使用Docker-compose实现Tomcat+Nginx负载均衡
nginx反向代理原理
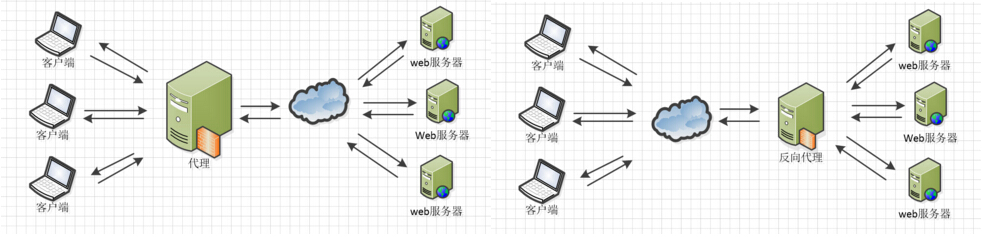
使用nginx代理tomcat
项目结构
├── docker-compose.yml
├── nginx
│ └── default.conf
├── tomcat1
│ └── index.html
├── tomcat2
│ └── index.html
└── tomcat3
└── index.html
为了区分是哪一个服务器,为3只tomcat分别创建了3个index.html。
nginx配置文件
upstream tomcats {
server ctc1:8080; # 主机名:端口号
server ctc2:8080; # tomcat默认端口号8080
server ctc3:8080; # 默认使用轮询策略
}
server {
listen 2420;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
docker-compose.yml
由于设置了upstream,nginx的启动依赖于tomcat,可以用depends_on实现。
version: "3.8"
services:
nginx:
image: nginx
container_name: cngx
ports:
- 80:2420
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: ctc1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: ctc2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: ctc3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
负载均衡测试
轮询策略
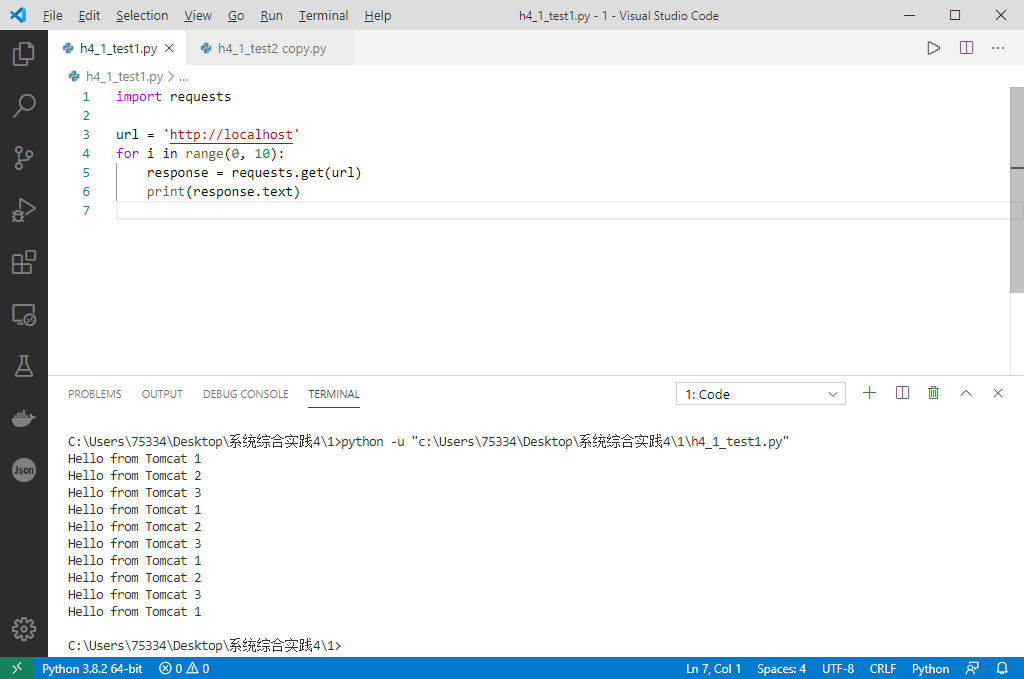
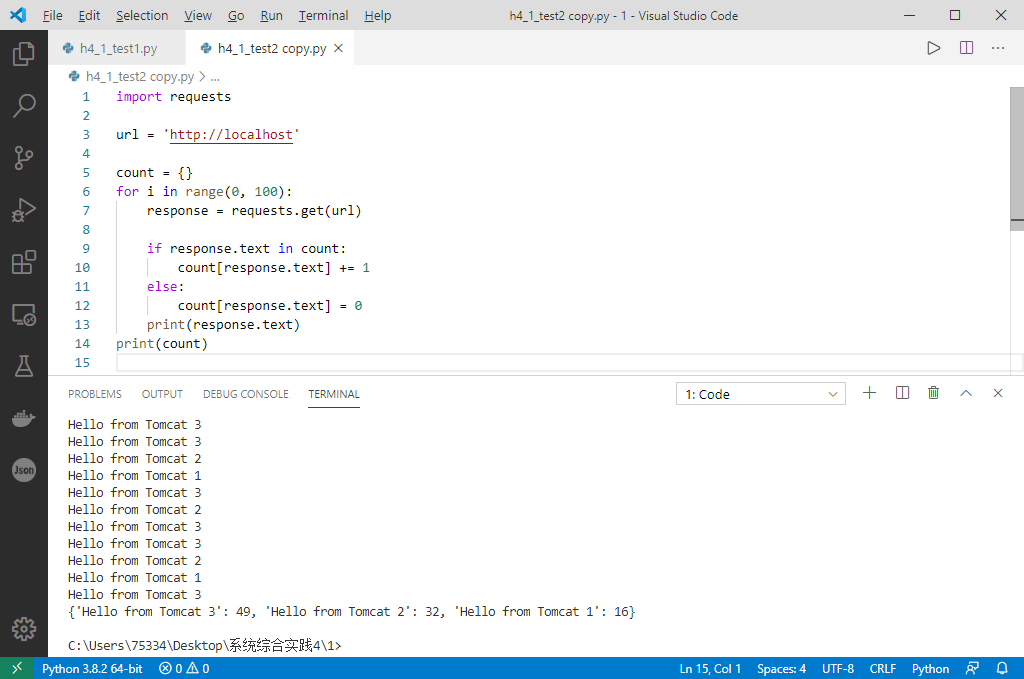
权重策略
修改nginx配置文件:
upstream tomcats {
server ctc1:8080 weight=1;
server ctc2:8080 weight=2;
server ctc3:8080 weight=3;
}
...
重启nginx容器:
docker restart cngx
使用Docker-compose部署javaweb运行环境
在上面的基础上,添加数据库容器,然后把javaweb打包成WAR,放在tomcat的webapps目录下即可。
项目结构
├── docker-compose.yml
├── mariadb
│ ├── Dockerfile
│ ├── docker-entrypoint.sh
│ └── schema.sql
├── nginx
│ └── default.conf
└── tomcat
├── Dockerfile
├── ROOT.war
└── wait-for-it.sh
MariaDB
Dockerfile for mariadb
