,卷积核大小为m,步长(stride)为s,输入序列两端各填补p个零(zero padding),那么该卷积层的输出序列为(n-m+2p)/s+1。
(1) 窄卷积(narrow convolution): 步长s=1,两端不补零,即p=0,卷积后输出长度为n-m+1。
(2) 宽卷积(wide onvolution) :步长s=1,两端补零p=m-1,卷积后输出长度 n+m-1。
(3) 等长卷积(equal-width convolution): 步长s=1,两端补零p=(m-1)/2,卷积后输出长度为n。如下图所示,左右两端同时补零p=1,s=3。
池化
那么DPCNN是如何捕捉长距离依赖的呢?这里我直接引用文章的小标题——Downsampling with the number of feature maps fixed。
作者选择了适当的两层等长卷积来提高词位embedding的表示的丰富性。然后接下来就开始 Downsampling (池化)。再每一个卷积块(两层的等长卷积)后,使用一个size=3和stride=2进行maxpooling进行池化。序列的长度就被压缩成了原来的一半。其能够感知到的文本片段就比之前长了一倍。
例如之前是只能感知3个词位长度的信息,经过1/2池化层后就能感知6个词位长度的信息啦,这时把1/2池化层和size=3的卷积层组合起来如图所示
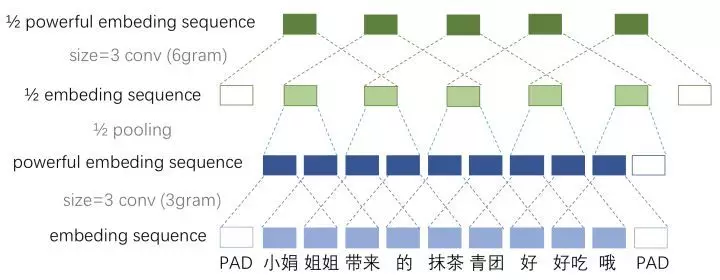
固定feature maps(filters)的数量
为什么要固定feature maps的数量呢?许多模型每当执行池化操作时,增加feature maps的数量,导致总计算复杂度是深度的函数。与此相反,作者对feature map的数量进行了修正,他们实验发现增加feature map的数量只会大大增加计算时间,而没有提高精度。
另外,夕小瑶小姐姐在知乎也详细的解释了为什么要固定feature maps的数量。有兴趣的可以去知乎搜一搜,讲的非常透彻。
固定了feature map的数量,每当使用一个size=3和stride=2进行maxpooling进行池化时,每个卷积层的计算时间减半(数据大小减半),从而形成一个金字塔。
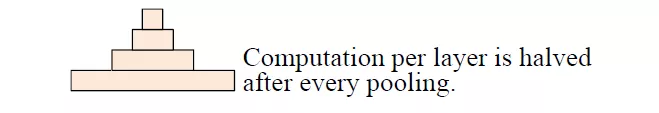
这就是论文题目所谓的 Pyramid。
好啦,看似问题都解决了,目标成功达成。剩下的我们就只需要重复的进行等长卷积+等长卷积+使用一个size=3和stride=2进行maxpooling进行池化就可以啦,DPCNN就可以捕捉文本的长距离依赖啦!
Shortcut connections with pre-activation
但是!如果问题真的这么简单的话,深度学习就一下子少了超级多的难点了。
(1) 初始化CNN的时,往往各层权重都初始化为很小的值,这导致了最开始的网络中,后续几乎每层的输入都是接近0,这时的网络输出没有意义;
(2) 小权重阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代好久才能启动;
(3) 就算网络启动完成,由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题。
当然,上述这几点问题本质就是梯度弥散问题。那么如何解决深度CNN网络的梯度弥散问题呢?当然是膜一下何恺明大神,然后把ResNet的精华拿来用啦! ResNet中提出的shortcut-connection/ skip-connection/ residual-connection(残差连接)就是一种非常简单、合理、有效的解决方案。
类似地,为了使深度网络的训练成为可能,作者为了恒等映射,所以使用加法进行shortcut connections,即z+f(z),其中 f 用的是两层的等长卷积。这样就可以极大的缓解了梯度消失问题。
另外,作者也使用了 pre-activation,这个最初在何凯明的“Identity Mappings in Deep Residual Networks上提及,有兴趣的大家可以看看这个的原理。直观上,这种“线性”简化了深度网络的训练,类似于LSTM中constant error carousels的作用。而且实验证明 pre-activation优于post-activation。
整体来说,巧妙的结构设计,使得这个模型不需要为了维度匹配问题而担忧。
Region embedding
同时DPCNN的底层貌似保持了跟TextCNN一样的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。
另外,作者为了进一步提高性能,还使用了tv-embedding (two-views embedding)进一步提高DPCNN的accuracy。
上述介绍了DPCNN的整体架构,可见DPCNN的架构之精美。本文是在原始论文以及知乎上的一篇文章的基础上进行整理。本文可能也会有很多错误,如果有错误,欢迎大家指出来!建议大家为了更好的理解DPCNN ,看一下原始论文和参考里面的知乎。
二、pytorch实现
1、DPCNN.py
# coding: UTF-8 import torch import torch.nn as nn import torch.nn.functional as F import numpy as np class Config(object): """配置参数""" def __init__(self, dataset, embedding): self.model_name = 'DPCNN' self.train_path = dataset + '/data/train.txt' # 训练集 self.dev_path = dataset + '/data/dev.txt' # 验证集 self.test_path = dataset + '/data/test.txt' # 测试集 self.class_list = [x.strip() for x in open( dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单 self.vocab_path = dataset + '/data/vocab.pkl' # 词表 self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果 self.log_path = dataset + '/log/' + self.model_name self.embedding_pretrained = torch.tensor( np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32')) if embedding != 'random' else None # 预训练词向量 self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备 self.dropout = 0.2 # 随机失活 self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练 self.num_classes = len(self.class_list) # 类别数 self.n_vocab = 0 # 词表大小,在运行时赋值 self.num_epochs = 20 # epoch数 self.batch_size = 128 # mini-batch大小 self.pad_size = 32 # 每句话处理成的长度(短填长切) self.learning_rate = 1e-3 # 学习率 self.embed = self.embedding_pretrained.size(1) if self.embedding_pretrained is not None else 300 # 字向量维度 self.num_filters = 250 # 卷积核数量(channels数) '''Deep Pyramid Convolutional Neural Networks for Text Categorization''' class Model(nn.Module): def __init__(self, config): super(Model, self).__init__() if config.embedding_pretrained is not None: self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False) else: self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1) self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.embed), stride=1) self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1) self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2) self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom self.relu = nn.ReLU() self.fc = nn.Linear(config.num_filters, config.num_classes) def forward(self, x): x = x[0] x = self.embedding(x) x = x.unsqueeze(1) # [batch_size, 250, seq_len, 1] x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1] x = self.padding1(x) # [batch_size, 250, seq_len, 1] x = self.relu(x) x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1] x = self.padding1(x) # [batch_size, 250, seq_len, 1] x = self.relu(x) x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1] while x.size()[2] > 2: x = self._block(x) x = x.squeeze() # [batch_size, num_filters(250)] x = self.fc(x) return x def _block(self, x): x = self.padding2(x) px = self.max_pool(x) x = self.padding1(px) x = F.relu(x) x = self.conv(x) x = self.padding1(x) x = F.relu(x) x = self.conv(x) x = x + px return x
2、run.py
