Prometheus使用案例
1.计算CPU的使用率
1.显示CPU使用率,按模式细分并按使用的时间进行显示
node_cpu_seconds_total
2.首先计算每种CPU模式的每秒使用率。PromQL有一个irate函数,用于计算范围向量中时间序列增加的每秒即时速率。
irate(node_cpu_seconds_total{job="node"}[5m])
这将在irate函数中使用node_cpu_seconds_total指标并查询5分钟范围的数据。它将从node左火速返回每个CPU在每种模式下的列表,表示为5分钟范围内的每秒速率。
3.聚合不同CPU和模式间的指标
# node主机已经使用的CPU占比,
avg(irate(node_cpu_seconds_total{job="node"}[5m])) by (instance) * 100
结果:
{instance="192.168.1.121:9100"} 12.125000000006903
# node主机未使用的CPU占比
100 - avg(irate(node_cpu_seconds_total{job="node"}[5m])) by (instance) * 100
{instance="192.168.1.121:9100"} 87.8749999999931
现在将irate函数放在avg聚合中,并添加了一个由instance标签聚合的by子句。
但上面的指标还不太准备,它仍然包含idle值,并且没有表示成百分比的形式。
2.CPU饱和度
在主机上获得CPU饱和的一种方法是跟踪平均负载,实际上它是将主机上的CPU数量考虑在内的一段时间内的平均运行队列长度。平均负载少于CPU的数量通常是正常的,长时间内超过该数字的平均值则表示CPU已经饱和。
要产看主机的平均负载,可以使用node_load指标,他们显示了1分钟、5分钟和15分钟的平均负载。比如使用1分钟的平均负载:node_load1
1.计算主机上的CPU数量,可以使用count聚合实现
count by (instance)(node_cpu_seconds_total{mode="idle"})
结果:
{instance="192.168.1.121:9100"} 4
2.接下来将此计算与node_load1指标结合起来
# 过去一分钟cpu负载大于cpu总数的两倍
node_load1 > on (instance) 2 * count by (instance)(node_cpu_seconds_total{node="idle"})
这里我们查询的是1分钟的负载超过主机CPU数量的两倍的结果。
3.内存使用率
Node Exporter的内存指标按内存的类型和使用率进行细分。可以在node_memory未前缀的指标列表找到它们。
# 查看主机上的总内存
node_memory_MenTotal_bytes
# 主机上的可用内存
node_memory_MemFree_bytes
# 缓冲缓存中的内存
node_memory_Buffers_bytes
# 页面缓存中的内存
node_memory_Cached_bytes
因此,将node_memory_MemFree_bytes、node_memory_Cached_bytes、node_memory_Buffers_bytes 指标的值相加,代表主机上的可用内存。然后将使用这个值和node_memory_MemTotal_bytes 指标来计算可用内存的百分比。
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes *100
在上面,将三个内存相加,从总数中减去它们然后再除以总数,最后乘以100将其转换为百分比。
4.内存饱和度
还可以通过检查内存和磁盘的读写来监控内存饱和度。可以使用从/proc/vmstat收集的两个Node Exporter指标。
node_vmstat_pswpin:系统每秒从磁盘读到内存的字节数。
node_vmstat_pswpout:系统每秒从内存写到磁盘的字节数。
两者都是自上次启动以来的字节数,以KB为单位。
为了获得饱和度指标,对每个指标计算每一分钟的速率,将两个速率相加,然后乘以1024获得字节数。
1024 * sum by (instance) ((rate(node_vmstat_pgpgin[1m]) + rate(node_vmstat_pgpgout[1m])))
然后,可以对此设置图形化展示或者警报,以识别行为不当的应用程序主机。
5.磁盘使用率
对于磁盘,只测量磁盘使用情况而不是使用率、饱和充或错误。这是因为在大多数情况下,它是对可视化和警报最有用的数据。
node_filesystem_size_bytes
node_filesystem_size_bytes 指标显示了被监控的每个文件系统挂载的大小。可以使用与内存指标类似的查询来生成在主机上使用的磁盘空间百分比。
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} *100
与内存指标不同,在每个主机上的每个挂载点都有文件系统指标。所以添加了mountpoint标签,特别是根文件系统"/"挂载。这将在每台主机上返回该文件系统磁盘使用指标。
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} *100
如果想要或需要监控特定挂载点,那么我们可以为其添加查询。比如要监控/data挂载点,可以使用:
(node_filesystem_size_bytes{mountpoint="/data"} - node_filesystem_free_bytes{mountpoint="/data"}) / node_filesystem_size_bytes{mountpoint="/data"} *100
