| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | |
| 这个作业要求在哪里 | |
| 我在这个课程的目标是 | 学习并掌握利用软件工程的思想与方法构建大规模高质量的软件系统的能力团队协作能力等 |
| 这个作业在哪个具体方面 帮助我实现目标 | 尝试结对编程开发,合作,对PSP进行亲身体验 |
| Gitlab地址 | 学号后四位 |
|---|---|
| 3407 3075 |
结对编程有感
现场照片(设计阶段):

3075:
结对编程和个人编程之间最大的不同就是多了一个能随时和你讨论的人。在代码设计的时候,两个人之间互相的交流和讨论能够极大地减少出现疏漏的情况,同时也能互相提出更好的措施来优化代码的设计。比如这次在设计目录结构的时候,利用hashmap来存储所有的子文件和子目录就是yzm想出来的。同时在后续的编写测试阶段,从他人的视角上能够发现很多自身难以发现的盲点,包括一些拼写上的错误,逻辑上的错误等,这些都是自己走查很难发现的。总之,可能由于是第一次参与结对编程,彼此间交互的效率可能不太满意,但是结对编程能够让人在写写代码的时候多一份思路,多一种视角,这能够很好地拓宽编程者的思路并提高代码的质量。
3407:
严格意义上的结对编程应该是两个程序员共用一台机器, 一个做“领航员”, 一个做“驾驶员”. 从这个角度看, 我们这一次的结对编程经历不那么“正宗”. 在设计阶段我们坐在一起边设计边讨论, 但在编码和测试阶段, 我们则是远程分工合作, 而且由于未提前协商, 我们编码和测试的进度并不是一致的,所以在前期有“结对编程”的在后期更像是“组队编程”. 前期设计的时候,我认为两个人的结对,对项目的设计是非常有利的: 两个人边设计边讨论, 在相互纠错和启发下设计的进展会很快, 而且我发现两人结对, 专注力明显提升,思维也活跃起来…….总的来说我们的工作推进得不错, 由于双方积极干活,任务完成得比较顺利.
事后反思发现,我们结对编程的工作效率不高, 互相配合还不够, 同时存在一定的沟通成本…….具体来说, 我认为有两大原因: 设计阶段双方都忘记使用UML图进行沟通, 这造成双方因担心编码风格不一致而采取分工合作先编码后测试的策略; 单元测试与编码未同步进行, 基本上编码,代码审核, 测试,是流水线作业,而非并行.
另外结对编程第一阶段, 在合作开发的过程中, 我一定程度上充当了测试员的角色, 发现代码审核和单元测试的重要性, 与其他人交流的过程中发现在代码风格, UML设计这块有所欠缺,这都曾是我在OO课程中不以为意的地方.
在结对编程的过程中,我好像对自我有了新的认识—— 自身特点: 谨慎细心,在局部问题考虑周全, 这就造成了我设计时挺适合做补充,测试时做白盒测试能查出不少bug ; 思路相对不敏捷,反应不快, 此次认识到技术方面需要加强学习的地方: UML设计, 代码风格(代码接口设计, 注释等) , 工具的使用与配置文件(CI, maven的使用);
设计和实现思路
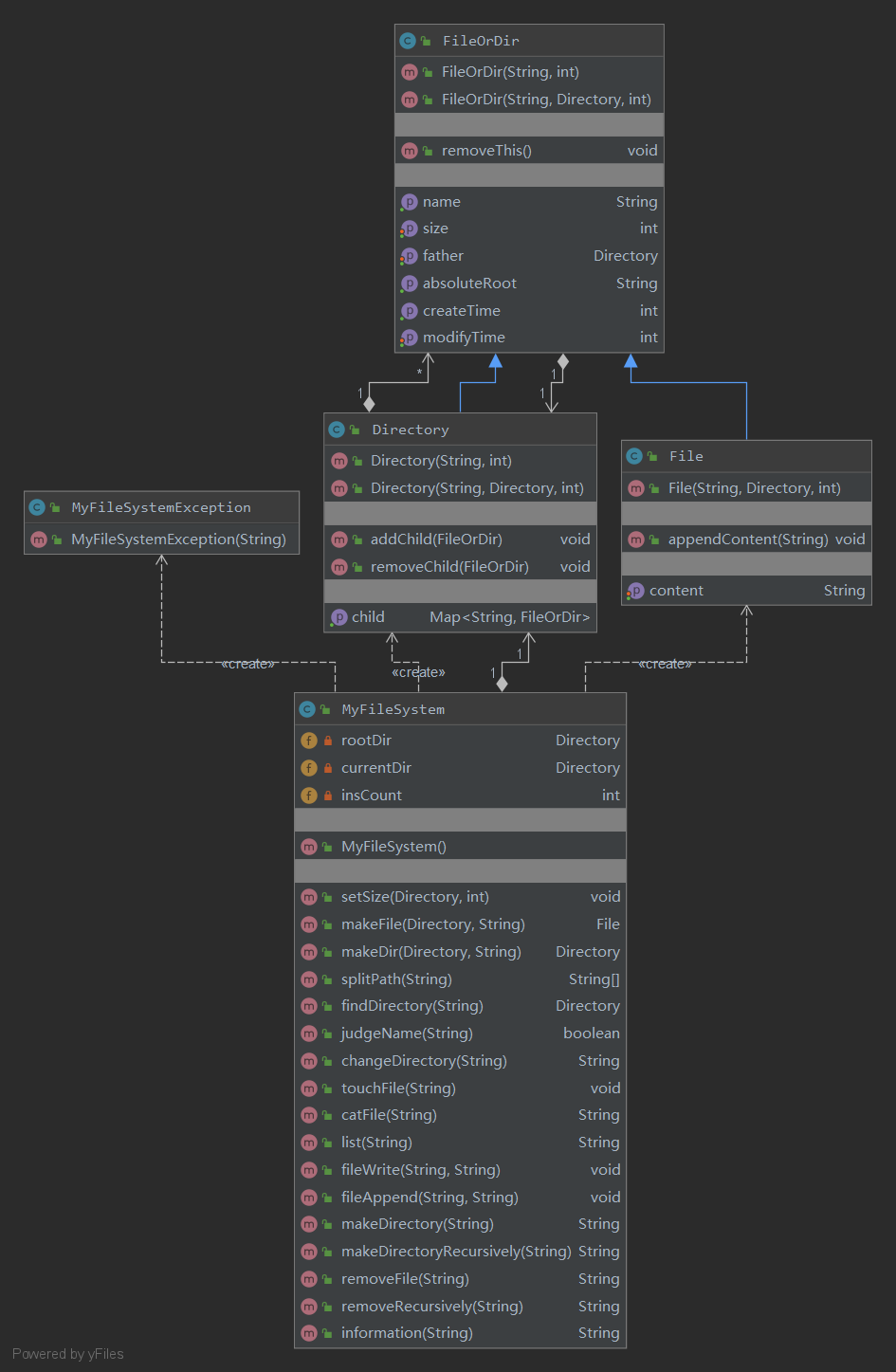
对于文件和目录类以及结构
本次项目中最基础的就是对于文件类和目录类以及其结构的设计,考虑到文件和目录有很多相同的属性,并且一个目录下同时会有子文件和子目录,于是我们便设计一个文件和目录的父类:
public class FileOrDir {
private String name; //名称
private int size; //大小
private String absoluteRoot; //绝对路径
private int createTime; //创建时间
private int modifyTime; //最后一次修改时间
private Directory father; //父目录
}
文件和目录分别继承这个父类,并且在文件中增加“content”内容属性,在目录中增加“child”属性用来记录该目录下的子文件和子目录,这样文件类和目录类就设计好了