FROM mariadb
LABEL author=qyanzh
# mysql的工作位置
ENV WORK_PATH /usr/local/
# 定义会被容器自动执行的目录
ENV AUTO_RUN_DIR /docker-entrypoint-initdb.d
#复制schema.sql到/usr/local
COPY schema.sql /usr/local/
#把要执行的shell文件放到/docker-entrypoint-initdb.d/目录下,容器会自动执行这个shell
COPY docker-entrypoint.sh $AUTO_RUN_DIR/
#给执行文件增加可执行权限
RUN chmod a+x $AUTO_RUN_DIR/docker-entrypoint.sh
docker-entrypoint.sh
#!/bin/bash
mysql -uroot -p1234 << EOF
source /usr/local/schema.sql;
schema.sql
create database db_example;
-- Creates the new database
create user 'springuser' @'%' identified by 'ThePassword';
-- Creates the user
grant all on db_example.* to 'springuser' @'%';
-- Gives all privileges to the new user on the newly created database
Tomcat
javaweb应用的启动依赖于mariadb,仅用depends_on是无法实现的,因为对于docker来说,容器只要启动了,就算是启动成功。而对于javaweb应用来说,数据库需要能访问才算启动成功。容器启动和数据库能访问有一个时间差,所以就会导致javaweb应用启动失败。而应用启动失败不会导致tomcat退出,所以restart也就没用了。在StackOverflow上找到了一种方法是用health_check,也没用。最后终于找到了一个脚本wait-for-it.sh,可以很好的解决这个问题。
Dockerfile for tomcat
FROM tomcat
LABEL author=qyanzh
COPY ./wait-for-it.sh /usr/local/tomcat/bin/
RUN chmod +x /usr/local/tomcat/bin/wait-for-it.sh
CMD ["wait-for-it.sh", "cdb:3306", "--", "catalina.sh", "run"]
docker-compose.yml
version: "3.8"
services:
mariadb:
image: my-mariadb
container_name: cdb
restart: always
build:
context: ./mariadb
environment:
MYSQL_ROOT_PASSWORD: "1234"
nginx:
image: nginx
container_name: cngx
ports:
- 80:2420
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: ctc1
build:
context: ./tomcat
volumes:
- ./tomcat:/usr/local/tomcat/webapps
depends_on:
- mariadb
restart: always
tomcat02:
image: tomcat
container_name: ctc2
build:
context: ./tomcat
volumes:
- ./tomcat:/usr/local/tomcat/webapps
depends_on:
- mariadb
restart: always
tomcat03:
image: tomcat
container_name: ctc3
build:
context: ./tomcat
volumes:
- ./tomcat:/usr/local/tomcat/webapps
depends_on:
- mariadb
restart: always
JavaWeb
之前学过一点点SpringBoot,就用SpringBoot做了。有一个问题就是SpringBoot是自带Tomcat的,不能直接使用,需要做一些修改把自带的Tomcat去除掉,限于篇幅就不详细展开了,可以参考这里。SpringBoot的教程也放在了参考里。下面贴一些主要代码。
application.properties
spring.jpa.hibernate.ddl-auto=update
spring.datasource.url=jdbc:mysql://cdb:3306/db_example # 主机名修改为容器名
spring.datasource.username=springuser
spring.datasource.password=ThePassword
MainController.java
package com.example.accessingdatamysql;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
import javax.servlet.http.HttpServletRequest;
@Controller
@RequestMapping(path = "/demo")
public class MainController {
@Autowired
private UserRepository userRepository;
@PostMapping(path = "/add")
public @ResponseBody
String addNewUser(@RequestParam String name
, @RequestParam String email) {
User n = new User();
n.setName(name);
n.setEmail(email);
n = userRepository.save(n);
return "Saved. Your id is " + n.getId();
}
@PostMapping(path = "/update")
