摘要
基于方面的情绪分析旨在确定在线评论中针对特定方面的情绪极性。最近的研究采用了基于注意的神经网络模型来隐式地将方面与意见词联系起来。然而,由于语言的复杂性和一个句子中多个方面的存在,这些模型经常混淆连接。在本文中,我们通过有效的语法信息编码来解决这个问题。首先,我们定义了一个统一的面向方面的依赖树结构,该结构通过对普通的依赖解析树进行整形和剪枝来植根于目标方面。然后,我们提出了一种关系图注意网络(R-GAT)来编码新的情感预测树结构。在SemEval 2014和Twitter数据集上进行了大量实验,实验结果证实,我们的方法可以更好地建立方面和观点词之间的联系,因此,图形注意网络(GAT)的性能显著提高。
1 介绍
直觉上,将各个方面与它们各自的观点词汇联系起来是这项任务的核心。为了实现这一目标,最新的努力求助于各种各样的注意机制,并报告了令人信服的结果。然而,由于语言形态和句法的复杂性,这些机制偶尔会失败。我们用一篇真实的评论来说明这个问题。So delicious was the noodles but terrible vegetables,,其中“糟糕”一词更接近面条,而不是美味,而且在其他一些评论中可能会出现糟糕的面条现象,这使得这两个词密切相关。因此,在评估面条的时候,注意力会给terrible更高的权重。
其他一些努力明确地利用句子的句法结构来建立联系。其中,早期的尝试依赖于手工制作的语法规则(邱等人,2011年;刘等人,2013年),尽管它们受到规则数量和质量的影响。然后使用基于依赖关系的解析树来提供更全面的语法信息。为此,可以通过递归神经网络(RNN)从叶子到根对整个依赖树进行编码(Lakkaraju等人,2014年;Dong等人,2014年;Nguyen和Shirai,2015年;Wang等人,2016a),或者可以计算内部节点距离,并将其用于注意力权重衰减(He等人,2018a)。最近,人们探索了图形神经网络(GNN)来从依赖树中学习表示(Zhang等人,2019;Sun等人,2019b;Huang和Carley,2019)。存在着缺点,第一,方面和观点词之间的依赖关系会被忽略。其次,根据经验,解析树只有一小部分与此任务相关,不需要对整个树进行编码(Zhang et al.,2018;He et al.,2018b)。最后,编码过程依赖于树,使得批处理操作在优化过程中不方便。
在本文中,我们重新审视了语法信息,并声称揭示与任务相关的语法结构是解决上述问题的关键。我们提出了一种新的面向方面的依赖树结构,分三步构造。首先,我们使用一个普通的解析器获得句子的依赖树。其次,我们重塑依赖树,使其在所讨论的目标方面生根。最后,对树进行修剪,只保留与方面有直接依赖关系的边。这样一个统一的树结构不仅使我们能够关注方面和潜在观点词之间的联系,而且有利于批处理和并行操作。然后,我们提出了一个关系图注意网络(RGA T)模型来编码新的依赖树。R-GA T将图注意网络(GA T)推广到带标记边的图的编码。对SemEval 2014和Twitter数据集进行了广泛的评估,实验结果表明,R-GA T显著提高了GA T的性能。它还实现了优于基线方法的性能。
贡献:
我们提出了一种面向方面的树结构,通过重塑和修剪普通的依赖树来关注目标方面。
我们提出了一个新的GAT模型来编码依赖关系,并建立方面和观点词之间的联系。
2 相关工作
基于方面的情绪分析(ABSA)的最新研究工作利用基于注意的神经模型来检查目标方面周围的单词。它们可以被认为是利用句子结构的一种隐式方法,因为观点词通常出现在距离方面不远的地方。这些方法带来了可喜的进展。其中,Wang等人(2016b)提出使用基于注意的LSTM来识别与目标方面相关的重要情绪信息。
Chen等人(2017年)引入了一种多层注意机制,以捕捉关于方面的远程意见词。出于类似的目的,Tang等人(2016)采用了具有多跳注意和外部记忆的记忆网络。Fan等人(2018年)提出了一个包含细粒度和粗粒度注意的多粒度注意网络。预先训练的语言模型BERT(Devlin et al.,2018)在包括ABSA在内的许多分类任务中取得了成功。例如,Xu等人(2019年)使用了一个额外的语料库对BERT进行后训练,并证明了其在方面提取和ABSA方面的有效性。Sun等人(2019a)通过构造辅助句将ABSA转化为句子对分类任务。