同时在文件的存储上,我们考虑采用的是树形结构,再加上由于每个文件的绝对路径是唯一的,便利用HashMap来保存目录的子文件和子目录来提高查找时的效率
private Map<String, FileOrDir> child; //目录的内容,包括子目录和文件 key:文件名
关于路径
路径的查找实际上是对于字符串解析工作,很自然的便想到用split方法将输入的路径名称按照"/"分割,然后从起始目录开始一层一层往下查找。
一开始考虑到由于每一个方法在路径搜索的过程中的处理都会有一些不同,所以一开始没有打算为路径搜索抽象出一个方法,而是每个方法内部自行解决。后来发现这样写出来之后代码过于冗余,又考虑到不管是文件路径还是目录路径,除了路径的最后一项之外对于前面的部分处理方法是相同的,于是便写了一个findDirectory方法,用于找到给出路径的倒数第二个目录(例如 "a/b/c" 就找到b),之后的处理就因哥函数而异了。
同时需要注意的是,如果在路径的最后出现.或者..的情况,各函数需要特别注意处理。在后续的debug环节中在这上面栽了不少跟头。
关于各种方法
不管是文件操作方法还是目录操作方法都是基于路径的,所以基本上所有方法第一步都是搜索,然后根据搜索的结果来进行各种操作。需要时刻注意的是,该方法进行的操作是否会修改文件的修改时间,目录的修改时间,文件或者目录的大小。这些我们都同方法实现的基本逻辑一起在方法设计的时候提前梳理了一边并写在了方法前的注释里,防止出现遗漏。
我们感觉本次作业中最复杂的一个方法就是递归创建目录的makeDirectoryRecursively方法。原因是因为他和其他所有方法的在路径搜索上的逻辑都不同,不能调用上面设计的findDirectory方法。再加上该方法需要考虑的特殊情况比较多,例如路径中出现../..,末尾出现.或者..之类的神奇情况,导致对于该方法的编程与调试花费了大量的时间。最后发现这个方法的逻辑其实也很简单,每一层搜索,如果找到就进入,找不到就创建。
这里要感谢一下提问区某同学给出的一个想法,帮助我们很好的理解了.和..的意义:在一个目录创建时,默认该目录下已有两个子目录,分别是指向自身的.和指向上层目录的..。在这个想法的基础上,很多一开始考虑的特殊情况也就没有那么难处理了。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 10min | 10min |
| · Estimate | · 估计这个任务需要多少时间 | 10min | 10min |
| Development | 开发 | 18h | 17h30min |
| · Analysis | · 需求分析 (包括学习新技术) | 1h | 1h |
| · Design Spec | · 生成设计文档 | 1h | 1h30min |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30min | 15min |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30min | 15min |
| · Design | · 具体设计 | 1h | 30min |
| · Coding | · 具体编码 | 6h | 5h |
| · Code Review | · 代码复审 | 2h | 4h |
| · Test | · 测试(自我测试,修改代码,提交修改) | 6h | 5h |
| Reporting | 报告 | 2h50min | 4h20min |
| · Test Report | · 测试报告 | 30min | 2h |
| · Size Measurement | · 计算工作量 | 20min | 20min |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 2h | 2h |
| 合计 | 21h | 22h |