GINet: Graph Interaction Network for Scene Parsing
来源:ECCV 2020
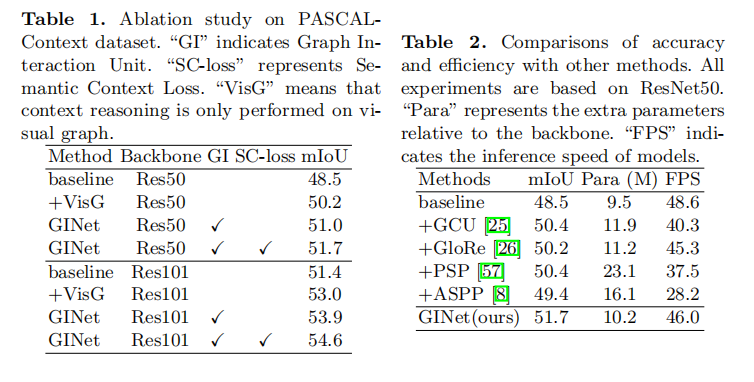
最近基于图像区域的上下文推理在场景分割中已经取得显著进步。论文中,百度通过提出图交互单元和语义上下文损失,探索如何利用语义知识来促进基于图像区域的上下文推理。图交互单元能够增强卷积网络的特征表示,同时能自适应地为每个样本学习语义一致性。
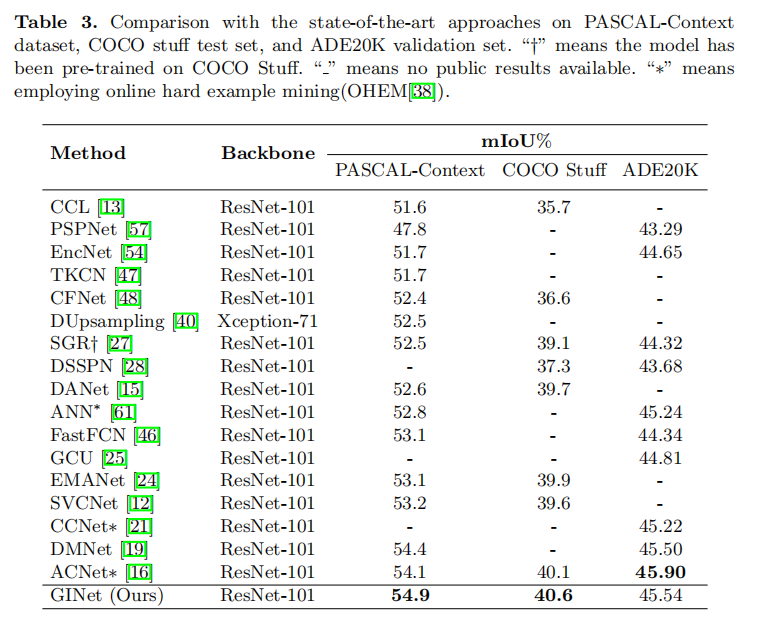
具体地,基于数据集的语义知识首先被纳入图交互单元来促进视觉图的上下文推理,然后演化的视觉图特征被反投影到每个局部特征来增强其可区分力。图交互单元进一步被语义上下文损失改善其生成基于样本语义图的能力。完整的消融实验证明了新方法中的每个组件和相关设计选择的有效性。特别地,本文提出的图交互网络在Pascal-Context和COCO-Stuff数据集上超过了同期方法。
1. INTRODUCTION
主要意义:尝试在语义分割框架中引入额外的语义上下文信息。
大部分语义分割的方法都是基于输入图像,也就是视觉特征进行分类(FCN/PSP/DeepLab),但这样就缺少了不同类别间的上下文相关性。 non-local可以通过计算不同像素之间的相关性来建立上下文关系,但计算量较大。于是有人试图将图卷积神经网络(GCN)加入到语义分割中,将特征空间中的一些区域映射到图空间中,每个节点代表不同的区域。对图空间做图卷积的话,就相当于捕捉不同区域之间的关系。之后再将图空间映射回特征空间。
2. METHODOLOGY
GCN with segmentation
首先把特征从特征空间投射到图空间,再在图空间进行卷积,捕捉区域之间的关系,最后把特征从图空间返投射到特征空间。
推理视觉区域之间的关系 + 语义概念

框架

- 作者使用预训练好的ResNet作为backbone提取视觉特征。随后,作者将图像中的类别以文本的形式提取出来经过word embedding(如GloVe),将单词映射到方便处理的多维向量。
- 将视觉特征和文本特征经过graph projection投射到图空间,分别构建两个图VisG和SemG。此时VisG中的节点表示某一区域的视觉特征,边表示不同区域之间的关系。SemG中的节点和边表示经过word embedding后的文本特征和文本间的关系。
- 在GI Unit中进行图交互graph interaction,利用文本图的语义信息指导视觉图的形成。
- 将经过GI Unit处理后的图重新投影到特征空间,并通过1*1的卷积和上采样的到最终结果。
3. EXPERIMENTS
结果可视化
不同节点对应不同范围

4. CONCLUSIONS
- 提出了一种新的图交互单元GI unit用于上下文建模
- 提出了Semantic Context Loss (SC-loss) 用来强调出现在场景中的类别,抑制没有出现的类别
- 提出了一种图交互网络GINet