# coding: UTF-8 import time import torch import numpy as np from importlib import import_module from utils import build_dataset, build_iterator, get_time_dif from train_eval import train, init_network import argparse parser = argparse.ArgumentParser(description='Text Classification') parser.add_argument('--model', default = "DPCNN", type=str, help='choose a model: DPCNN, BERT') parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained') parser.add_argument('--word', default=False, type=bool, help='True for word, False for char') args = parser.parse_args() if __name__ == '__main__': dataset = 'gongqing' # 数据集 # 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:random embedding = 'embedding_SougouNews.npz' if args.embedding == 'random': embedding = 'random' model_name = args.model # DPCNN, Transformer x = import_module('models.' + model_name) config = x.Config(dataset, embedding) np.random.seed(1) torch.manual_seed(1) torch.cuda.manual_seed_all(1) torch.backends.cudnn.deterministic = True # 保证每次结果一样 start_time = time.time() print("Loading data...") vocab, train_data, dev_data, test_data = build_dataset(config, args.word) train_iter = build_iterator(train_data, config) dev_iter = build_iterator(dev_data, config) test_iter = build_iterator(test_data, config) time_dif = get_time_dif(start_time) print("Time usage:", time_dif) # train config.n_vocab = len(vocab) model = x.Model(config).to(config.device) init_network(model) print(model.parameters) train(config, model, train_iter, dev_iter, test_iter)
3、train_eval.py
# coding: UTF-8 import numpy as np import torch import torch.nn as nn import torch.nn.functional as F from sklearn import metrics import time from utils import get_time_dif from tensorboardX import SummaryWriter # 权重初始化,默认xavier def init_network(model, method='xavier', exclude='embedding', seed=123): for name, w in model.named_parameters(): if exclude not in name: if 'weight' in name: if method == 'xavier': nn.init.xavier_normal_(w) elif method == 'kaiming': nn.init.kaiming_normal_(w) else: nn.init.normal_(w) elif 'bias' in name: nn.init.constant_(w, 0) else: pass def train(config, model, train_iter, dev_iter, test_iter): start_time = time.time() model.train() optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate) # 学习率指数衰减,每次epoch:学习率 = gamma * 学习率 # scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9) total_batch = 0 # 记录进行到多少batch dev_best_loss = float('inf') last_improve = 0 # 记录上次验证集loss下降的batch数 flag = False # 记录是否很久没有效果提升 writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime())) for epoch in range(config.num_epochs): print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs)) # scheduler.step() # 学习率衰减 for i, (trains, labels) in enumerate(train_iter): outputs = model(trains) model.zero_grad() loss = F.cross_entropy(outputs, labels) loss.backward() optimizer.step() if total_batch % 100 == 0: # 每多少轮输出在训练集和验证集上的效果 true = labels.data.cpu() predic = torch.max(outputs.data, 1)[1].cpu() train_acc = metrics.accuracy_score(true, predic) dev_acc, dev_loss = evaluate(config, model, dev_iter) if dev_loss < dev_best_loss: dev_best_loss = dev_loss torch.save(model.state_dict(), config.save_path) improve = '*' last_improve = total_batch else: improve = '' time_dif = get_time_dif(start_time) msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}' print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve)) writer.add_scalar("loss/train", loss.item(), total_batch) writer.add_scalar("loss/dev", dev_loss, total_batch) writer.add_scalar("acc/train", train_acc, total_batch) writer.add_scalar("acc/dev", dev_acc, total_batch) model.train() total_batch += 1 if total_batch - last_improve > config.require_improvement: # 验证集loss超过1000batch没下降,结束训练 print("No optimization for a long time, auto-stopping...") flag = True break if flag: break writer.close() test(config, model, test_iter) def test(config, model, test_iter): # test