了解事务和锁
事务:保持逻辑数据一致性与可恢复性,必不可少的利器。
锁:多用户访问同一数据库资源时,对访问的先后次序权限管理的一种机制,没有他事务或许将会一塌糊涂,不能保证数据的安全正确读写。
死锁:是数据库性能的重量级杀手之一,而死锁却是不同事务之间抢占数据资源造成的。
不懂的听上去,挺神奇的,懂的感觉我在扯淡,下面带你好好领略下他们的风采,嗅査下他们的狂骚。。
先说事务--概念,分类
用华仔无间道中的一句来给你诠释下:去不了终点,回到原点。
举例说明:
在一个事务中,你写啦2条sql语句,一条是修改订单表状态,一条是修改库存表库存-1 。 如果在修改订单表状态的时候出错,事务能够回滚,数据将恢复到没修改之前的数据状态,下面的修改库存也就不执行,这样确保你关系逻辑的一致,安全。。
事务就是这个样子,倔脾气,要么全部执行,要么全部不执行,回到原数据状态。
书面解释:事务具有原子性,一致性,隔离性,持久性。
- 原子性:事务必须是一个自动工作的单元,要么全部执行,要么全部不执行。
- 一致性:事务结束的时候,所有的内部数据都是正确的。
- 隔离性:并发多个事务时,各个事务不干涉内部数据,处理的都是另外一个事务处理之前或之后的数据。
- 持久性:事务提交之后,数据是永久性的,不可再回滚。
然而在SQL Server中事务被分为3类常见的事务:
- 自动提交事务:是SQL Server默认的一种事务模式,每条Sql语句都被看成一个事务进行处理,你应该没有见过,一条Update 修改2个字段的语句,只修该了1个字段而另外一个字段没有修改。。
- 显式事务:T-sql标明,由Begin Transaction开启事务开始,由Commit Transaction 提交事务、Rollback Transaction 回滚事务结束。
- 隐式事务:使用Set IMPLICIT_TRANSACTIONS ON 将将隐式事务模式打开,不用Begin Transaction开启事务,当一个事务结束,这个模式会自动启用下一个事务,只用Commit Transaction 提交事务、Rollback Transaction 回滚事务即可。
显式事务的应用
常用语句就四个。
- Begin Transaction:标记事务开始。
- Commit Transaction:事务已经成功执行,数据已经处理妥当。
- Rollback Transaction:数据处理过程中出错,回滚到没有处理之前的数据状态,或回滚到事务内部的保存点。
- Save Transaction:事务内部设置的保存点,就是事务可以不全部回滚,只回滚到这里,保证事务内部不出错的前提下。
上面的都是心法,下面的给你来个招式,要看仔细啦。

1 ---开启事务
2 begin tran
3 --错误扑捉机制,看好啦,这里也有的。并且可以嵌套。
4 begin try
5 --语句正确
6 insert into lives (Eat,Play,Numb) values ('猪肉','足球',1)
7 --Numb为int类型,出错
8 insert into lives (Eat,Play,Numb) values ('猪肉','足球','abc')
9 --语句正确
10 insert into lives (Eat,Play,Numb) values ('狗肉','篮球',2)
11 end try
12 begin catch
13 select Error_number() as ErrorNumber, --错误代码
14 Error_severity() as ErrorSeverity, --错误严重级别,级别小于10 try catch 捕获不到
15 Error_state() as ErrorState , --错误状态码
16 Error_Procedure() as ErrorProcedure , --出现错误的存储过程或触发器的名称。
17 Error_line() as ErrorLine, --发生错误的行号
18 Error_message() as ErrorMessage --错误的具体信息
19 if(@@trancount>0) --全局变量@@trancount,事务开启此值+1,他用来判断是有开启事务
20 rollback tran ---由于出错,这里回滚到开始,第一条语句也没有插入成功。
21 end catch
22 if(@@trancount>0)
23 commit tran --如果成功Lives表中,将会有3条数据。
24
25 --表本身为空表,ID ,Numb为int 类型,其它为nvarchar类型
