Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
0.数据要首先分块
Block:将一个文件进行分块,通常是64M。
NameNode:--管理节点保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在Hadoop2.*开始支持activity-standy模式----如果主NameNode失效,启动备用主机运行NameNode。
DataNode:分布在廉价的计算机上,用于存储Block块文件。
1.HDFS存储策略
对于任意一块数据块都存放三块,默认值(其中有两块在同一机架上,还有一块在其他机架上)确保数据的可靠性
心跳检测:dataNode定期会想NameNode发送信息,把自己的状态告诉NameNode
SecondaryNameNode:第二管理节点,把NameNode中的数据进行备份,当NameNode发送故障时,SecondaryNameNode其作用,代替NameNode。起到二级保护作用。
2.HDFS文件读取流程
读流程:
写入文件: 有流水线复制
3. HDFS的特点:
1.数据冗余,硬件容错
2.流式的数据访问,写一次读多次,顺序读写;
3.适合存储大文件
4.适合数据批量读写,吞吐量高
5.不支持多户用并发写相同文件
4.HDFS的使用
1.命令行操作
hadoop fs -ls /目录 ; ————————————————列出某目录下文件;
hadoop fs -put 文件名 文件存放路径带'/'; ——————————将文件存放到某目录下
hadoop fs -mkdir 目录名 ——————————————创建目录名
5.MapReduce原理
分而治之的思想。
一个大任务分成多个小任务,也就是用Map ,并执行后进行合并结果,就是reduce。
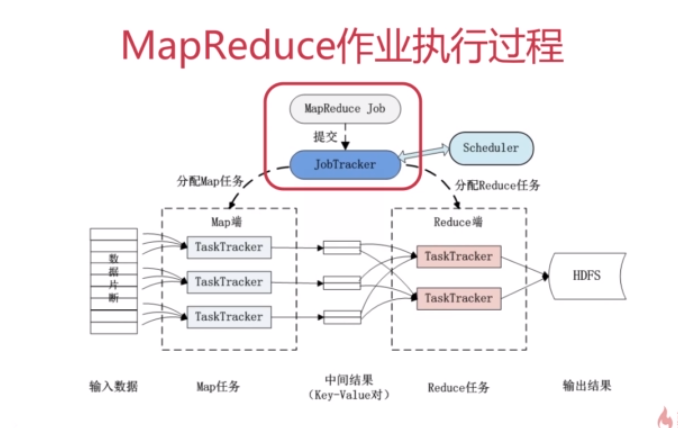
6.MapReduce运行流程
1.Job &Task 一个Job(作业)分为多个Task(任务),分为MapTask和ReduceTask
2.JobTracker (管理节点) 作用: 作业调度,分配任务,监控任务执行进度 监控TaskTracker的状态
3.TaskTracker 执行任务,汇报任务状态
MapReduce作业执行过程
7.MapReduce的容错机制
1.重复执行 2.推测执行
8.MapReduce的应用案例-wordCount单词计数
9.利用MapReduce进行排序
Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。