论文: Accurate, Large MiniBatch SGD:Training ImageNet in 1 Hour
因为目前的 network 和 dataset 越来越大,随之而来的是training times的不断攀升。为了加快网络的训练,采用 distributed synchronous SGD , 将 SGD minibatch 划分到一个同步工作池内进行训练。
因为 distributed 的原因,minibatch size的增大,本paper采用的linear scaling rule对learning rate同时的放大。
Linear Scaling Rule:When the minibatch size is multiplied by k, multiply the learning rate by k.
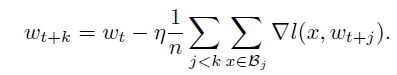
在其他 hyper parameter不变的情况下,N' = k * N, 可以达到多个minibatch size在一次实现对网络的update。
Warmup method:
Constant warmup: 在train前几个epoch(一般前5 epochs)时采用较小的constant learning rate,但是对于大的learning rate,constant warmup不能很好的初始化网络。
gradual warmup: 在 training的前几个 epoch,逐渐将learning rate由小到大的提高,让training在开始的时候健康的收敛。
Batch Normalization:
在 distributed training情况下,每一个per-work的sample可以看成是每一个minibatch,相互之间是独立的。所以 underlying loss function可以不变。
BN statistics不应该在all workers之间交叉计算,不仅为了减少交流,也为保持为了优化的同样的underlying loss function。
distributed SGD 对其他hyper parameter的影响:
1, weight decay:scaling the cross-entropy loss is not equivalent to scaling the learning rate 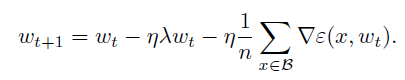
cross-entropy loss是 sample-dependent term,而regularization是weight-dependent term。
2, Momentum correction: Apply momentum correction after changing learning rate if using

3, Gradient aggregation: Normalize the per-worker loss by total minibatch size kn, not per-worker size n.
4, Data shuffling: Use a single random shuffling of the training data (per epoch) that is divided amongst all k workers.
在同一个worker内部,多个GPU的,则使用NCCL,进行多个GPU内部的buffer统一计算。
worker之间的通信交流:
对于该distributed SGD,只有Gradient Aggregation才需要all-worker之间的通信交流,在这里使用了两种算法 the recursive halving and doubling algorithm 和 bucket algorithm (ring algorithm)。
其中 halving/doubling algorithm有两步骤:reduce-scatter 和 all-gather,在 reduce-scatter阶段,使用两两servers组成pair,进行buffer的交换,如0和1,2和3, server0 发送第二半的buffer给server1,同时接受来自server1的第一半的buffer。
all-gather则使用类似树形结构对所有的 server 进行Gradient的gather。
实验部分:
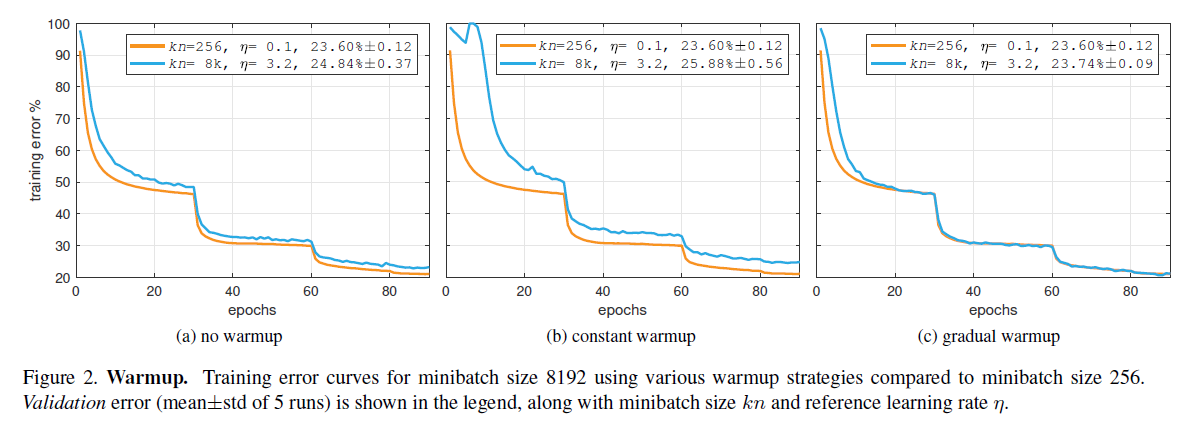
warmup: Large minibatch sizes are challenged by optimization difficulties in early training.
if the optimization issues are addressed, there is no apparent generalization degradation observed using large minibatch training.
distributed SGD的时间消耗:
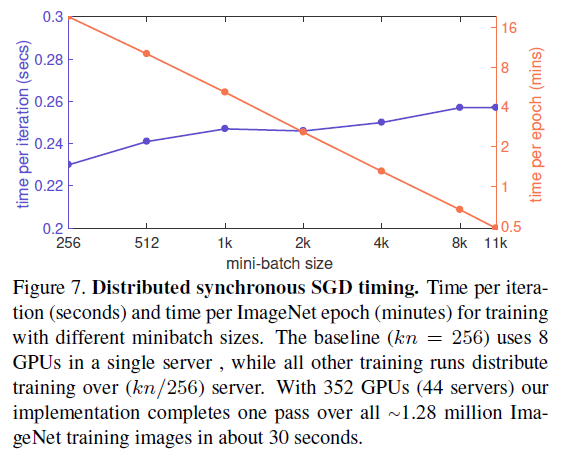
本人观点: 给予很多 deep network一个分布式计算的理论和可行性验证。