26 select * from lives

---开启事务
begin tran
--错误扑捉机制,看好啦,这里也有的。并且可以嵌套。
begin try
--语句正确
insert into lives (Eat,Play,Numb) values ('猪肉','足球',1)
--加入保存点
save tran pigOneIn
--Numb为int类型,出错
insert into lives (Eat,Play,Numb) values ('猪肉','足球',2)
--语句正确
insert into lives (Eat,Play,Numb) values ('狗肉','篮球',3)
end try
begin catch
select Error_number() as ErrorNumber, --错误代码
Error_severity() as ErrorSeverity, --错误严重级别,级别小于10 try catch 捕获不到
Error_state() as ErrorState , --错误状态码
Error_Procedure() as ErrorProcedure , --出现错误的存储过程或触发器的名称。
Error_line() as ErrorLine, --发生错误的行号
Error_message() as ErrorMessage --错误的具体信息
if(@@trancount>0) --全局变量@@trancount,事务开启此值+1,他用来判断是有开启事务
rollback tran ---由于出错,这里回滚事务到原点,第一条语句也没有插入成功。
end catch
if(@@trancount>0)
rollback tran pigOneIn --如果成功Lives表中,将会有3条数据。
--表本身为空表,ID ,Numb为int 类型,其它为nvarchar类型
select * from lives

使用set xact_abort
设置 xact_abort on/off , 指定是否回滚当前事务,为on时如果当前sql出错,回滚整个事务,为off时如果sql出错回滚当前sql语句,其它语句照常运行读写数据库。
需要注意的时:xact_abort只对运行时出现的错误有用,如果sql语句存在编译时错误,那么他就失灵啦。
delete lives --清空数据
set xact_abort off
begin tran
--语句正确
insert into lives (Eat,Play,Numb) values ('猪肉','足球',1)
--Numb为int类型,出错,如果1234..那个大数据换成'132dsaf' xact_abort将失效
insert into lives (Eat,Play,Numb) values ('猪肉','足球',12345646879783213)
--语句正确
insert into lives (Eat,Play,Numb) values ('狗肉','篮球',3)
commit tran
select * from lives

为on时,结果集为空,因为运行是数据过大溢出出错,回滚整个事务。
事务把死锁给整出来啦
跟着做:打开两个查询窗口,把下面的语句,分别放入2个查询窗口,在5秒内运行2个事务模块。
begin tran
update lives set play='羽毛球'
waitfor delay '0:0:5'
update dbo.Earth set Animal='老虎'
commit tran
begin tran
update Earth set Animal='老虎'
waitfor delay '0:0:5' --等待5秒执行下面的语句
update lives set play='羽毛球'
commit tran
select * from lives
select * from Earth


为什么呢,下面我们看看锁,什么是锁。
并发事务成败皆归于锁——锁定
在多用户都用事务同时访问同一个数据资源的情况下,就会造成以下几种数据错误。
- 更新丢失:多个用户同时对一个数据资源进行更新,必定会产生被覆盖的数据,造成数据读写异常。
- 不可重复读:如果一个用户在一个事务中多次读取一条数据,而另外一个用户则同时更新啦这条数据,造成第一个用户多次读取数据不一致。
- 脏读:第一个事务读取第二个事务正在更新的数据表,如果第二个事务还没有更新完成,那么第一个事务读取的数据将是一半为更新过的,一半还没更新过的数据,这样的数据毫无意义。
- 幻读:第一个事务读取一个结果集后,第二个事务,对这个结果集经行增删操作,然而第一个事务中再次对这个结果集进行查询时,数据发现丢失或新增。
然而锁定,就是为解决这些问题所生的,他的存在使得一个事务对他自己的数据块进行操作的时候,而另外一个事务则不能插足这些数据块。这就是所谓的锁定。
锁定从数据库系统的角度大致可以分为6种:
- 共享锁(S):还可以叫他读锁。可以并发读取数据,但不能修改数据。也就是说当数据资源上存在共享锁的时候,所有的事务都不能对这个资源进行修改,直到数据读取完成,共享锁释放。
- 排它锁(X):还可以叫他独占锁、写锁。就是如果你对数据资源进行增删改操作时,不允许其它任何事务操作这块资源,直到排它锁被释放,防止同时对同一资源进行多重操作。
- 更新锁(U):防止出现死锁的锁模式,两个事务对一个数据资源进行先读取在修改的情况下,使用共享锁和排它锁有时会出现死锁现象,而使用更新锁则可以避免死锁的出现。资源的更新锁一次只能分配给一个事务,如果需要对资源进行修改,更新锁会变成排他锁,否则变为共享锁。
- 意向锁:SQL Server需要在层次结构中的底层资源上(如行,列)获取共享锁,排它锁,更新锁。例如表级放置了意 向共享锁,就表示事务要对表的页或行上使用共享锁。在表的某一行上上放置意向锁,可以防止其它事务获取其它不兼容的的锁。意向锁可以提高性能,因为数据引 擎不需要检测资源的每一列每一行,就能判断是否可以获取到该资源的兼容锁。意向锁包括三种类型:意向共享锁(IS),意向排他锁(IX),意向排他共享锁 (SIX)。
- 架构锁:防止修改表结构时,并发访问的锁。
- 大容量更新锁:允许多个线程将大容量数据并发的插入到同一个表中,在加载的同时,不允许其它进程访问该表。
这些锁之间的相互兼容性,也就是,是否可以同时存在。
|
|
现有的授权模式 |
|
|
|
|
|
|---|---|---|---|---|---|---|
|
请求的模式 |
IS |
S |
U |
IX |
SIX |
X |
|
意向共享 (IS) |
是 |
是 |
是 |
是 |
是 |
否 |
|
共享 (S) |
是 |
是 |
是 |
否 |
否 |
否 |
|
更新 (U) |
是 |
是 |
否 |
否 |
否 |
否 |
|
意向排他 (IX) |
是 |
否 |
否 |
是 |
否 |
否 |
|
意向排他共享 (SIX) |
是 |
否 |
否 |
否 |
否 |
否 |
|
排他 (X) |
否 |
否 |
否 |
否 |
否 |
否 |
锁兼容性具体参见:http://msdn.microsoft.com/zh-cn/library/ms186396.aspx
锁粒度和层次结构参见:http://msdn.microsoft.com/zh-cn/library/ms189849(v=sql.105).aspx
死锁
什么是死锁,为什么会产生死锁。我用 “事务把死锁给整出来啦” 标题下的两个事务产生的死锁来解释应该会更加生动形象点。
例子是这样的:
第一个事务(称为A):先更新lives表 --->>停顿5秒---->>更新earth表
第二个事务(称为B):先更新earth表--->>停顿5秒---->>更新lives表
先执行事务A----5秒之内---执行事务B,出现死锁现象。
过程是这样子的:
- A更新lives表,请求lives的排他锁,成功。
- B更新earth表,请求earth的排他锁,成功。
- 5秒过后
- A更新earth,请求earth的排它锁,由于B占用着earth的排它锁,等待。
- B更新lives,请求lives的排它锁,由于A占用着lives的排它锁,等待。
这样相互等待对方释放资源,造成资源读写拥挤堵塞的情况,就被称为死锁现象,也叫做阻塞。而为什么会产生,上例就列举出来啦。
然而数据库并没有出现无限等待的情况,是因为 数据库搜索引擎会定期检测这种状况,一旦发现有情况,立马选择一个事务作为牺牲品。牺牲的事务,将会回滚数据。有点像两个人在过独木桥,两个无脑的人都走 在啦独木桥中间,如果不落水,必定要有一个人给退回来。这种相互等待的过程,是一种耗时耗资源的现象,所以能避则避。
哪个人会被退回来,作为牺牲品,这个我们是可以控制的。控制语法:
set deadlock_priority <级别>
死锁处理的优先级别为 low<normal<high,不指定的情况下默认为normal,牺牲品为随机。如果指定,牺牲品为级别低的。
还可以使用数字来处理标识级别:-10到-5为low,-5为normal,-5到10为high。
减少死锁的发生,提高数据库性能
