本次作业要探讨堆和栈的性质,为了严格起见,先说明下我这里的软件环境:
操作系统:OS X 10.9

编译器:CLANG & LLVM 3.3

先说内存占用部分:
由于我的编程能力弱爆了,只会写最简单的程序,并且各种规范都没有注意。于是我就写了如下程序来考察栈对于内存的使用:
#include <stdlib.h> void foo() { int a, b; a = 1; b = a; } int main() { int i; while (1) { foo(); } return 0; }
这段程序就在做一个很无聊的事情,不断申请空间。。。但是由于栈会自动回退,所以内存占用比较良好:
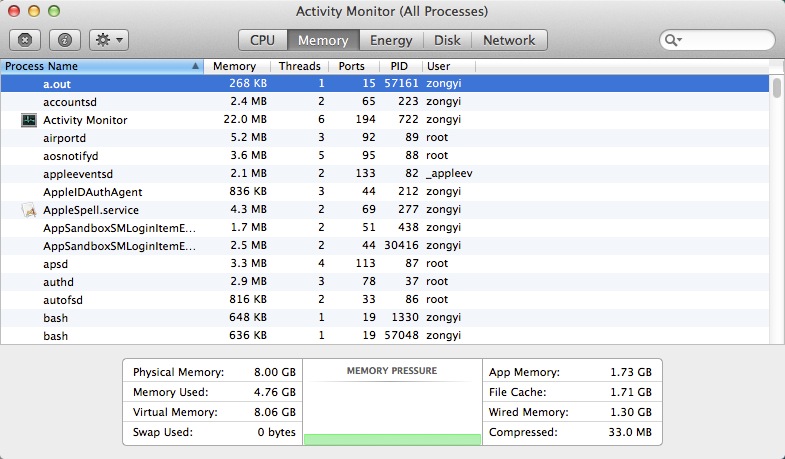
然后弱爆了的我为了测试堆的内存占用,写出了如下代码:
#include <stdlib.h> int foo() { int a, *b; a = 1; b = malloc(sizeof(int)); *b = a; return *b; } int main() { int i; while (1) { foo(); } return 0; }
有一点需要注意,这里返回值是传的值,不是指针,所以输出的结果也是正确的。可是。。。:

刚开没多久,就占了3.29G的内存。由于比较吓人,我就把这个程序关了。我测试过一次用了5.9G,后来怕电脑爆内存,就干掉进程了(爆内存意味着比较彻底的死机)。
后来我又测试了一下,这次在编译的时候,我用开了编译器的优化功能
gcc -O2 heapMemoryOccupy.c
这次执行的时候内存就很合理了:
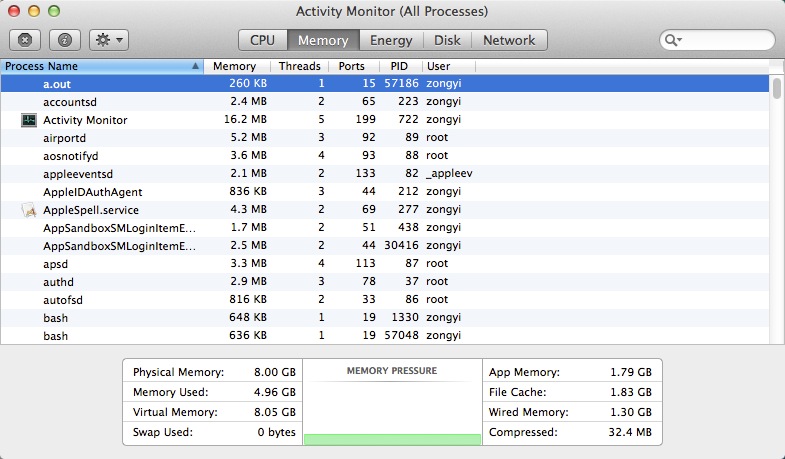
这个现象引起了我的好奇,果断从汇编入手(*nix和win有objdump,mac是otool),以下为不加优化的程序:
heapMemoryOccupy.o: (__TEXT,__text) section _foo: 0000000000000000 pushq %rbp 0000000000000001 movq %rsp, %rbp 0000000000000004 subq $0x10, %rsp 0000000000000008 movabsq $0x4, %rdi 0000000000000012 movl $0x1, 0xfffffffffffffffc(%rbp) 0000000000000019 callq 0x1e 000000000000001e movq %rax, 0xfffffffffffffff0(%rbp) 0000000000000022 movl 0xfffffffffffffffc(%rbp), %ecx 0000000000000025 movq 0xfffffffffffffff0(%rbp), %rax 0000000000000029 movl %ecx, (%rax) 000000000000002b movq 0xfffffffffffffff0(%rbp), %rax 000000000000002f movl (%rax), %eax 0000000000000031 addq $0x10, %rsp 0000000000000035 popq %rbp 0000000000000036 ret 0000000000000037 nopw (%rax,%rax) _main: 0000000000000040 pushq %rbp 0000000000000041 movq %rsp, %rbp 0000000000000044 subq $0x10, %rsp 0000000000000048 movl $0x0, 0xfffffffffffffffc(%rbp) 000000000000004f callq 0x54 0000000000000054 movl %eax, 0xfffffffffffffff4(%rbp) 0000000000000057 jmpq 0x4f
以下为加了优化的程序:
heapMemoryOccupy.o: (__TEXT,__text) section _foo: 0000000000000000 pushq %rbp 0000000000000001 movq %rsp, %rbp 0000000000000004 movl $0x1, %eax 0000000000000009 popq %rbp 000000000000000a ret 000000000000000b nopl (%rax,%rax) _main: 0000000000000010 pushq %rbp 0000000000000011 movq %rsp, %rbp 0000000000000014 nopw %cs:(%rax,%rax) 0000000000000020 jmp 0x20
编译器优化的原则是:在不改变结果的情况下尽可能给程序提速。不过这个结果确实令我感到震惊,直接根据语义,把malloc函数给优化掉了。看来我们的编译原理课上讲的东西还是太弱了。
关于运行速度:
由于某种机缘巧合,我的编程能力突然提高了,注意到了可能产生的内存泄漏,于是写出了下面两端代码,测试在保证正确性情况下堆和栈的速度:
先是栈:
#include <stdlib.h> void foo() { int a, b; a = 1; b = a; } int main() { long i = 1e9; while ((i--)>0) { foo(); } return 0; }
运行速度:

然后是堆,代码:
#include <stdlib.h> void foo() { int a, *b; a = 1; b = malloc(sizeof(int)); *b = a; free(b); } int main() { int i = 1e9; while ((i--) > 0) { foo(); } return 0; }
下面是速度:(测试的时候还一度怀疑能不能出结果了)
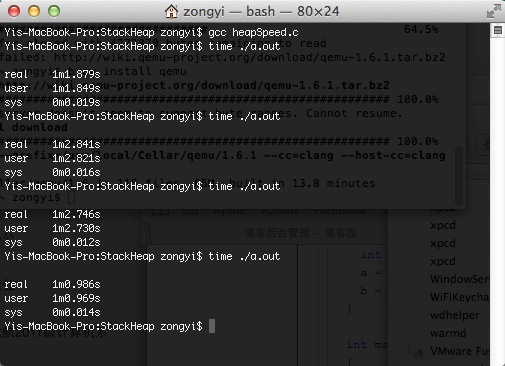
由此可见,由于申请和释放的开销,局部变量还是用栈比较好。
栈的不足之处,传说中的栈溢出(stack overflow):
由于蛋疼,我写了如下代码:
#include <stdio.h> void foo(int a) { printf("%d ", a); foo(a+1); } int main() { foo(1); return 0; }
这个就是一个无限递归,然后我们看它的结果:

由此可见,只要262008个最简单的递归,栈就溢出了,由此可以算出栈大约就是几兆的空间。
也由此告诉我们,由于各种限制,尽量少用递归比较好。不过,我又发现,开了优化参数以后,由于代码的优化,跑了很久都没栈溢出。。。
堆的另一个问题:指针悬挂
内存泄漏是众所周知,我们的第二段代码就是一个典型的内存泄漏,从截图可以看出,泄漏了将近4G内存(囧TL)。下面我来演示以下指针悬挂:
#include <stdlib.h> #include <stdio.h> int main() { int *i, *j; float *f; i = malloc(sizeof(int)); *i = 1; j = i; printf("*j=%d ", *j); free(i); f = malloc(sizeof(float)); *f = 0.5; printf("*j=%d ", *j); return 0; }
这里的亮点在于,j的位置后来变成了一个浮点数,以下是运行结果:
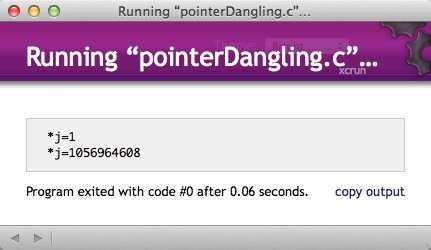
这是mac系统下的结果,在别的系统就不能保证了。由此得出的结论也很简单,这是要避免的情况。
指针是c语言的一大迷人的地方,指针用的犀利,程序也就很犀利。指针用萎了程序也就萎了。以上总结的都是我血泪教训,分享给大家,希望能够共同进步。