周五跟着虫师的博客学习了一下Python爬虫(爬取网页图片),然后到下班还没运行起来,后面请教博客底下留言板里的童鞋,是因为版本问题导致,虫师用的2.7版本,我用的是版本3,后面照着热心的网友写的修改了一下,本以为会好,然后还是没能跑起来,最终在周六的晚上在我同事的耐心指导下,由于几个空格问题,终于给运行成功了……(注:原谅小白由于各种语法,空格不熟悉等问题造成的这种低级错误),所以就想写进博客方便以后自己查看和更好的帮助其他跟我一样刚学习的Python的同学。
版本:Python3
开发工具:pycharm
注:如果是使用Python2的童鞋可以借鉴测试大牛虫师的博客: http://www.cnblogs.com/fnng/p/3576154.html#comment_tip
import urllib.request import re import chardet def getHtml(url): page=urllib.request.urlopen(url) html =page.read() return html def getImg(html): reg = r'src="(.+?.jpg)" pic_ext' imgre=re.compile(reg) encode_type=chardet.detect(html) html=html.decode(encode_type['encoding']) imglist=re.findall(imgre,html) x=0 for imgurl in imglist: urllib.request.urlretrieve(imgurl,'%s.jpg' %x) x+=1 return imglist html=getHtml("http://tieba.baidu.com/p/2460150866") print(getImg(html))
一、导入模块说明
urllib.request:获取web页面数据 re:正则表达式模块,用于后面代码中提取图片数据 chardet:用来识别编码模块
二、函数说明
第一个getHTML函数用于获取web数据。
urllib.open()方法用于打开一个URL地址;
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
返回一个html。
第二个getImg函数用于在获取的整个页面中筛选需要的图片连接。
reg正则表达式用于提取网页中包含.jpg的图片
re.compile 将正则表达式转换为模式对象,可以实现更有效率的匹配
chardet用来识别编码,encode方法再将此编码转换成字符串
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
第三个for循环用于获取网页中的图片。
for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1。
urllib.urlretrieve()方法,直接将远程数据下载到本地,保存的位置默认为程序的存放目录
程序运行完成,将在存在程序目录下看到下载到本地的文件。
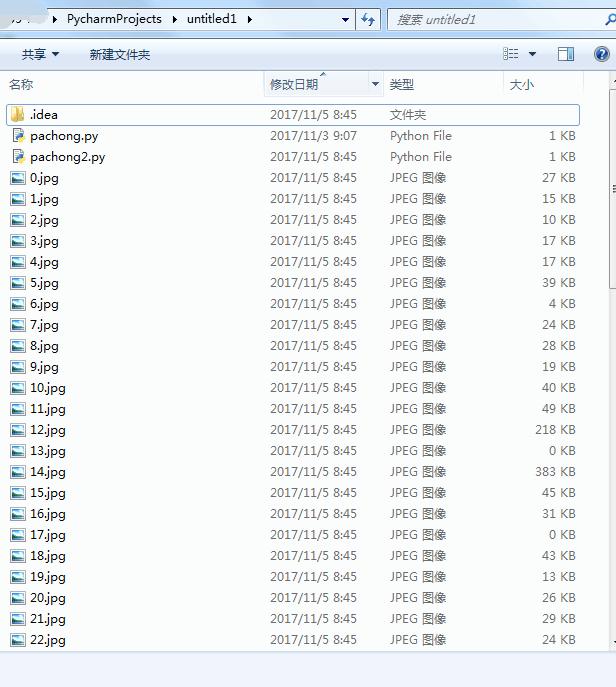
希望能对大家有帮助~~~