或者可以使用过正则表达式匹配多个挂载点:
(node_filesystem_size_bytes{mountpoint=~"/|/run"} - node_filesystem_free_bytes{mountpoint=~"/|/run"}) / node_filesystem_size_bytes{mountpoint=~"/|/run"} *100
可以使用predict_linear函数来构建在未来什么时间会耗尽磁盘空间。
predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 4*3600) < 0
上面是指定根文件系统,还可以通过指定作业名称或使用正则表达式来选择所有文件系统。
predict_linear(node_filesystem_free_bytes{job="node"}[1h], 4*3600) < 0
在上面中,我们选择一小时的时间窗口,并将此时间序列快照放在predict_linear函数中。该函数使用简单的线性回归,根据以前的增长情况来确定文件系统何时会耗尽空间。该函数参数包括一个范围向量,即一小时窗口,以及未来需要预测的时间点。这些都是以秒为单位的,因此这里使用4*3600秒,即四小时。最后<0,即文件系统空间不足。
因此,如果基于最后一小时的增长历史记录,文件系统将在接下来的四个小时内用完,那么查询将返回一个负数,然后我们可以用它来触发警报。
6.服务状态
现在来看看来自systemd收集器的数据,他向我们展示了主机上的服务状态和其它各种systemd配置。服务的状态在node_systemd_unit_state(或者直接up,也能查出来指标状态)指标中暴露出来。对于收集的每个服务和服务状态都有一个指标。
1.查询docker的服务
node_systemd_unit_state{name="docker.service"}
此查询为每个潜在的服务和状态(failed,inactive,active)的组合生成指标,其中表示当前服务状态的指标的值为1.我们可以通过state标签来进一步缩小搜索范围。
node_systemd_unit_state{name="docker.service",state="active"}
或者可以搜索值为1的所有指标,这将返回当前服务的状态:
node_systemd_unit_state{name="docker.service"} == 1
2.生产使用注意事项
# 1. 如果是使用的服务配置文件如下:那么无法收集服务状态:
/usr/bin/node_exporter --collector.textfile.directory /var/lib/node_exporter/textfile_collector --collector.systemd --collector.systemd.unit-whitelist="(docker|sshd|rsyslog).service" --no-colletor.softnet
# 2. 如果使用上面的命令直接启动的话,则没有问题。
# 3. 如果没有加--no-collector.softnet的话,则会报如下错误。
level=error ts=2020-03-27T06:22:07.283Z caller=collector.go:161 msg="collector failed" name=softnet duration_seconds=0.000685365 err="could not get sorfnet statistics: failed to parse /proc/net/softnet_stat: 10 columns were detected,but 11 were expected."
7.源数据及UP指标
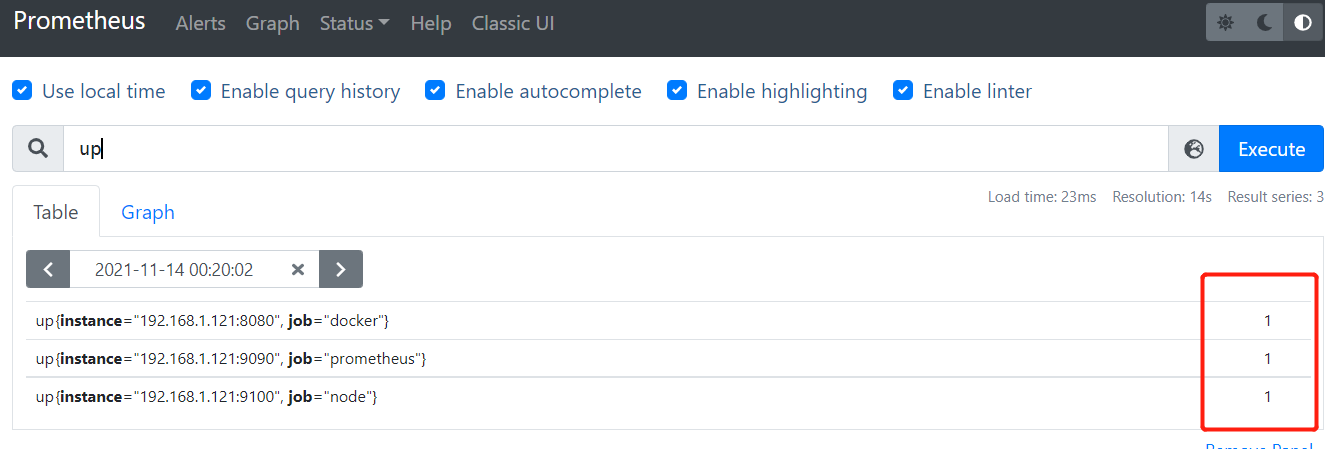
1. UP指标
用于监控特定节点状态的另一个有用指标:up指标。对于每个实例抓取,Prometheus都会在以下时间序列中存储样本。
up指标:
up{job="<job-name>",instance="<instance-id>"}
如果实例是健康的,则指标设置为1,即数据抓取成功返回。如果抓取失败,则设置为0,指标使用作业名称job和时间序列的实例instance来进行标记。
2.metadata指标
最后,使用Node Exporter的textfile收集器来查看我们创建的metadata指标。
metadata{role="docker_server",datacenter="SH"} 1
因此,如果我们想要查询哪些主机不在上海的,就可以直接用下列语句查询。
metadata{datacenter != "NJ"}
3.向量匹配
我们还可以使用metadata指标来进行向量匹配,向量匹配可以使用任何的PromQL二次运算符。向量匹配尝试针对左侧向量中的每个元素在右侧向量中查找对应的匹配元素。
目前有两种向量匹配:一对一和多对一,或一对多
3.1一对一匹配
一对一匹配从每一侧找到唯一匹配的条目对。如果两个条目具有完全相同的标签和值,则它们是一对一匹配的。你可以考虑使用ignoring修饰符忽略掉特定标签,或者使用on修饰符来减少显示的标签列表。我们来看一个例子
node_systemd_unit_state{name="docker.service"} ==1 and on (instance ,job) metadata{datacenter="SH"}
这将选择所有node_systemd_unit_state指标中name标签为docker.service并且值为1的指标。然后使用On修饰符将返回的标签列表减少到metadata指标的instance和job标签,并且datacenter标签的值为SH。