其他一些努力试图直接将句法信息包含在ABSA中。由于方面通常被认为是这项任务的核心,因此在每个目标方面和其他单词之间建立句法联系至关重要。邱等人(2011)手动定义了一些句法规则,以确定方面和潜在观点词之间的关系。Liu等人(2013)利用这些句法规则获得了部分对齐链接,并提出了一个部分监督的词对齐模型来提取意见目标。之后,为这项任务探索了神经网络模型。Lakkaraju等人(2014年)使用递归神经网络(RNN)对单词表示进行分层编码,并联合提取方面和情感。在另一项工作中,Wang等人(2016a)将递归神经网络与条件随机场(CRF)相结合。此外,Dong等人(2014)提出了一种自适应递归神经网络(AdaRNN),通过依赖树上的语义组合,将单词的情感自适应地传播到目标方面。Nguyen等人(2015年)进一步将句子的依赖树和成分树与短语递归神经网络(PhraseRNN)相结合。在一种更简单的方法中,他等人(2018a)使用依赖树中的相对距离进行注意力权重衰减。他们还表明,有选择地关注上下文单词的一小部分可以获得令人满意的结果。
最近,结合依赖树的图神经网络在ABSA中显示出了诱人的效果。Zhang et al.(2019)和Sun et al.(2019b)提出使用图卷积网络(GCN)从依赖树学习节点表示,并将其与其他特征一起用于情感分类。出于类似的目的,Huang和Carley(2019)使用图形注意网络(GA T)明确建立单词之间的依赖关系。然而,这些方法通常忽略了会识别方面和观点词之间的联系的依赖关系。
3面向方面的依赖树
3.1方面、注意和句法
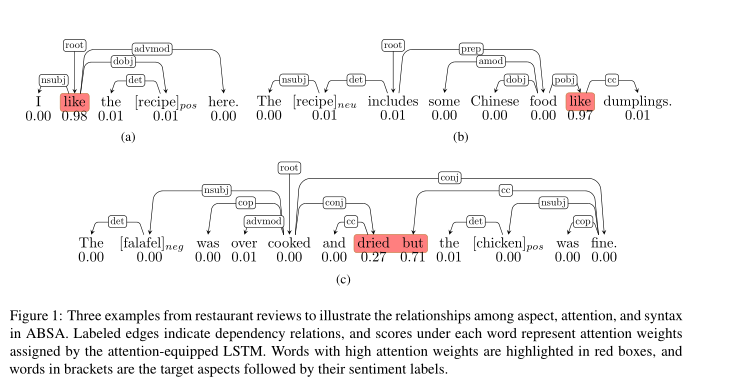
一个句子的句法结构可以通过依赖分析来揭示,这是一项生成依赖树来表示语法结构的任务。单词之间的关系可以用有向边和标签来表示。我们用三个例子来说明ABSA中方面、注意和语法之间的关系,如图1所示。在第一个例子中,like这个词被用作动词,它表达了对方面食谱recipe的积极情绪,基于注意的LSTM模型成功地注意到了这一点。然而,在第二个例子中,当它被用作介词时,模型仍然以较高的权重关注它,导致错误的预测。第三个例子展示了一个句子中有两个不同情绪极性的方面的情况。
对于方面chicken,LSTM模型错误地为单词but和dred分配了较高的注意权重,这导致了另一个预测错误。这些例子说明了基于注意力的模型在这项任务中的局限性。通过在方面和其他单词之间引入明确的句法关系,可以避免此类错误。例如,如果模型在第三个例子中注意到鸡肉和罚款之间的直接依赖关系,而不是but,则可能会有所不同。
3.2面向方面的依赖树
上述分析表明,与方面有直接联系的依赖关系可能有助于模型更加关注相关的意见词,因此应该比其他关系更重要。此外,如图1所示,依赖关系树包含丰富的语法信息,通常不在目标方面扎根。然而,ABSA的重点是目标方面,而不是树根。基于上述观察,我们提出了一种新的面向方面的依赖树结构,通过重塑原始依赖树以在目标方面生根,然后修剪树以丢弃不必要的关系。
算法1描述了上述过程。对于一个输入句子,我们首先应用依赖解析器来获得它的依赖树,其中rij是从节点i到j的依赖关系。然后,我们分三步构建一个面向方面的依赖树。首先,我们将目标方面放在词根处,其中多个单词方面被视为实体。其次,我们将直接连接到方面的节点设置为子节点,保留了原始的依赖关系。第三,其他依赖关系被丢弃,取而代之的是,我们将一个虚拟关系n:con(nconnected)从方面放置到每个对应的节点,其中表示两个节点之间的距离。2如果句子包含多个方面,我们为每个方面构建一个唯一的树。图2显示了从普通依赖树构建的面向方面的依赖树。这种面向方面的结构至少有两个优点。首先,每个方面都有自己的依赖树,受无关节点和关系的影响较小。
其次,如果一个方面包含多个单词,则依赖关系将在该方面聚合,而不像in(Zhang等人,2019;Sun等人,2019b)那样需要额外的池或注意操作。
上述观点的部分灵感来自于之前的发现(He等人,2018a;Zhang等人,2018;He等人,2018b),即集中在语法上接近目标方面的一小部分上下文词就足够了。我们的方法提供了一种直接建模上下文信息的方法。这种统一的树结构不仅使我们的模型能够关注方面和观点词之间的联系,而且有助于在训练期间进行批处理和并行操作。我们提出一个新的关系n:con的动机是,现有的解析器可能并不总是正确地解析句子,并且可能会错过与目标方面的重要连接。在这种情况下,关系n:con使新树更健壮。我们在实验中评估了这种新关系,结果证实了这一假设。
