卷积神经网络
起源:喵星人的视觉皮层
1958 年,一群奇葩的神经科学家把电极插到喵星人的脑子里,去观察视觉皮层的活动。从而推断生物视觉系统是从物体的小部分入手,
经过层层抽象,最后拼起来送入处理中心,减少物体判断的可疑性的。这种方法就与BP网络背道而驰。
BP网络认为,大脑每个神经元都要感知物体的全部(全像素全连接),并且只是简单的映射,并没有对物体进行抽象处理。
谁对谁错呢?卷积神经网络(Convolution Neural Network)最先证明了BP网络的不科学性。
CNN起源于机器学习大师LeCun在80年代末搞的支票数字识别神经网络。他在BP网络前面尝试了多层的卷积、降采样、以及部分网络连接的创意,
结果训练效果好得惊人。LeCun的导师是Hinton,也就是最先在2006年提出深度学习(Deep Learning)概念的计算机科学家兼神经科学家。
LeCun本人也算是半个神经科学家。师徒二人携手撑起了深度学习的蓝天。
Part I:图像的卷积与降采样
卷积运算具有平滑、模糊信号的效果,它对原始信号与卷积核邻域做了乘积加权和。一幅图像可分为噪声、细节两部分。
卷积运算合并了信号部分内容之后,起到了消除噪声,突出细节两个作用。同时,卷积运算的参数也是可以由机器自动训练的,这就成为神经网络的瞄准对象。
CNN中使用的是二维卷积,卷积方式很简单:参考http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
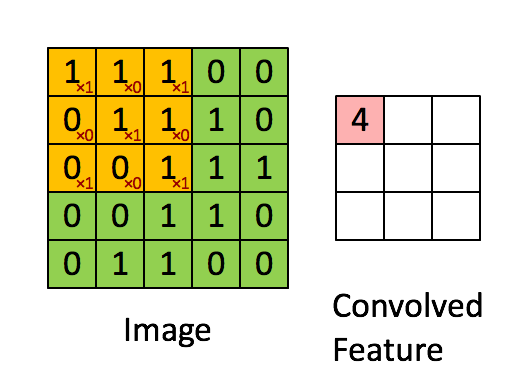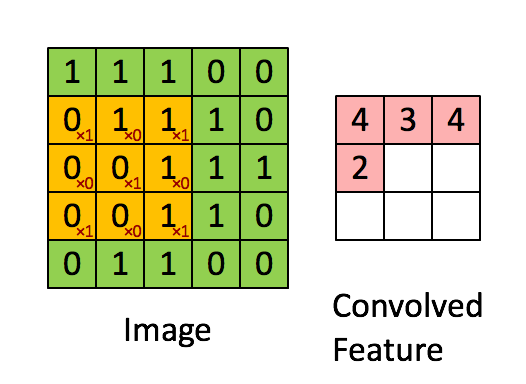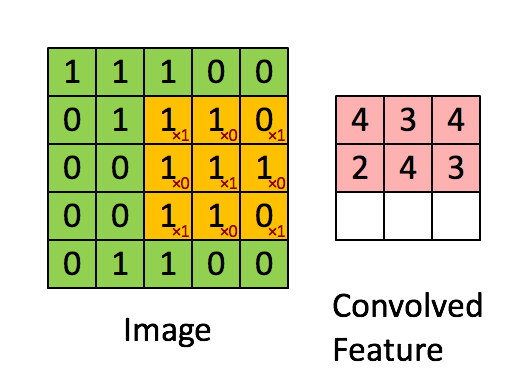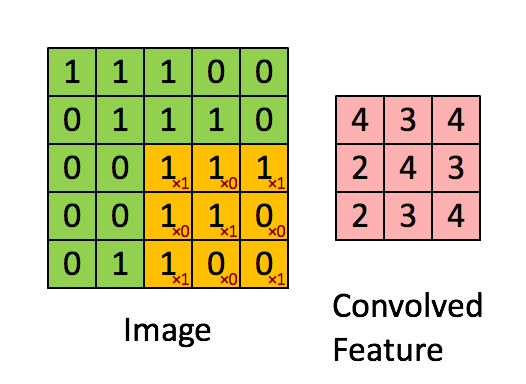
上图为vaild卷积,还有一种full卷积,考虑将卷积核移到源图像之外,vaild卷积维度会变小,full会变大(一般不用)
vaild:Dimnew=Dimold−filter.Dim+1
full:Dimnew=Dimold+filter.Dim−1
当然这是后话。二维离散卷积的定义是这样的:g与f顺序是不一样的
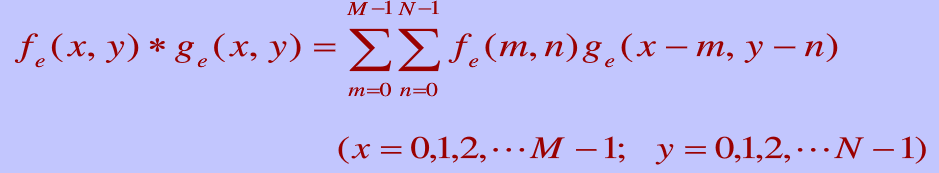
上图中黄色3*3卷积核实际上在做滑动乘积之前,被旋转了180度。
⎡⎣⎢135246⎤⎦⎥=>⎡⎣⎢642531⎤⎦⎥
所以手写卷积时,千万不要忘记了卷积核旋转。
降采样(Pooling)对应一个size,假如是(2,2),那么每2X2的像素会被合并为1个像素。
有取最大值作为新值的,以便更加突出特征的Max Pooling方法。
也有取均值作为新值的,以便更加平滑特征的Mean Pooling方法。
当然这些都不是重点,pooling强制把像素降了一个量级,①降低了计算量②保证了缩放、旋转不变性[?]