3.2 多对一和一对多皮皮额
多对一和一对多匹配是其中一侧向量中的元素与另一侧向量中的多个元素相匹配。这些匹配使用group_right修饰符显示指定,其中left或right是为了确定哪个向量具有更高的基数。但它们通常不会被使用。大多数情况下,一对一匹配就足够了。
8.查询的持久化
可以通过以下三种方式使查询持久化:
1)记录规则:根据查询创建新指标。
2)警报规则:从查询生成警报。
3)可视化规则:使用Grafana等仪表板可视化查询。
之前的查询都可以交替应用这三种机制,因为所有这些机制都能理解和执行PromQL查询。
1.记录规则
记录规则是一种根据已有时间序列计算新时间序列(特别是聚合时间序列)的方法,我们这样做是为了:
1)跨多个时间序列生成聚合。
2)预先计算消耗大的查询。
3)产生可用于生成警报的时间序列。
2.配置记录规则
记录规则存储在Prometheus服务器上,位于Prometheus服务器加载的文件中。规则是自动计算的,频率则由Prometheus.yml配置文件中的evaluation_interval参数控制。
global:
scrape_interval: 15s
evaluation_interval: 15s
在Prometheus.yaml文件的同一文件夹中创建一个名为rules的子文件夹,用于保存记录规则。在这里为节点创建一个名为node_rules.yml的文件。Prometheus规则与Prometheus配置一样是通过YAML编写的。
cd /etc/prometheus/
mkdir -p rules
cd rules/
touch node_rules.yml
编辑Prometheus.yml文件,添加内容如下:
rule_files:
- "rules/node_rules.yml"
2.1添加记录规则
1.一个记录CPU 5分钟速率的案例
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job="node",mode="ide"}[5m])) by (instance) * 100
记录规则在规则组中定义,这里的规则组叫作node_rules。规则组名称在服务器中必须是唯一的。规则组内的规则以固定间隔顺序执行。默认情况下,这是通过全局evaluate_interval来控制的,但你可以使用interval子句在规则组中覆盖。
规则组内规则执行的顺序性质意味着你可以在后续规则中使用之前创建的规则。这允许你根据规则创建指标,然后再之后的规则中重用这些指标。这仅在规则组内适用,规则组是并行运行的,因此不建议跨组适用规则。
这意味着可以将记录规则用作参数,例如,可能希望创建一个带有阈值的规则。然后,可以在规则中设置一次阈值并重复使用多次。如果你需要更改阈值,则只需要更改一处即可。
groups:
- name: node_rules
interval: 10s
rules:
接下来,我们有一个名为rules的YAML块,它包含该组的记录规则。每条规则都包含一条记录,告诉Prometheus将新的时间序列命名为什么。你应该仔细命名规则,以便快速识别它们代表的内容。
一般推荐的格式是:
level:metirc:operations
其中level表示聚合级别,以及规则输出的标签。metric是指标名称,除了使用rate()或irate()函数玻璃_total计数器之外,应该保持不变。这样的命名可以帮助你更轻松地找到新指标。最后,operations是应用于指标的操作列表,一般最新的操作放在前面。
所以我们的CPU查询命名为:
instance:node_cpu:avg_rate5m
然后使用一个expr字段来保存生成新时间序列的查询。
我们还可以添加labels块以向新时间序列添加新标签。根据规则创建的时间序列会继承用于创建它们的时间序列的相关标签,但你也可以添加或覆盖标签。例如:
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job="node",mode="ide"}[5m])) by (instance) * 100
labels:
metric_type: aggregation
接下来,再创建一些查询:
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job="node",mode="ide"}[5m])) by (instance) * 100
- record: instance:node_memory_usage:percentage
expr: (node_memory_MemTotal_bytes-(node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes *100
- record: instance:root:node_filesystem_usage:percentage
expr: (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
在重启Prometheus服务器或进行SIGHUP以激活新规则。这将为每个规则创建一个新的时间序列。一小段时间后,应该能在服务器上找到新的时间序列。
[info]通过将SIGHUP信号发送到Prometheus进程上或在Microsoft Windows上重启,可以在运行时重新加载规则文件,重新加载仅在规则文件格式良好时才有效。Prometheus服务器附带一个名为Prometheus的使用程序,可以帮助检测文件规则文件。
随后可以在web界面的rules中查看定义的规则:
