使用表来统一表示Lua中的一切数据,是Lua区分其他语言的一个特色。
Lua表分为数组(索引从1开始)和散列表两个部分,可以模拟其他各种数据--数组、链表、树等。
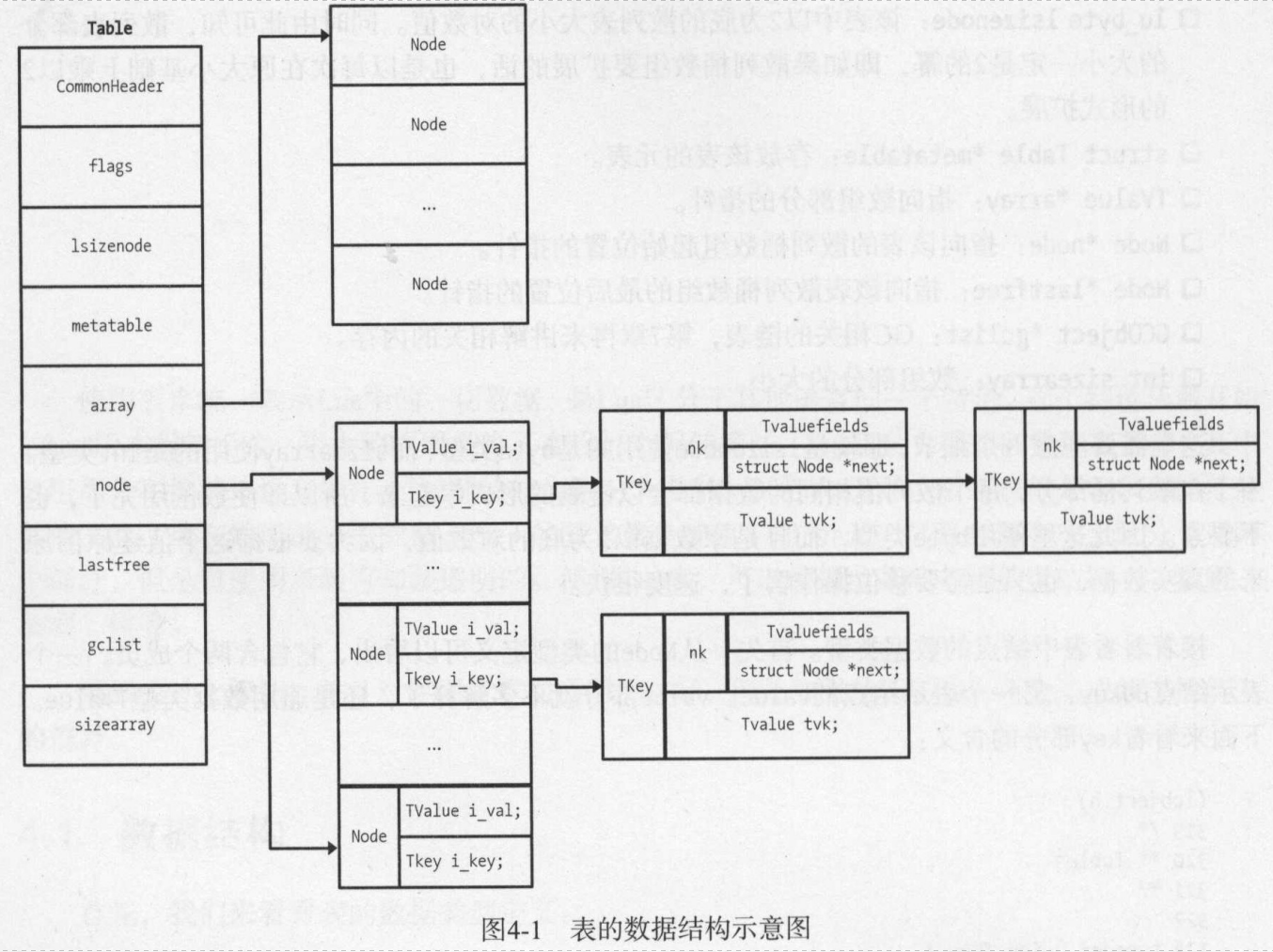
4.1 表的数据结构
//llimits.h:27 typedef unsigned char lu_byte; //ltm.h:18 typedef enum { TM_INDEX, TM_NEWINDEX, TM_GC, TM_MODE, TM_EQ, /* last tag method with `fast' access */ TM_ADD, TM_SUB, TM_MUL, TM_DIV, TM_MOD, TM_POW, TM_UNM, TM_LEN, TM_LT, TM_LE, TM_CONCAT, TM_CALL, TM_N /* number of elements in the enum */ } TMS; //lobject.h:338 typedef struct Table { CommonHeader; lu_byte flags; /* 1<<p means tagmethod(p) is not present. p对应TMS中的值*/ lu_byte lsizenode; /* log2 of size of `node' array. size 最大 2^(2^16 - 1) */ struct Table *metatable; // 存放该表的元表 TValue *array; /* array part */ Node *node; Node *lastfree; /* any free position is before this position */ GCObject *gclist; int sizearray; /* size of `array' array. size 最大 2^32 - 1 */ } Table; //lobject.h:323 //Node 中含两个成员 typedef union TKey { struct { TValuefields; struct Node *next; /* for chaining */ } nk; TValue tvk; } TKey; typedef struct Node { TValue i_val; TKey i_key; } Node;
4.2 操作算法
(1)新增元素
散列表部分:首先计算数据的key所在的桶的位置(mainposition),即使用luaH_set 、 luaH_setnum 、 luaH_setstr这3个API函数返回TValue指针。然后由外部的使用者来进行替换操作。当找不到对应的key时,这三个API最终都会调用newkey函数分配并返回一个新的key。
//ltable.c:189 // 逐个遍历 nums 数组,获得其范围区间内所包含的整数数量大于 50% 的最大索引, 作为重新散列之后的数组大小(na), // 超过这个范围的正整数,就分配到散列桶部分了( computesizes 函数) static int computesizes (int nums[], int *narray) { int twotoi; /* 2^i */ int a = 0; /* number of elements smaller than 2^i */ int na = 0; /* number of elements to go to array part */ int n = 0; /* optimal size for array part */ for (int i = 0, twotoi = 1; twotoi/2 < *narray; i++, twotoi *= 2) { if (nums[i] > 0) { a += nums[i]; if (a > twotoi/2) { /* more than half elements present? */ n = twotoi; /* optimal size (till now) */ na = a; /* all elements smaller than n will go to array part */ } } if (a == *narray) break; /* all elements already counted */ } *narray = n; lua_assert(*narray/2 <= na && na <= *narray); return na; } //ltable.c:333 /*在散列表中插入新key*/ static void rehash (lua_State *L, Table *t, const TValue *ek) { int nums[MAXBITS+1]; /* nums[i] = number of keys between 2^(i-1) and 2^i */ for (int i=0; i<=MAXBITS; i++) nums[i] = 0; /* reset counts */ int