public @ResponseBody
String updateUser(@RequestParam Integer id,
@RequestParam String name
, @RequestParam String email) {
User n = userRepository.findById(id).orElse(null);
if (n != null) {
n.setName(name);
n.setEmail(email);
userRepository.save(n);
return "Updated successfully.";
} else {
return "Id doesn't exist";
}
}
@PostMapping(path = "/delete")
public @ResponseBody
String deleteUser(@RequestParam Integer id) {
if (userRepository.findById(id).orElse(null) != null) {
userRepository.deleteById(id);
return "Deleted.";
} else {
return "Id doesn't exist";
}
}
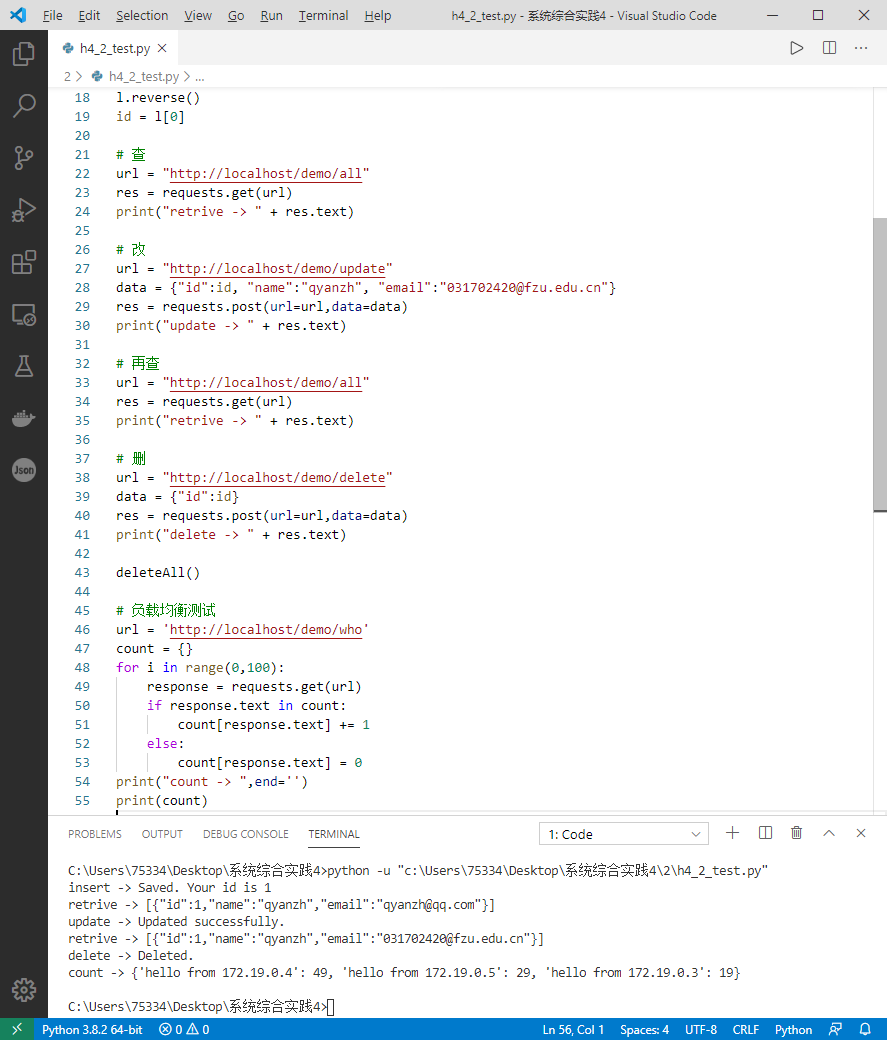
@GetMapping(path = "/all")
public @ResponseBody
Iterable<User> getAllUsers() {
return userRepository.findAll();
}
@GetMapping(path = "/who")
public @ResponseBody
String getPort(HttpServletRequest request) {
return "hello from " + request.getLocalAddr();
}
}
运行测试
wait-for-it
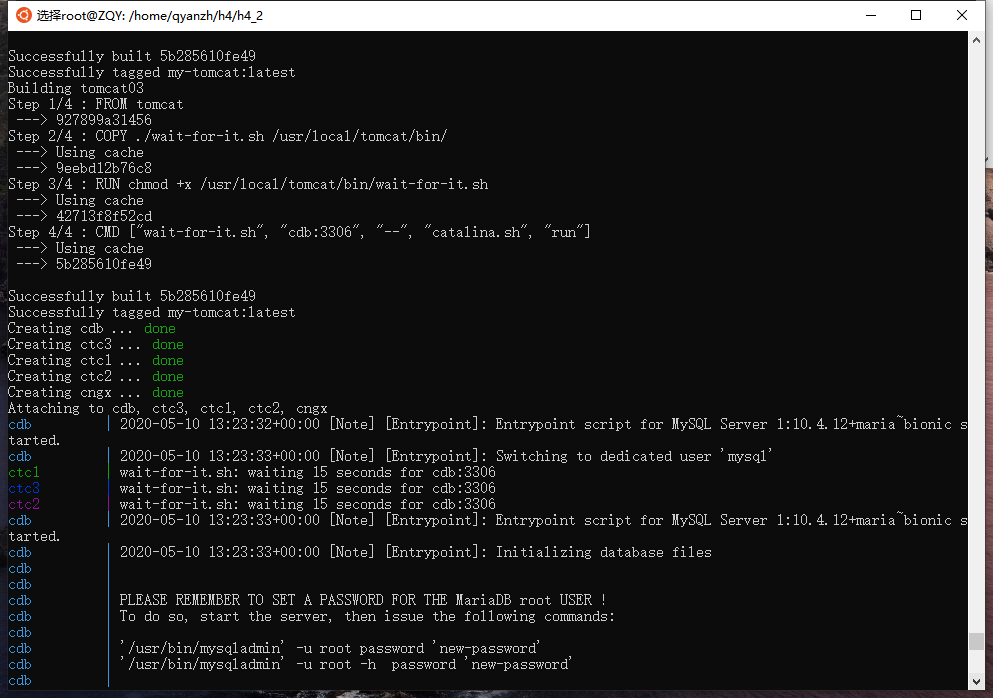
Tomcat+SpringBoot启动
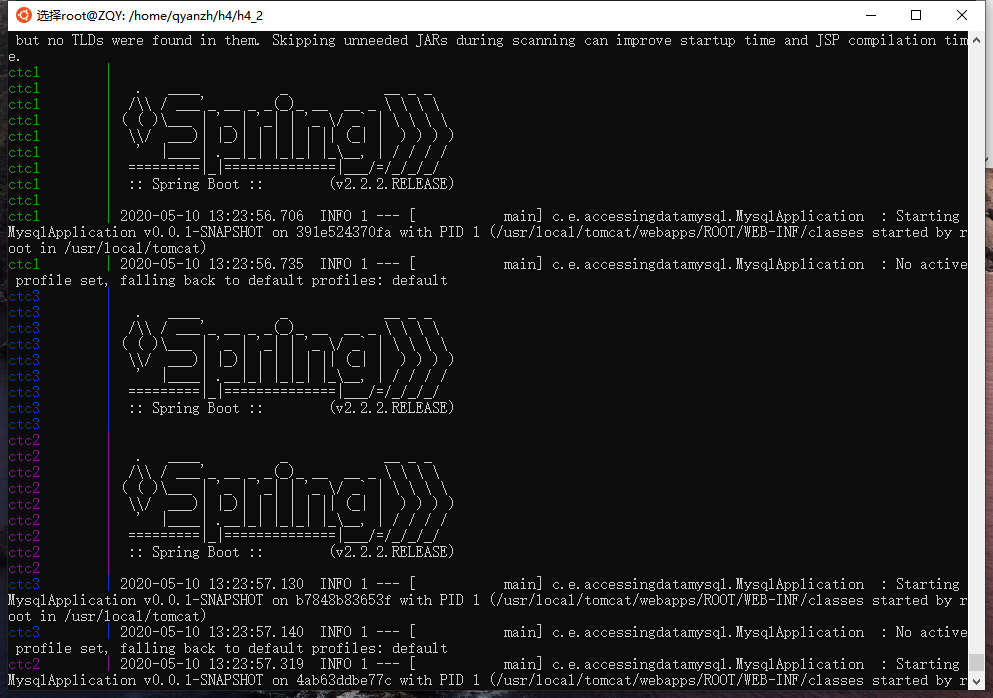
运行结果
偷个懒就不写前端了(主要是因为不会)。
使用Docker搭建大数据集群环境
目录结构
├── Dockerfile
├── build
│ └── hadoop-3.2.1.tar.gz
├── config
│ ├── hadoop-env.sh
│ ├── hdfs-site.xml
│ ├── mapred-site.xml
│ └── yarn-site.xml
└── sources.list
环境
-
Docker容器环境:
Ubuntu 20.04 LTS -
JDK版本:
openjdk 1.8.0_252 -
Hadoop版本:
Hadoop 3.2.1
环境搭建
ubuntu容器
建议换清华源(方便起见,把每行https改成http)。
FROM ubuntu
LABEL author=qyanzh
COPY ./sources.list /etc/apt/sources.list
docker build -t ubuntu .
docker run -it --name ubuntu ubuntu
现在就进入了ubuntu容器中。
ubuntu容器初始化
安装vim与ssh
apt-get update
apt-get install vim # 用于修改配置文件
apt-get install ssh # 分布式hadoop通过ssh连接
/etc/init.d/ssh start # 开启sshd服务器
vim ~/.bashrc # 在文件末尾添加上一行的内容,实现ssd开机自启
配置sshd 实现无密码登录
ssh-keygen -t rsa # 一直按回车即可
cd ~/.ssh
cat id_rsa.pub >> authorized_keys # 教程中的dsa应为拼写错误
安装JDK
注意:apt-get默认安装的是JDK11,而Hadoop 3.x目前仅支持Java 8,2.x支持Java 7/8。
博主一开始用的就是JDK11,途中遇到各种问题,最后才发现是JDK版本太高的原因,换到JDK8后各种问题都迎刃而解。哎说多了都是泪,以后一定要先查好版本依赖,避免这种低级错误。
apt-cache search jdk
apt-get install openjdk-8-jdk
vim ~/.bashrc # 在文件末尾添加以下两行,配置Java环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc # 使.bashrc生效
做完以上步骤之后另开一个终端存个档:
docker ps # 查看当前容器id
docker commit 容器ID ubuntu/jdk8 # 存档
docker run -it -v /home/qyanzh/h4/h4_3/build:/root/build --name ubuntu-jdk8 ubuntu/jdk8
# 挂载是为了读取Hadoop安装文件,也可以直接用docker cp命令
安装Hadoop
老师给的教程中的Hadoop版本为2.7.1,与本文使用的3.2.1配置略有不同;各版本的Hadoop可以在官网下载(binary→清华镜像)。
把下载好的Hadoop放在挂载的目录下并安装:
cd /root/build
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local
cd /usr/local/hadoop-3.2.1
./bin/hadoop version # 验证安装
输出如下:
Hadoop 3.2.1
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842
Compiled by rohithsharmaks on 2019-09-10T15:56Z
Compiled with protoc 2.5.0
From source with checksum 776eaf9eee9c0ffc370bcbc1888737
This command was run using /usr/local/hadoop-3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar
配置Hadoop集群
先进入配置文件存放目录:
cd /usr/local/hadoop-3.2.1/etc/hadoop
hadoop_env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ # 在任意位置添加
core-site.xml
vim core-site.xml
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hdfs-site.xml
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/datanode_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml
相比旧版多了三个配置,都设为hadoop目录即可。
vim mapred-site.xml
<?xml version="1.0" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
</configuration>
yarn-site.xml
vim yarn-site.xml
<?xml version="1.0" ?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
修改脚本
先进入脚本文件存放目录:
cd /usr/local/hadoop-3.2.1/sbin
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh,添加下列参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
注意放在合适的位置,比如function{}之后。
运行Hadoop集群
运行主机
做完以上步骤之后另开一个终端存个档,然后开启三个终端,分别运行集群中的主机:
docker commit 容器ID ubuntu/hadoop # 存档
# 第一个终端
docker run -it -h master --name master ubuntu/hadoop
# 第二个终端
docker run -it -h slave01 --name slave01 ubuntu/hadoop
# 第三个终端
docker run -it -h slave02 --name slave02 ubuntu/hadoop
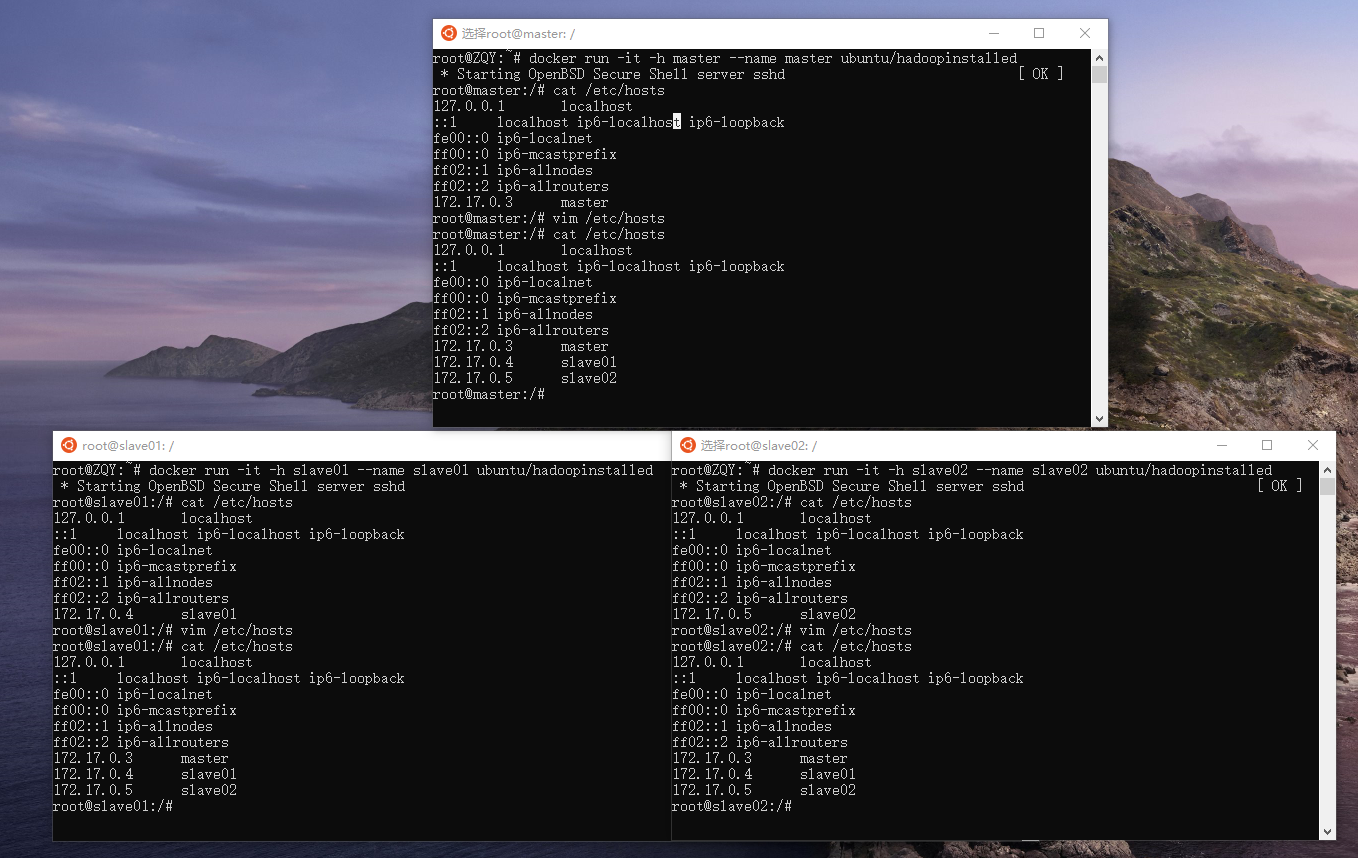
修改/etc/hosts
为三台主机配置对方的地址信息,他们才能找到彼此。三个终端分别修改/etc/hosts:
vim /etc/hosts # 查看各终端的IP并修改
内容均修改成如下形式即可,多余的可以删去:
x.x.x.x master
x.x.x.x slave01
x.x.x.x slave02
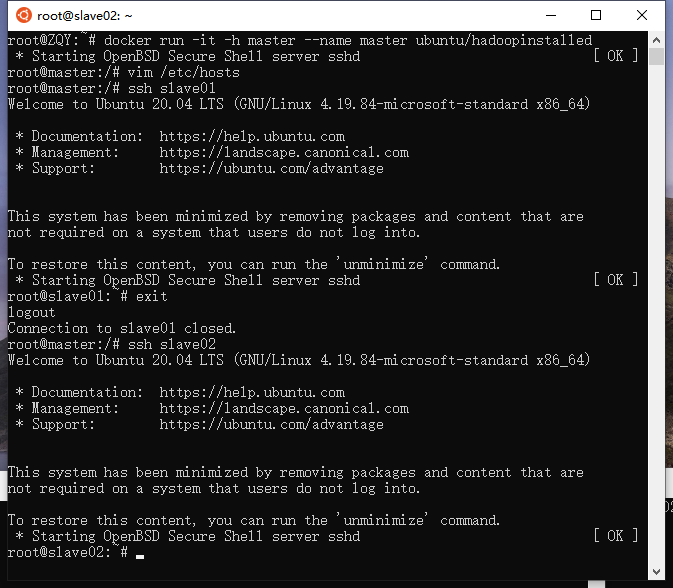
测试ssh
在master上,ssh相应主机即可访问目标主机,exit命令可以断开ssh连接。
