下面内容出自:https://www.bilibili.com/video/BV1Xa4y1n7Rs?from=search&seid=12323657797647836565
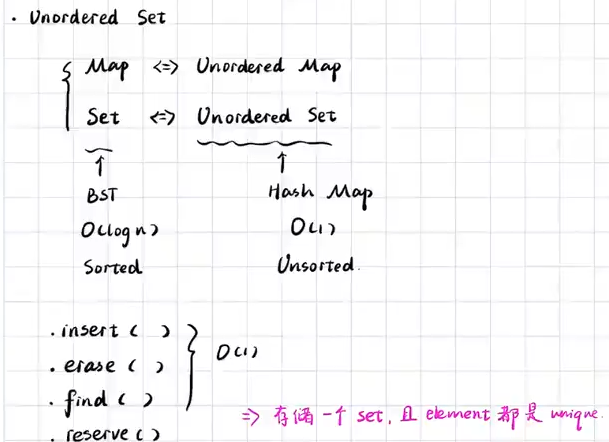
基于balance search tree (BST)的容器探索:
set:每一个value都不是重复的 这个特性经常会被用到
.insert() :往容器中加入元素,相当于vector的.pushback()
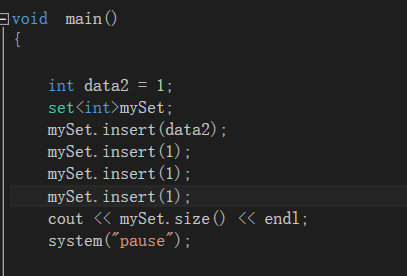

不管插入多少个相同的数字,实际上只会存储一个。

时间复杂度为上面这个,这是因为当添加的时候会事先进行搜索,这个搜索的时间复杂度为Olog(n),
find: .find(value) 用来查找容器中是否有某一个值 时间复杂度照样是0log(n)
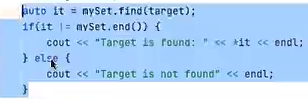
加上上面这一段进行提示搜索的情况,同样适用于其他容器。
erase: .erase(iterator)
在删除之前应该进行这个数字的检查,不然会出现未知的错误,应该添上下面的语句:

时间复杂度同样是olog(n) 因为当删除迭代器对应的数时,看上去是olog(1),实际上在删除之后整个balance tree 会重新进行调整,这个时间复杂度是olog(n)
set的member function 也能返回key值的iterator ,使用方法为:
.lower_bound 和 . upper.bound

关于set的内容就到这了!!!
map / multimap map中key is unique
这个容器是含有两个参数的模版类:每一个都是以pair键值对的形式存在的
pair<key_type, data_type>
例如:
pair<int,string>
pair<int,int>
使用方式:
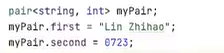
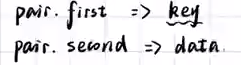
find使用方式和上面的set容器使用方式一样,就是返回指针的时候需要使用箭头访问成员变量。时间复杂度 0log(n)
erase的使用和上面也是一样的 时间复杂度也是olog(n)
lower_bound 和 upper_bound 也和上面是一样的
[ ] :方括号使用的方式是 通过key进行查询value 的值,这种使用方式类似于数组的使用
multimap:key的取值不是唯一的是可以重复的
vector 是只有一个模版参数的模版类
vector<type>
multimap:每一个value可以是重复的 就这一点和map不相同,其他的全相同。
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
基于hash _table 的容器
unordered map(not sorted)
map所有的操作都适用于underedmap
当知道自己要存储的data的时候,可以提前进行data_base 的提前reserve,这样可以避免多次的memory copy
undered set
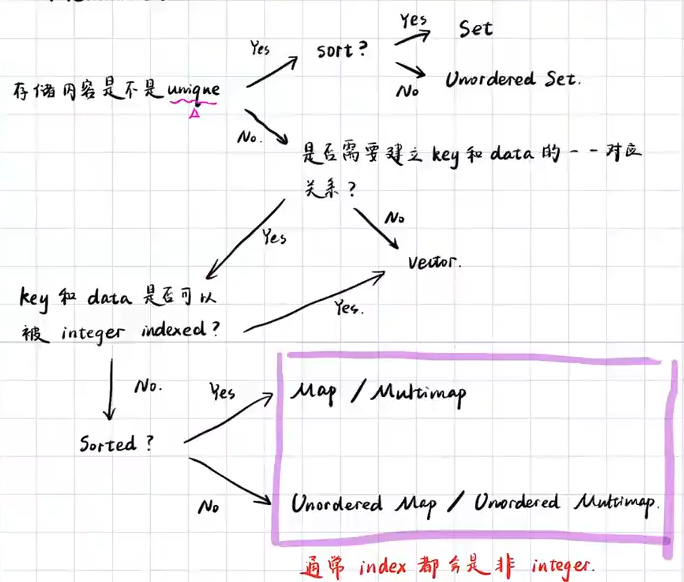
容器选择:
优先队列:
