混淆矩阵
衡量一个分类器性能的更好的办法是混淆矩阵。它基于的思想是:计算类别A被分类为类别B的次数。例如在查看分类器将图片5分类成图片3时,我们会看混淆矩阵的第5行以及第3列。
为了计算一个混淆矩阵,我们首先需要有一组预测值,之后再可以将它们与标注值(label)进行对比。我们也可以在测试集上做预测,但是最好是先不要动测试集(测试集仅需要在最后的阶段使用,在我们有了一个准备上线的分类器后,最后再用测试集测试性能)。接下来,我们可以使用cross_val_predict() 方法:
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_train_pred.shape >(60000,)
与cross_val_score() 方法一样,cross_val_predict() 会执行K-折交叉验证,但是不会返回评估分数,而是返回在每个测试折上的预测值,加起来就是整个训练数据集的预测值。现在我们可以使用confusion_matricx() 方法获取混淆矩阵。直接传入label数据(y_train_5)以及预测数据(y_train_pred)即可:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred) >array([[53892, 687], [ 1891, 3530]])
在这个混淆矩阵中,每一行代表一个真实类别,每一列代表一个预测类别。第一行代表的是“非5”(亦称为negative class)图片:53892张图片被分类为“非5“类别(它们亦称为true negatives)。剩下的687 张图片被错误的分类为”非5“(亦称为false positives)。第二行代表的是”真5“(亦称为 positive class):1891张图片被错误地分类为”非5“类别(亦称为false negatives),剩下的3530 张图片被正确地分类为”真5“(亦称为true positives)。一个完美的分类器应该仅包含true positives 以及true negatives,所以它的混淆矩阵应该仅有主对角线上有非0数值,其他值应都为0。例如,假设我们有了以下一个完美的预测:
y_train_perfect_predictions = y_train_5 confusion_matrix(y_train_5, y_train_perfect_predictions) >array([[54579, 0], [ 0, 5421]])
混淆矩阵可以给我们提供很多信息,但是有时候我们可能需要一个更精准的指标。一个比较好的方式是:查看positive predictions的精准度。它也称为分类器的精度(precision),它的公式为:
Precision
Precision=TP / (TP + FP)
这里TP 是true positives 的数量,FP 是false positive 的数量。
对于精度,我们仍有办法去构造一个完整精度。比如假设测试集里全部是数字5,然后模型的逻辑是仅输出True。这样就可以构造一个 100% 精度的模型。所以精度(precision)一般与另一个指标一起用,这另一个指标称为回调(recall),也称为sensitivity或true positive rate(TPR):它是分类器正确分类positive 条目的比率,公式为:
Recall
TP / (TP+FN)
这里FN是false negatives的数目。
如果对混淆矩阵的这些概念比较模糊的话,可以看看下图:
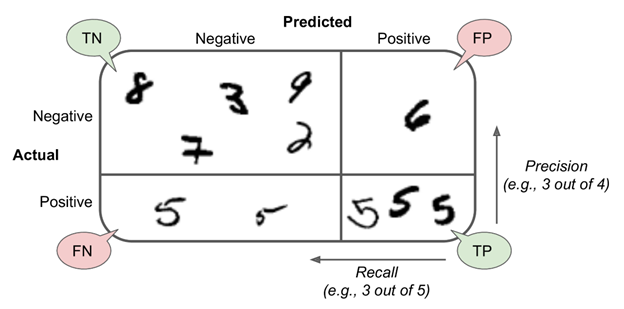
Precision与Recall
Sk-learn提供了一些方法用于计算分类器的各个指标,包括精准率(precision)与回调率(recall):
from sklearn.metrics import precision_score, recall_score print(precision_score(y_train_5, y_train_pred)) #3530/(3530+687) print(recall_score(y_train_5, y_train_pred)) #3530/(3530+1891) >0.8370879772350012 0.6511713705958311
从precision与recall来看,这个分类器的表现并不像之前准确度(accuracy)那样亮眼了。当这个分类器认为某张图片是数字5时,它仅有83.7% 的概率是正确的。并且它仅识别出了65.1%的数字5图片。