ssh slave01 # 第一次使用需要输入yes
ssh slave02
修改workers
在master上:
vim /usr/local/hadoop-3.2.1/etc/hadoop/workers # 旧版为slaves
将localhost修改为:
slave01
slave02
测试Hadoop集群
在master上:
cd /usr/local/hadoop-3.2.1
bin/hdfs namenode -format # 格式化文件系统
sbin/start-dfs.sh # 开启NameNode和DataNode服务
bin/hdfs dfs -mkdir /user # 建立HDFS文件夹,也可以放到下面示例程序中进行
bin/hdfs dfs -mkdir /user/root
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input # 将xml复制到input下,作为示例程序输入
sbin/start-yarn.sh # 开启ResourceManager和NodeManager服务
jps # 查看服务状态
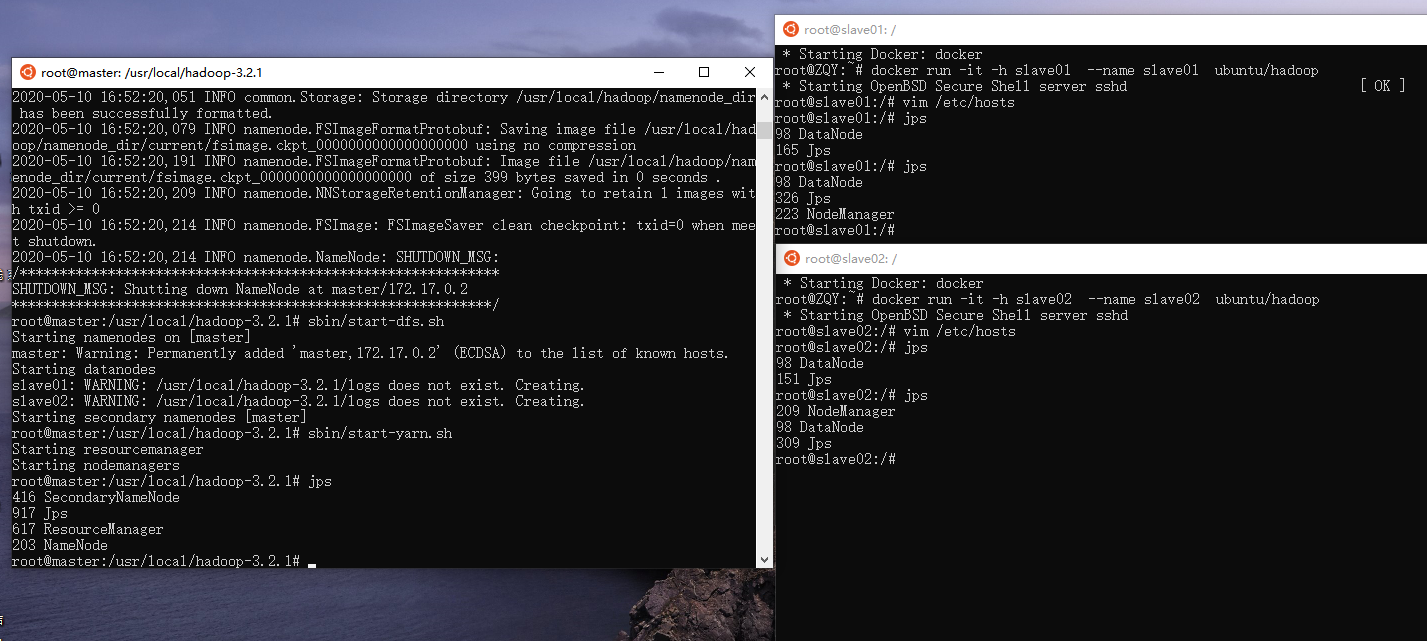
运行Hadoop示例程序
在master上:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+' # 运行示例
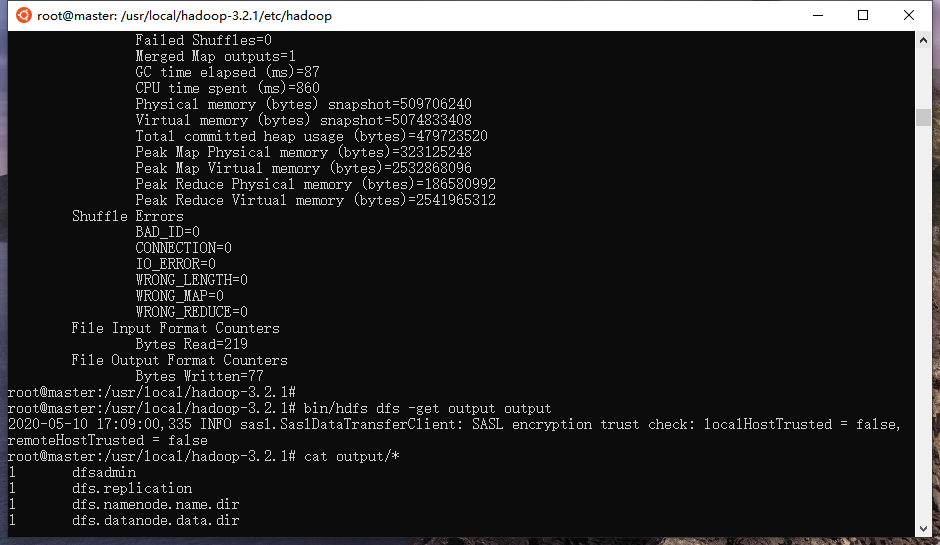
bin/hdfs dfs -get output output # 获取输出结果
cat output/* # 查看输出结果
sbin/stop-all.sh # 停止所有服务
运行结果:
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
其他问题及解决方法
Certificate verification failed
换源后apt-get update提示:
Certificate verification failed: The certificate is NOT trusted. The certificate issuer is unknown. Could not handshake: Error in the certificate verification.
把源中的https全换成http即可。
exec: "/usr/src/app/entrypoint.sh": permission denied"
复制脚本到容器需要给权限:
RUN chmod +x xxx.sh
Error: JAVA_HOME is not set and could not be found
export指令仅在本次登录有效,写入.bashrc中即可自动执行。参见安装JDK
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
start-all.sh在新版本已不推荐使用,用start-dfs.sh和start-yarn.sh替代即可。
bash: hadoop: command not found
Hadoop环境变量没配好,参考上面Java的配法,换一下路径即可。
没有slaves配置文件
Hadoop 3.x后slaves更名为workers。参见修改workers
ERROR: but there is no HDFS_NAMENODE_USER defined
新版需要在脚本中配置一些变量,参见修改脚本
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
新版需要在mapred-site.xml中多配置3个属性,参见mapred-site.xml
其他Hadoop错误的定位方法
运行脚本后四个服务(参见 测试Hadoop集群 的截图)如果有没跑起来的,可以通过查看hadoop3.2.1/logs下对应服务的日志来定位错误。一般看最下面一个的Caused By就行。
vim的一些操作
- Esc 进入正常模式
- Insert 进入插入模式
- 正常模式下输入
:进入命令模式 - dd 剪切整行
- :%d 删除所有行
- :q! 不保存退出
- :wq! 保存退出
用时和心得
完整源码已上传至GitHub
作业内容用时约16小时,博客约3小时。心得:遇错多看Log,不要瞎Debug。
参考
第4次实践作业 - 作业 - 2017级系统综合实践 - 班级博客 - 博客园
Nginx服务器之负载均衡策略(6种) - 左羽 - 博客园
Docker下Nginx+Tomcat实现负载均衡_运维_菲宇运维-CSDN博客
Getting Started | Building a RESTful Web Service
Getting Started | Accessing data with MySQL
Getting Started | Converting a Spring Boot JAR Application to a WAR
SpringBoot去除内嵌tomcat_Java_树欲静而风不止-CSDN博客
SpringBoot项目的创建和jar、war方式的部署_Java_铛铛当的博客-CSDN博客
docker-compose 启动依赖 wait-for-it.sh 实例_运维_金戈铁马-CSDN博客
vishnubob/wait-for-it: Pure bash script to test and wait on the availability of a TCP host and port
alpine - Docker-compose "exec: "/usr/src/app/entrypoint.sh": permission denied" - Stack Overflow
bash: hadoop: command not found_大数据_tucailing的专栏-CSDN博客
为什么hadoop没有slaves配置文件?_大数据_若闲小阁-CSDN博客
Hadoop Java Versions - Hadoop - Apache Software Foundation
Apache Hadoop 3.2.1 – Hadoop: Setting up a Single Node Cluster.