1问题描述
下面这个式子是交叉熵损失函数,p代表预测值,p*代表标签的真实值。

如果p=sigmoid(x),损失函数L对x求导可以得到下面的这个式子:
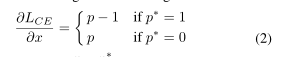
我们定义了g这一变量,它的含义是梯度范数

g的值代表了样本预测的难易程度,g的值越大,代表预测越困难。预测值p与真实值p*越接近,g的值越小,下面这张图展示了梯度范数与样本数量的关系,发现范数小的例子占绝大多数,这就表示简单样本的数量很多,它们产生的累计贡献就在模型更新过程中有巨大的影响,由于这部分的样本很容易判别,这部分的参数更新并不会改善模型的判断能力,使得模型的训练变得低效。
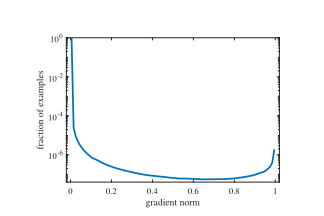
由此提出了梯度均衡机制,根据梯度范数的分布比例进行一个相应的标准化,使各种类型的样本对模型参数更新有均衡的贡献,就是对不同样本产生的梯度进行一个加权,改变它们的贡献量。对于某个特定的样本,计算它的梯度范数,然后计算其在单元区域内的样本密度,样本密度越大,就说明样本数量越多,那么在计算损失函数的时候就让他乘以一个较小的数,降低他对模型参数更新的贡献。
2梯度密度
梯度密度的计算公式如下所示:
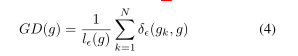
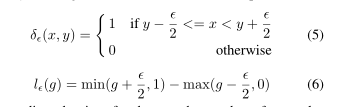
其中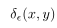 代表了以 样本的梯度范数g以
代表了以 样本的梯度范数g以![]() 为中心的区域内样本的数量,下面的l函数代表了区域的长度,用单元区域的样本数量除以模长的区域长度就是梯度密度。g的梯度密度取决于以g为中心的样本的数量,并用区域的有效长度进行归一化。
为中心的区域内样本的数量,下面的l函数代表了区域的长度,用单元区域的样本数量除以模长的区域长度就是梯度密度。g的梯度密度取决于以g为中心的样本的数量,并用区域的有效长度进行归一化。
3梯度协调参数
梯度协调参数的计算公式:
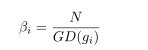
![]() 其中
其中 表示对第i个样本的梯度密度的一个标准化。如果梯度密度越大,那么β的值越小,让其在损失函数中占的权重越小,相反梯度密度越小,β的值越大。如果梯度密度函数服从均匀分布,
表示对第i个样本的梯度密度的一个标准化。如果梯度密度越大,那么β的值越小,让其在损失函数中占的权重越小,相反梯度密度越小,β的值越大。如果梯度密度函数服从均匀分布,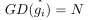 β的值为1.
β的值为1.
4GHM-C Loss
这个是分类算法中的损失函数,计算每个样本的损失值之后乘以一个梯度协调参数,使得每个梯度对样本参数的更新变得均衡。
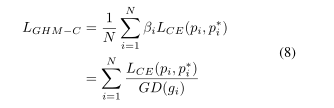
5Unit Region Approximation(单元区域近似)
5.1单元区域近似
如果有k个样本,在计算梯度协调参数的时候就要对K个样本都要计算一次梯度密度,这样计算量太大,为了降低复杂度,采用了近似计算的方法。将梯度范数划分为M个区域,分别计算这M个区域的梯度密度,如果样本的梯度范数g属于M中的某个区域,就将这个区域的梯度密度作为该样本的梯度密度。
定义![]() ,Rj代表了某个区域的样本数量
,Rj代表了某个区域的样本数量 ![]()
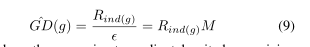
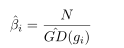

5.2EMA(指数移动平均)
基于小批量的统计方法通常会遇到一个问题,当多个极端数据在一个小批量时会产生严重的噪声,训练也会不稳定,通常采用指数移动平均的方法来解决这一问题。
![]() 代表在第t次迭代时,第j个单元区域的样本数量,
代表在第t次迭代时,第j个单元区域的样本数量, 是移动平均数(里面存储的是之前计算的梯度密度,在计算当前批次的梯度密度的时候,它所占的比例会非常大,当前批次所统计的梯度区域内的样本数量占一小部分,这样当前批次该梯度密度范围内的数量对梯度密度的统计计算影响不是很大,即使这个数量统计的非常不准确,比较极端,由于只占一小部分,对梯度密度的计算影响也不会很大。)
是移动平均数(里面存储的是之前计算的梯度密度,在计算当前批次的梯度密度的时候,它所占的比例会非常大,当前批次所统计的梯度区域内的样本数量占一小部分,这样当前批次该梯度密度范围内的数量对梯度密度的统计计算影响不是很大,即使这个数量统计的非常不准确,比较极端,由于只占一小部分,对梯度密度的计算影响也不会很大。)
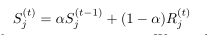

使用了EMA之后,梯度密度会更加平滑,对极端数据不敏感。