Part II CNN的结构
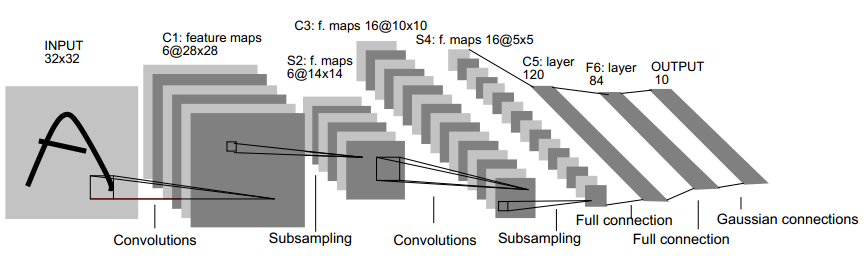
这是LeCun的LeNet5结构,通常拿来作为CNN的教学。
首先要区分一个概念,filter和feature map。feature map就是上面的一块大板子,size是28x28
filter指的是卷积核,filter的数量决定着下一层大板子的数量,size就是卷积核大小。
卷积嵌入到神经网络里,就有了一个权值共享的概念。传统的神经网络,对28x28像素,会有784个神经元,如果下一层也有784个神经元,那么就需要784*784个权值。
但是卷积神经网络里,将卷积核权值看成是神经元,一个卷积核才多大?5x5=25罢了,784个像素共用这25个神经元,滚来滚去,也就是一套权值。
研究表明,卷积核数量与数据量规模没有多少关系,而且根据视觉系统的特性,随着层数加深,才有必要增加核数,且不多。比如LeNet的卷积层也就6、16个核
这样,全连接过程中,尽管需要Num(层K)*Num(层K-1)套权值,但是由于每层feature map数量有限,且一套权值规模又不大,所以训练起来很轻松。
Theano的注释中用4D张量(其实就是个大小为4的数组)来表示结构转移,假设一个batch有500张图片,都是黑白单通道。
(图片数,map数,高,宽)---image/input/output, input的map数即为通道数,比如RGB有三个通道,视为3。
(filter数,map数,高,宽)---filter
I/O的转移如下:(500,1,32,32)=>(500,6,28,28)=>(500,6,14,14)=>(500,16,10,10)=>(500,16,5,5)=>(500,120,1,1),下面就是隐层+分类器了。
filter的转移如下:(6,1,5,5)=>(16,6,5,5)=>(120,16,5,5)
值得注意的是卷积之后的sigmoid,以及偏置b。
因为是全连接,前一层的map卷积并且结果叠加后,送入sigmoid处理。新一层的每张map的每个像素统一加上b。(Theano中把一维b转成了四维)
也就是说b等于filter的数量,而不是和W的数量一致。tornadomeet中的解释是错的。
当然,因为下面还有降采样,所以sigmoid、偏置b可以留到降采样结束后再加上去,形成下一层的input。
LeCun在构建S2的6个map=>C3的16个map时,并没有采用全连接的方式,而是采用更切合生物视觉的部分连接。参考tornadomeet的解释。
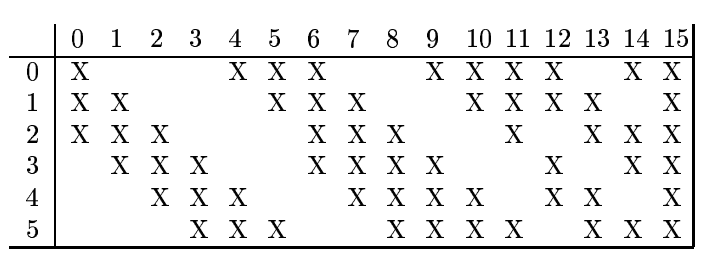
这样,更好的区分了特征,但是不太好实现。所以Theano干脆就利用conv2d封装的全连接写法搞了个简易版本。
若是具体实现的话,我觉得首先得把output的map给reshape,然后利用这些map,在conv2d手艹16个单map,组合成下一层的input