model.load_state_dict(torch.load(config.save_path)) model.eval() start_time = time.time() test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True) msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}' print(msg.format(test_loss, test_acc)) print("Precision, Recall and F1-Score...") print(test_report) print("Confusion Matrix...") print(test_confusion) time_dif = get_time_dif(start_time) print("Time usage:", time_dif) def evaluate(config, model, data_iter, test=False): model.eval() loss_total = 0 predict_all = np.array([], dtype=int) labels_all = np.array([], dtype=int) with torch.no_grad(): for texts, labels in data_iter: outputs = model(texts) loss = F.cross_entropy(outputs, labels) loss_total += loss labels = labels.data.cpu().numpy() predic = torch.max(outputs.data, 1)[1].cpu().numpy() labels_all = np.append(labels_all, labels) predict_all = np.append(predict_all, predic) acc = metrics.accuracy_score(labels_all, predict_all) if test: report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4) confusion = metrics.confusion_matrix(labels_all, predict_all) return acc, loss_total / len(data_iter), report, confusion return acc, loss_total / len(data_iter)
4、utils.py
# coding: UTF-8 import os import torch import numpy as np import pickle as pkl from tqdm import tqdm import time from datetime import timedelta MAX_VOCAB_SIZE = 10000 # 词表长度限制 UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号 def build_vocab(file_path, tokenizer, max_size, min_freq): vocab_dic = {} with open(file_path, 'r', encoding='UTF-8') as f: for line in tqdm(f): lin = line.strip() if not lin: continue content = lin.split(' ')[0] for word in tokenizer(content): vocab_dic[word] = vocab_dic.get(word, 0) + 1 vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size] vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)} vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1}) return vocab_dic def build_dataset(config, ues_word): if ues_word: tokenizer = lambda x: x.split(' ') # 以空格隔开,word-level else: tokenizer = lambda x: [y for y in x] # char-level if os.path.exists(config.vocab_path): vocab = pkl.load(open(config.vocab_path, 'rb')) print(vocab) else: vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1) pkl.dump(vocab, open(config.vocab_path, 'wb')) print(f"Vocab size: {len(vocab)}") def load_dataset(path, pad_size=32): contents = [] with open(path, 'r', encoding='UTF-8') as f: for line in tqdm(f): lin = line.strip() if not lin: continue content, label = lin.split(' ') words_line = [] token = tokenizer(content) seq_len = len(token) if pad_size: if len(token) < pad_size: token.extend([PAD] * (pad_size - len(token))) else: token = token[:pad_size] seq_len = pad_size # word to id for word in token: words_line.append(vocab.get(word, vocab.get(UNK))) contents.append((words_line, int(label), seq_len)) return contents # [([...], 0), ([...], 1), ...] train = load_dataset(config.train_path, config.pad_size) dev = load_dataset(config.dev_path, config.pad_size) test = load_dataset(config.test_path, config.pad_size) return vocab, train, dev, test class DatasetIterater(object): def __init__(self, batches, batch_size, device): self.batch_size = batch_size self.batches = batches self.n_batches = len(batches) // batch_size self.residue = False # 记录batch数量是否为整数 if len(batches) % self.n_batches != 0: self.residue = True self.index = 0 self.device = device def _to_tensor(self, datas): x = torch.LongTensor([_[0] for _ in datas]).to(self.device) y = torch.LongTensor([_[1] for _ in datas]).to(self.device) # pad前的长度(超过pad_size的设为pad_size) seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device) return (x, seq_len), y def __next__(self): if self.residue and self.index == self.n_batches: batches = self.batches[self.index * self.batch_size: len(self.batches)] self.index += 1 batches = self._to_tensor(batches) return batches elif self.index >= self.n_batches: self.index = 0 raise StopIteration else: batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size] self.index += 1 batches = self._to_tensor(batches) return batches def __iter__(self): return self def __len__(self): if self.residue: return self.n_batches + 1 else: return self.n_batches def build_iterator(dataset, config): iter = DatasetIterater(dataset, config.batch_size, config.device) return iter def get_time_dif(start_time): """获取已使用时间""" end_time = time.time() time_dif = end_time - start_time return timedelta(seconds=int(round(time_dif)))