4关系图注意网络
为了对情感分析的新依赖树进行编码,我们提出了一种关系图注意网络(R-GA T),通过扩展图注意网络(GA T)(V eliˇckovi'c et al.,2017)对带有标记边的图进行编码
4.1 Graph Attention Network图注意力网络
依赖树可以用一个有n个节点的图G来表示,每个节点代表句子中的一个单词。G的边表示单词之间的依赖关系。节点i的邻域节点可以用Ni表示。GA T通过使用多头注意聚合邻域节点表示来迭代更新每个节点表示(例如,单词嵌入):
采用 dot-product attention计算节点之间的注意力
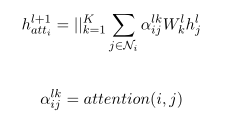
4.2 Relational Graph Attention Network关系图注意网络
GA T沿着依赖路径聚合邻域节点的表示。然而,这个过程没有考虑依赖关系,这可能会丢失一些重要的依赖信息。直觉上,具有不同依赖关系的邻域节点应该具有不同的影响。我们建议用额外的关系头来扩展原有的GA T。我们使用这些关系头作为关系智能门来控制来自邻域节点的信息流。这种方法的总体架构如图3所示。具体地说,我们首先将依赖关系映射为向量表示,然后计算一个关系头
提出的关系图注意网络(R-GA T)的结构,包括两种类型的多头注意机制,即注意头和关系头
R-GAT包含K个注意头和M个关系头。每个节点的最终表示形式由以下公式计算:
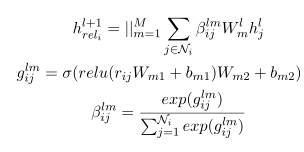
每个节点的最终表示形式由以下公式计算:

4.3 Model Training
我们使用BiLSTM对树节点的单词嵌入进行编码,并获得叶节点i的初始表示h0i的输出隐藏状态HI。然后,使用另一个BiLSTM对方面单词进行编码,其平均隐藏状态用作该根的初始表示h0a。在面向方面树上应用R-GA T后,它的根表示通过一个完全连接的softmax层,并映射到不同情感极性上的概率。
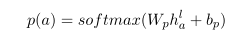
最后,标准交叉熵损失被用作我们的目标函数:
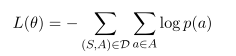
5 Experiments
在本节中,我们首先介绍用于评估的数据集和用于比较的基线方法。然后,我们报告了从不同角度进行的实验结果。最后,结合几个典型实例进行了误差分析和讨论。
5.1 Datasets
我们的实验使用了三个公众情绪分析数据集,其中两个是SemEval 2014任务中的笔记本电脑和餐厅评论数据集,第三个是Dong等人使用的Twitter数据集(Dong等人,2014)。这三个数据集的统计数据见表1。
5.1.1 Implementation Details实施细节
Biaffine解析器用于依赖项解析。依赖关系嵌入的维度设置为300。对于R-GA T,我们使用GLoV e的300维单词嵌入。对于R-GAT-BERT,我们使用预训练的BERT的最后隐藏状态来表示单词,并在任务中对它们进行微调。实验中使用了Bert的Pytorch实现。研究表明,R-GAT更喜欢[0.6,0.8]之间的高辍学率。至于R-GAT-BERT,在0.2左右的低辍学率下效果更好。我们的模型使用默认配置的Adam优化器进行训练
5.2 Baseline Methods
一些基于方面的情绪分析的主流模型用于比较,包括
我们的方法:R-GA T是我们的关系图注意网络。R-GAT BERT是我们的RGAT,BiLSTM被BERT取代,R-GAT的注意头也将被BERT取代。
5.3 Results and Analysis
5.3.1 Overall Performance
所有模型的总体性能如表2所示,从中可以看出一些观察结果。首先,R-GAT模型优于大多数基线模型。第二,在面向方面的依赖树结构中与关系头结合,GAT的性能可以显著提高。它还优于ASGCN和CDT的基线模型,后者也以不同的方式涉及句法信息。这证明了我们的R-GAT在编码句法信息方面更好。第三,基本的BERT已经可以大大超过所有现有的ABSA模型,这证明了这个大型预训练模型在这项任务中的威力。然而,在加入我们的R-GAT(R-GAT-BERT)之后,这个强大的模型看到了进一步的改进,并实现了新的技术水平。这些结果证明了我们的R-GAT在捕捉重要句法结构进行情感分析方面的有效性。
所有模型的总体性能如表2所示,从中可以看出一些观察结果。首先,R-GAT模型优于大多数基线模型。第二,在面向方面的依赖树结构中与关系头结合,GAT的性能可以显著提高。它还优于ASGCN和CDT的基线模型,后者也以不同的方式涉及句法信息。这证明了我们的R-GAT在编码句法信息方面更好。第三,基本的BERT已经可以大大超过所有现有的ABSA模型,这证明了这个大型预训练模型在这项任务中的威力。然而,在加入我们的R-GAT(R-GAT-BERT)之后,这个强大的模型看到了进一步的改进,并实现了新的技术水平。这些结果证明了我们的R-GAT在捕捉重要句法结构进行情感分析方面的有效性。
5.3.2 Effect of Multiple Aspects
在一句话中出现多个方面对ABSA来说是非常典型的。为了研究多个方面的影响,我们挑选了一个句子中有多个方面的评论。每个方面都用其平均(手套式)单词嵌入来表示,句子的任何两个方面之间的距离都用欧几里德距离来计算。如果有两个以上的方面,则对每个方面使用最近的欧几里德距离。然后,我们选择三个模型(GAT、R-GAT、R-GAT-BERT)进行情绪预测,并在图4中绘制了不同距离范围下的纵横比精度。我们可以观察到,距离较近的方面往往会导致较低的准确度分数,这表明句子中语义相似性较高的方面可能会混淆模型。然而,通过我们的R-GAT,GAT和BERT都可以在不同的范围内得到改进,这表明我们的方法可以在一定程度上缓解这个问题。
5.3.3 Effect of Different Parsers不同解析器的影响
依赖解析在我们的方法中起着关键作用。为了评估不同解析器的影响,我们使用两个著名的依赖解析器:斯坦福解析器和比亚芬解析器,基于R-GA T模型进行了一项研究。表3显示了UAS和LAS度量中两个解析器的性能,以及它们在基于方面的情绪分析中的性能。
我们可以发现,更好的Biaffine解析器会导致更高的情感分类准确率。此外,这进一步意味着,虽然现有的解析器可以正确捕获大多数语法结构,但随着解析技术的进步,我们的方法有可能进一步改进。
5.3.4 Ablation Study消融实验
我们进一步进行了一项研究,以评估面向方面的依赖树结构和关系头的影响。我们给出了普通依赖树上的结果,以供比较。从表4中,我们可以看到,通过在所有三个数据集上使用新的树结构,R-GAT得到了改进,而GAT只在餐馆和Twitter数据集上得到了改进。
此外,在删除虚拟关系n:con后,R-GA T的性能显著下降。我们手动检查了错误分类的样本,发现其中大多数都是由于方面和它们的观点词之间的错误连接导致的不良解析结果。这项研究验证了添加n:con关系可以有效地缓解解析问题,并使我们的模型具有健壮性。在本文中,根据实证检验,最大数量为4。其他价值观也在探索中,但结果并没有更好。这可能表明,与目标方面有太长依赖距离的单词不太可能对这项任务有用
5.3.5 Error Analysis
为了分析现有ABSA模型(包括我们的模型)的局限性,我们从餐馆数据集中随机选择了100个由两个模型(R-GAT和R-GA T-BERT)错误分类的例子。通过调查这些糟糕的案例,我们发现背后的原因可以分为四类。如表5所示,主要原因是由于误导性的中立评论,其中大多数评论包括对目标方面的意见修饰语(单词),具有直接的依赖关系。第二类是由于理解困难,这可能需要深入的语言理解技巧,如自然语言推理。第三类是由建议引起的,这些建议只建议或不建议人们尝试,而句子中没有明显的暗示情感的线索。第四类是由双重否定表达引起的,这对于当前的模型来说也是困难的。通过错误分析,我们可以注意到,虽然目前的模型已经取得了令人瞩目的进展,但仍有一些复杂的句子超出了它们的能力。应该有更先进的自然语言处理技术和学习算法来进一步解决这些问题。
6 Conclusion
在本文中,我们提出了一种有效的方法来编码综合的语法信息,用于基于方面的情感分析。我们首先定义了一种新的面向方面的依赖树结构,通过重塑和剪枝一个普通的依赖解析树,使其在目标方面生根。然后,我们演示了如何使用关系图注意网络(R-GAT)对新的依赖树进行编码,以进行情感分类。在三个公共数据集上的实验结果表明,R-GAT可以更好地建立方面和观点词之间的联系,从而显著提高了GAT和BERT的性能。我们还进行了一项消融研究,以验证新的树结构和关系头的作用。最后,对错误预测的示例进行了错误分析,从而得出了对该任务的一些见解。