一般我们还会将precision和recall结合成一个指标:F1分数。特别是在需要使用一个简单的办法对比两个分类器时。F1分数是precision与recall的调和平均数(harmonic mean):
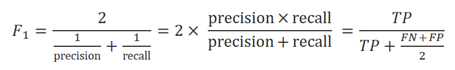
如果一个分类器的recall与precision分数都比较高的话,则最终才会得到一个较高的F1分数。其中任意一个recall或是precision比较低的话,F1分数都不会太高。
在sk-learn中,直接调用f1_score() 方法即可计算F1分数:
from sklearn.metrics import f1_score f1_score(y_train_5, y_train_pred) >0.7325171197343846
F1分数会比较倾向于那些precision值与recall值接近的分类器。不过这个需求并不是在任何场景下都是必须的,在一些场景下,我们可能更关心精准率,而在另一些场景下更关注回调率。例如,如果我们训练一个分类器,用于为孩子们检测一些健康的视频。在这个场景下,我们可能会更倾向于使用:一个可以更精准的判断视频是否为健康的视频(高精准),但是可能会误杀掉一些健康的视频(低回调)的分类器。而不是一个有着高回调,但是会让小部分不健康的视频通过的分类器。另一方面,假设我们训练一个判断监控里小偷的分类器,即使这个分类器只有30%的精准率(precision)也是可以的,只要是它有99%左右的回调率(recall),依然可以达到我们的需求(即使警报可能会响很多次,但是基本都会抓到小偷)。
不过可惜的是,precision与recall无法二者兼得:增加precision会降低recall,反之亦然。这个被称为精准/回调折中(precision/recall tradeoff)。
精准/回调折中(Precision/Recall Tradeoff)
为了理解这种折中,我们看一下SGDClassifier是如何做分类决策的。对每条数据,它首先根据决策方法,计算出一个分数,如果此分数大于某个阈值,则将这条数据分类为正类(positive class),反之则分类为负类(negative class)。
下图是一个例子,低分在左边,被分为负类,高分在右边,被分为正类。假设决策阈值的位置在正中间(下图中间的两个5之间):我们可以看到阈值右边有4个true positives(真正为数字5),以及1个false positive (真正为数字6)。所以,在这个阈值下,精准率precision是80%(4/5)。这个集合中一共有6个数字5,但是在这个阈值下,只检测出了4个,所以召回率recall是67%(4/6)。
现在假设我们升高这个阈值(将箭头向右移),则之前的那个数字6从false positive 变成了true negative,所以此时false positive 现在是0,precision是100%(3/3)。而之前的数字5 由true positive 变成了false negative,所以召回率recall现在是50%(3/6)。同样,减少阈值后,召回率会上升,但是精准率precision会下降。
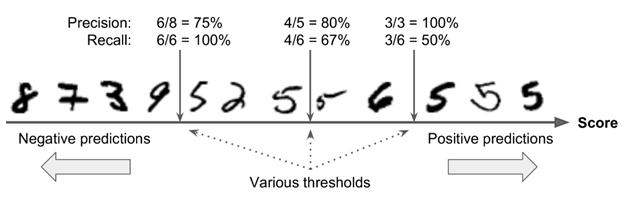
Sk-learn并不允许用户直接设置阈值,但是可以指定一个决策分数,用于做预测。之前我们是调用predict() 方法做预测,现在我们可以先使用 decision_function() 方法,它会返回每条数据的分数。然后我们可以根据这些分数,提供的阈值进行预测:
y_scores = sgd_clf.decision_function([X_test[0], X_test[1], X_test[2], X_train[0]]) y_scores >array([-8542.1753957 , -4410.49112461, -3416.59592945, 2164.22030239]) threshold = 0 y_demo_digit_pred = (y_scores > threshold) y_demo_digit_pred >array([False, False, False, True])
SGDClassifier 使用的是0作为阈值,所以上面的方法返回的结果与直接调用 predict() 的结果是一致的。下面我们可以试着改一下这个阈值:
threshold = 8000
y_demo_digit_pred = (y_scores > threshold) y_demo_digit_pred >array([False, False, False, False])
这个也证明了:提高阈值后,recall会下降。最后这张图片本来是数字5,并且在阈值为0的情况下,分类器可以将它正确识别。但是在阈值升高到8000后,此图片便被识别为“非数字5”。
现在,我们如何决定使用哪个阈值呢?首先我们需要获取训练数据中所有数据的得分。再次使用cross_val_predict() 方法即可,但是这次我们要指定它返回决策分数,而不是做预测:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method='decision_function') y_scores >array([ 1200.93051237, -26883.79202424, -33072.03475406, ..., 13272.12718981, -7258.47203373, -16877.50840447])
现在有了这些分数,我们可以计算在各种可能的阈值下,precision与recall的值,使用precision_recall_curve()方法:
from sklearn.metrics import precision_recall_curve precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
最后我们可以画出precision与recall的函数图,以threshold为因变量,使用matplotlib:
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], 'b--', label="Precision") plt.plot(thresholds, recalls[:-1], 'g--', label="Recall") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
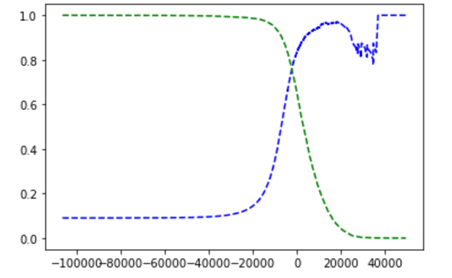
大家可能会好奇,为什么precision的图相较于recall的图抖动的更剧烈。这是因为:在阈值上升后,precision可能偶尔会下降(虽然一般它会上升)。为了便于理解,大家可以回看一下之前“精准/回调折中”里的那张图。假设我们的阈值设在最中间,然后下一个阈值只向右移动了一个单位,则precision从80%(4/5)下降到了75%(3/4)。而另一边,recall仅会在阈值增加的时候才会下降,所以它的曲线看起来更平滑。
另一个比较好的选择“精准/回调折中”的办法是直接画出precision对应于recall的图,如:
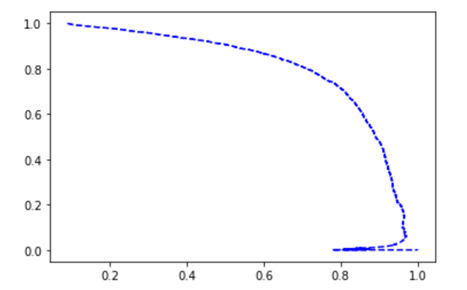
可以看到在大约recall在80% 左右的样子,precision开始急速下降。所以我们一般会选择一个它下降前的一个“精准/回调折中“(precision/recall tradeoff),例如在60%的回调左右。不过这个最终的决定取决于我们的项目需求。
下面假设我们定的目标是90%的precision。从第一副图我们可以得知,阈值大约为8000 左右。为了更精确地获取这个阈值,我们可以搜索满足90%精准率的最小阈值(np.argmax() 可以返回第一个最大值,在这个例子中就是第一个True值):
threshold_90_precision = thresholds[np.argmax(precisions >=0.90)]
threshold_90_precision
>3370
下一步,做决策。这次我们不再用predict() 方法,而是使用:
y_train_pred_90 = (y_scores >= threshold_90_precision)
y_train_pred_90
>array([False, False, False, ..., True, False, False])
然后我们检查一下这些预测的precision与recall:
precision_score(y_train_5, y_train_pred_90) >0.9000345901072293 recall_score(y_train_5, y_train_pred_90) >0.4799852425751706
现在我们就有了一个90%精准率的分类器!正如你所见,创建一个高精准率的分类器其实很简单,只需要设置更高的阈值即可。但是,如果一个分类器即使precision很高,而recall很低的话,这个分类器基本没太大用处。所以如果有人说,他的分类器达到了99%的精准率,那我们可以继续问问他“recall是多少?”
接下来我们还会继续介绍另一种性能衡量的办法: ROC曲线。它是另一种与Precision/Recall 曲线类似的曲线。