Spark 比 MR 好在那?
()Hadoop的MapReduce计算模型存在的问题:
MapReduce的核心是Shuffle(洗牌)。在整个Shuffle的
过程中,至少会产生6次的I/O。
中间结果输出:基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。另
外,当一些查询(如:Hive)翻译到MapReduce任务时,往往会产生多个Stage(阶段),而这些串联
的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果,而I/O的效率往往较低,从
而影响了MapReduce的运行速度。
()Spark的最大特点:基于内存
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补
MapReduce的不足。
Spark的特点
快、易用、通用、兼容性
Spark集群的体系结构
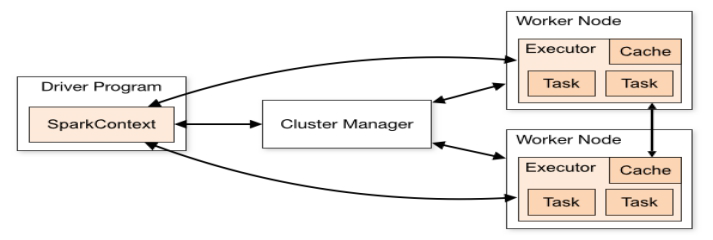
Spark提交任务的流程
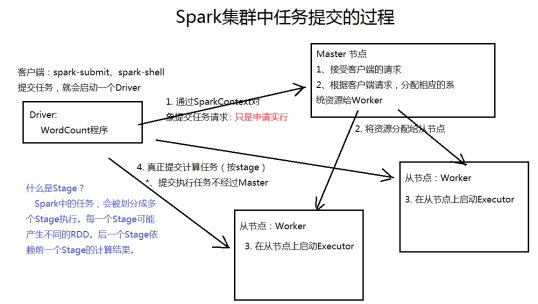
spark 的体系架构

Spark的安装与部署
Spark的安装部署方式有以下几种模式:
Standalone
YARN
Mesos
Amazon EC2
Spark HA的实现
基于Zookeeper的Standby Masters

配置参数参考值
spark.deploy.recoveryMode 设置为ZOOKEEPER开启单点恢复功能,默认值:NONE
spark.deploy.zookeeper.url ZooKeeper集群的地址
spark.deploy.zookeeper.dir Spark信息在ZK中的保存目录,默认:/spark
l 参考:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -
Dspark.deploy.zookeeper.url=bigdata12:2181,bigdata13:2181,bigdata14:2181 -
Dspark.deploy.zookeeper.dir=/spark"

RDD
RDD的属性
- 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处
理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采
用默认值。默认值就是程序所分配到的CPU Core的数目。 - 一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数
以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 - RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线
一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数
据,而不是对RDD的所有分区进行重新计算。 - 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的
HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有
Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分
片数量,也决定了parent RDD Shuffle输出时的分片数量。 - 一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这
个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行
任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
RDD的创建方式
通过外部的数据文件创建,如HDFS
val rdd1 = sc.textFile(“hdfs://192.168.88.111:9000/data/data.txt”)
通过sc.parallelize进行创建
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
RDD的类型:
Transformation和Action
Transformation:
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。
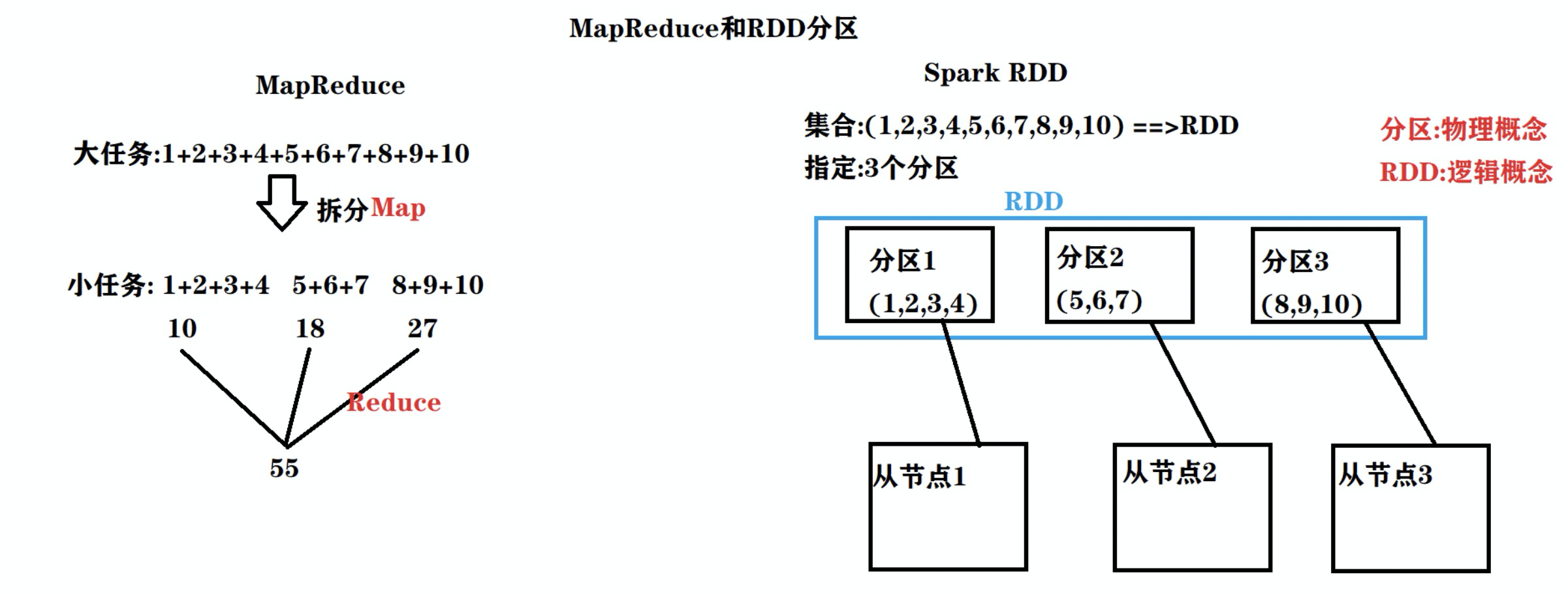
MapReduce 和 RDD 分区
RDD的缓存机制
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓
存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使
缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各
个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
RDD的Checkpoint(检查点)机制:容错机制
检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage(血统)做容错的辅助,lineage过
长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,
从做检查点的RDD开始重做Lineage,就会减少开销。
设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS。一般是在具有容错能力,高可靠的文
件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据。