nasize = numusearray(t, nums); /* count keys in array part */ int totaluse = nasize; /* 整数 key 的个数 */ totaluse += numusehash(t, nums, &nasize); /* count keys in hash part */ nasize += countint(ek, nums);/* count extra key */ totaluse++; /* compute new size for array part */ int na = computesizes(nums, &nasize); /* resize the table to new computed sizes */ resize(L, t, nasize, totaluse - na); } //ltable.c:399 /*在散列表中插入新key*/ static TValue *newkey (lua_State *L, Table *t, const TValue *key) { Node *mp = mainposition(t, key); if (!ttisnil(gval(mp)) || mp == dummynode) { // 新 key 的 main position 不空 Node *n = getfreepos(t); /* get a free place */ if (n == NULL) { /* cannot find a free place? */ rehash(L, t, key); /* grow table */ return luaH_set(L, t, key); /* re-insert key into grown table */ } lua_assert(n != dummynode); Node *othern = mainposition(t, key2tval(mp)); if (othern != mp) { /* 碰撞的 node 不在它的 main position,将此 node 移到一个空的地方,新 key 移过来 */ while (gnext(othern) != mp) othern = gnext(othern); /* find previous */ gnext(othern) = n; /* redo the chain with `n' in place of `mp' */ *n = *mp; /* copy colliding node into free pos. (mp->next also goes) */ gnext(mp) = NULL; /* now `mp' is free */ setnilvalue(gval(mp)); } else { /* 碰撞的 node 在它的 main position,将新 key 移到一个空的位置 */ gnext(n) = gnext(mp); /* chain new position */ gnext(mp) = n; mp = n; } } gkey(mp)->value = key->value; gkey(mp)->tt = key->tt; luaC_barriert(L, t, key); lua_assert(ttisnil(gval(mp))); return gval(mp); }
从上面的代码可以看到, Lua解释器背着我们会对表进行重新散列的动作。所以如果有很多小的表需要创建,就可以预先填充以避免重新散列操作。
(2)迭代:迭代对外的 API是 Lua H_next 函数,它的伪代码是 :
在数组部分查找数据:
查找成功, 则返回该 key 的下一个数据
否则在散列桶部分查找数据:
查找成功, 则返回该 key 的下一个数据
(3)取长度操作: luaH_getn,它的伪代码是 :
如果表存在数组部分:
在数组部分二分查找返回位置 i ,其中 i 是满足条件t[i]!= nil 且 t[i + 1] = nil 的最大的i
否则前面的数组部分查不到满足条件的数据,进入散列表部分查找:
在散列表部分二分查找返回位置 i ,其中 i 是满足条件 t[i]!= nil 且 t[i + 1] = nil 的最大数据
因此,使用表时需要注意以下事项 。
尽量不要将一个表混用数组和散列桶部分,即 一个表最好只存放一类数据 。 Lua 的实现上确实提供了两者统一表示的遍历,但是这不意味着使用者就应该混用这两种方式。
尽量避免进行重新散列操作,因为重新散列操作的代价极大。 通过预分配、只使用数组部分等策略规避这个Lua解释器背后的动作,能提升不少效率 。
print(#{10, 20, nil, 40}) --输出 2(书中数据有误), lua 5.1.4实测输出4 print(#{[1] = 1, [2] = 2 }) --输出 2 print(#{[1] = 1, [2] = 2, [5] = 5}) --输出 5(书中数据有误), lua 5.1.4实测输出2 print(#{[1] = 1, [2] = 2, 1, 2, 3}) --输出 3