死锁耗时耗资源,然而在大型数据库中,高并发带来的死锁是不可避免的,所以我们只能让其变的更少。
- 按照同一顺序访问数据库资源,上述例子就不会发生死锁啦
- 保持是事务的简短,尽量不要让一个事务处理过于复杂的读写操作。事务过于复杂,占用资源会增多,处理时间增长,容易与其它事务冲突,提升死锁概率。
- 尽量不要在事务中要求用户响应,比如修改新增数据之后在完成整个事务的提交,这样延长事务占用资源的时间,也会提升死锁概率。
- 尽量减少数据库的并发量。
- 尽可能使用分区表,分区视图,把数据放置在不同的磁盘和文件组中,分散访问保存在不同分区的数据,减少因为表中放置锁而造成的其它事务长时间等待。
- 避免占用时间很长并且关系表复杂的数据操作。
- 使用较低的隔离级别,使用较低的隔离级别比使用较高的隔离级别持有共享锁的时间更短。这样就减少了锁争用。
可参考:http://msdn.microsoft.com/zh-cn/library/ms191242(v=sql.105).aspx
查看锁活动情况:
--查看锁活动情况
select * from sys.dm_tran_locks
--查看事务活动情况
dbcc opentran
可参考:http://msdn.microsoft.com/zh-cn/library/ms190345.aspx
为事务设置隔离级别
所谓事物隔离级别,就是并发事务对同一资源的读取深度层次。分为5种。
- read uncommitted:这个隔离级别最低啦,可以读取到一个事务正在处理的数据,但事务还未提交,这种级别的读取叫做脏读。
- read committed:这个级别是默认选项,不能脏读,不能读取事务正在处理没有提交的数据,但能修改。
- repeatable read:不能读取事务正在处理的数据,也不能修改事务处理数据前的数据。
- snapshot:指定事务在开始的时候,就获得了已经提交数据的快照,因此当前事务只能看到事务开始之前对数据所做的修改。
- serializable:最高事务隔离级别,只能看到事务处理之前的数据。
--语法
set tran isolation level <级别>
read uncommitted隔离级别的例子:
begin tran
set deadlock_priority low
update Earth set Animal='老虎'
waitfor delay '0:0:5' --等待5秒执行下面的语句
rollback tran
开另外一个查询窗口执行下面语句
set tran isolation level read uncommitted
select * from Earth --读取的数据为正在修改的数据 ,脏读
waitfor delay '0:0:5' --5秒之后数据已经回滚
select * from Earth --回滚之后的数据

read committed隔离级别的例子:
begin tran
update Earth set Animal='老虎'
waitfor delay '0:0:10' --等待5秒执行下面的语句
rollback tran
set tran isolation level read committed
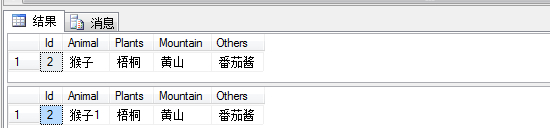
select * from Earth ---获取不到老虎,不能脏读
update Earth set Animal='猴子1' --可以修改
waitfor delay '0:0:10' --10秒之后上一个事务已经回滚
select * from Earth --修改之后的数据,而不是猴子
剩下的几个级别,不一一列举啦,自己理解吧。
设置锁超时时间
发生死锁的时候,数据库引擎会自动检测死锁,解决问题,然而这样子是很被动,只能在发生死锁后,等待处理。
然而我们也可以主动出击,设置锁超时时间,一旦资源被锁定阻塞,超过设置的锁定时间,阻塞语句自动取消,释放资源,报1222错误。
好东西一般都具有两面性,调优的同时,也有他的不足之处,那就是一旦超过时间,语句取消,释放资源,但是当前报错事务,不会回滚,会造成数据错误,你需要在程序中捕获1222错误,用程序处理当前事务的逻辑,使数据正确。
--查看超时时间,默认为-1
select @@lock_timeout
--设置超时时间
set lock_timeout 0 --为0时,即为一旦发现资源锁定,立即报错,不在等待,当前事务不回滚,设置时间需谨慎处理后事啊,你hold不住的。
仔细阅读,希望能分享给你一点点东西,谢谢,over。