-
本地目录
注意:这种模式,需要将spark-shell运行在本地模式上

-
HDFS的目录
注意:这种模式,需要将spark-shell运行在集群模式上

RDD的依赖关系和Spark任务中的Stage
RDD的依赖关系
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖
(wide dependency)。
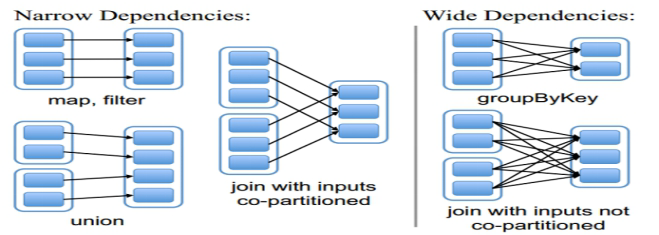
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:窄依赖我们形象的比喻为超生
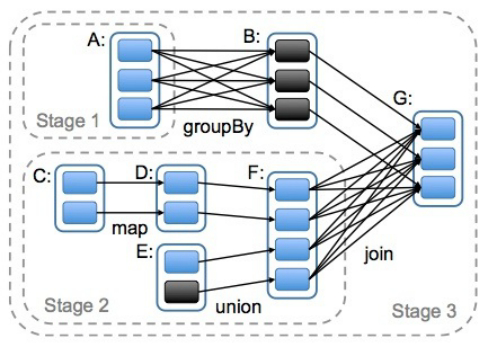
Spark任务中的Stage
遇到窄依赖就合并成一个stage, 遇到宽依赖则拆分掉,等待这个宽依赖计算完毕,才触发下游的计算。
宽依赖是划分Stage的依据。
Spark RDD的高级算子
mapPartitionsWithIndex
把每个partition中的分区号和对应的值拿出来
aggregate
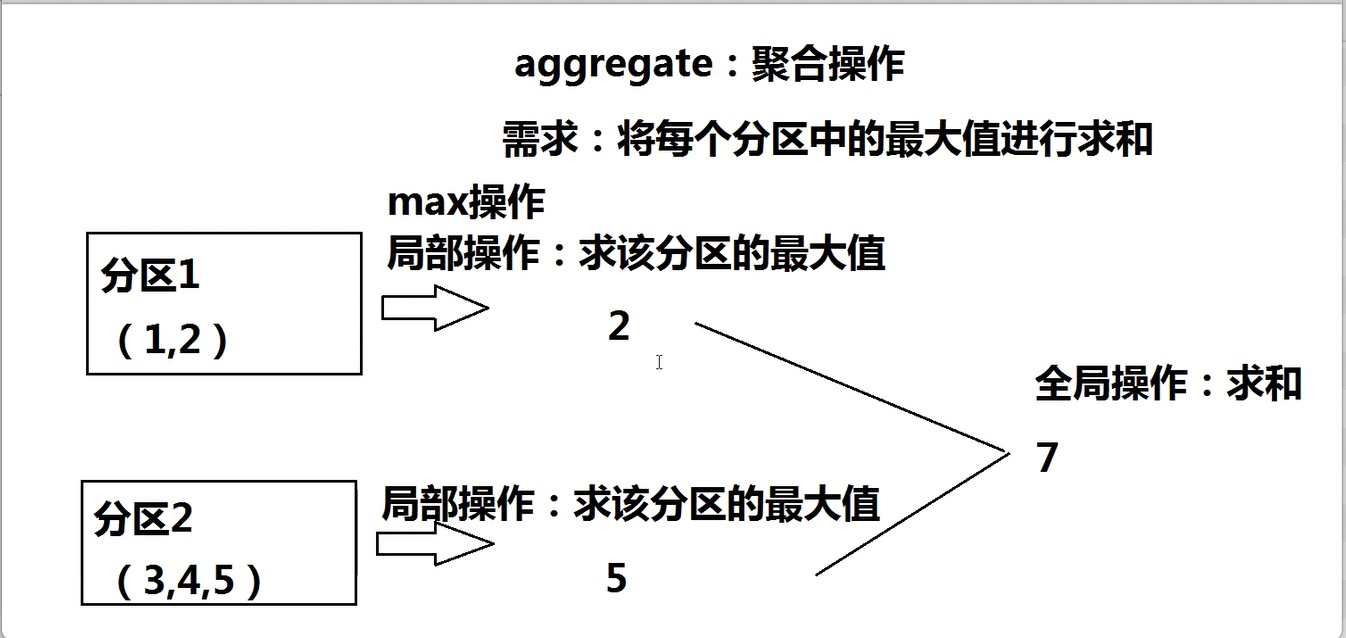
先对局部聚合,再对全局聚合。
rdd1.aggregate(0)(math.max(,),+)


aggregateByKey
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse",
| 2)), 2)
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
coalesce与repartition
都是将RDD中的分区进行重分区
区别是:coalesce默认不会进行shuffle(false);而repartition会进行shuffle(true),即:会将数据真正通过网络进行重分区。