前言
本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,想了解前因后果的可以看上一篇和上上篇。
opentsdb在hbase中生成4个表(tsdb, tsdb-meta, tsdb-tree, tsdb-uid),其中tsdb这个表最重要,数据迁移时,备份还原此表即可。
一、本地数据备份恢复
1、备份
本文测试本地备份服务器hostname:hbase3,ip为192.168.0.214。
# 进入shell命令 hbase shell # 快照tsdb表:快照名snapshot_tsdb_214 snapshot 'tsdb','snapshot_tsdb_214' ## 查看快照 # 1、shell查看快照 list_snapshots # 2、hdfs 查看快照:在hdfs的 /hbase/.hbase-snapshot 目录下可以查看所有快照 hdfs dfs -ls -R /hbase/.hbase-snapshot

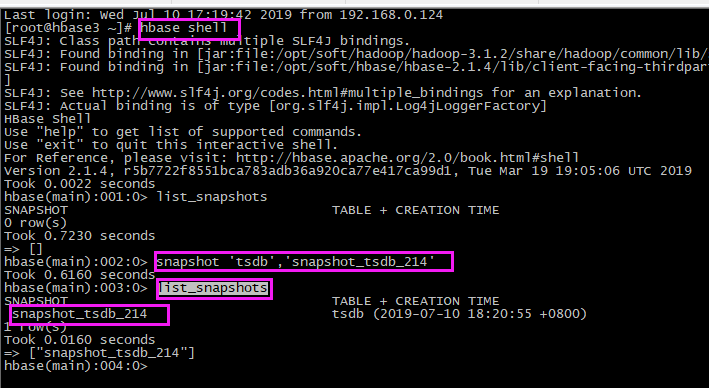
2、还原
【1】原数据查看
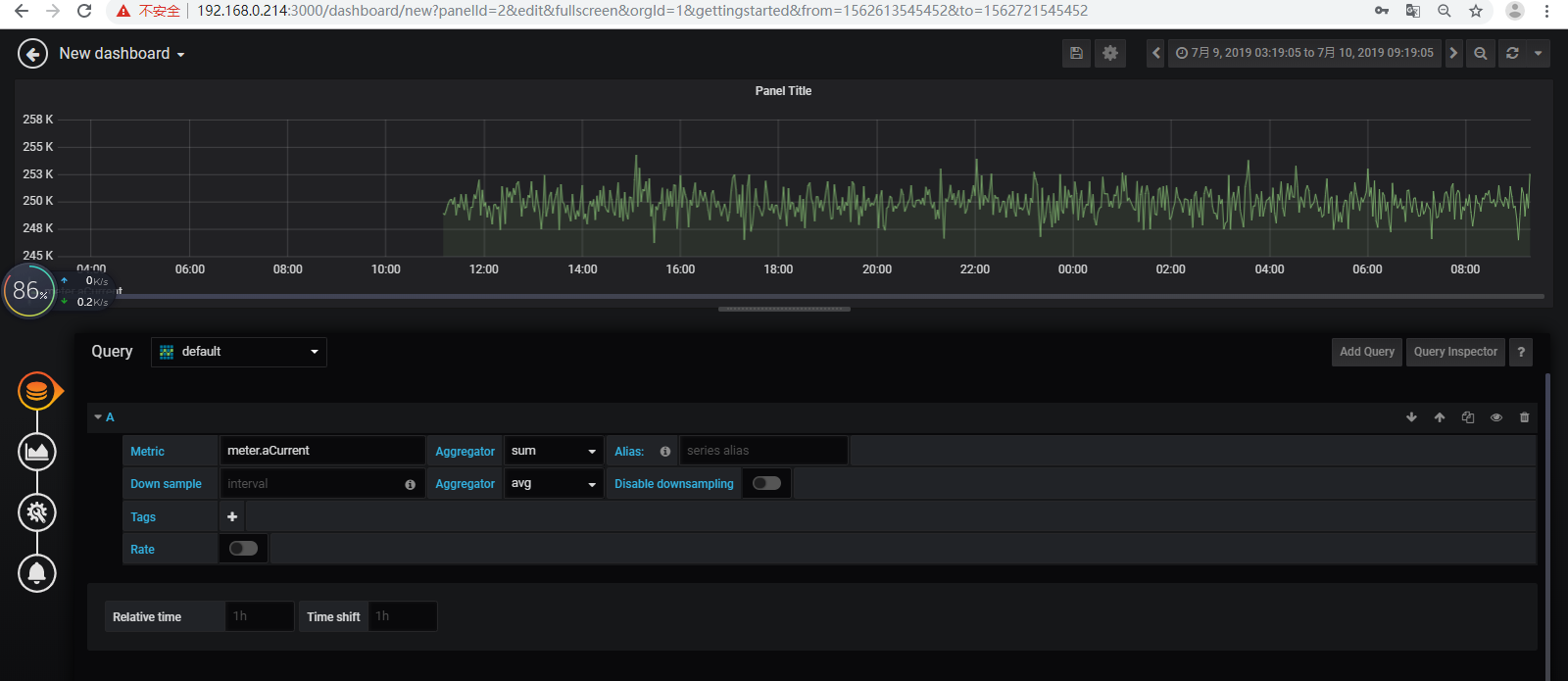
【2】删除表
# disable表 disable 'tsdb' # 查看 drop 'tsdb'

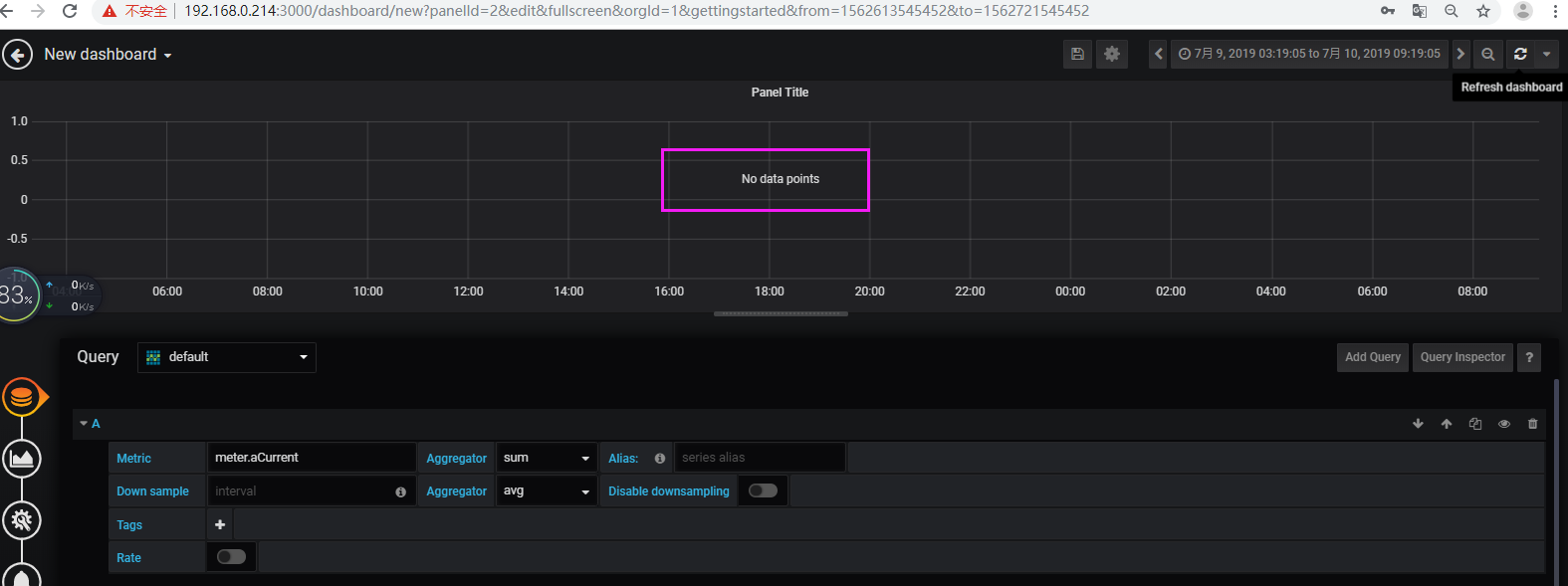
【3】还原
# 恢复快照 restore_snapshot 'snapshot_tsdb_214'
# 查看表是否生成
list
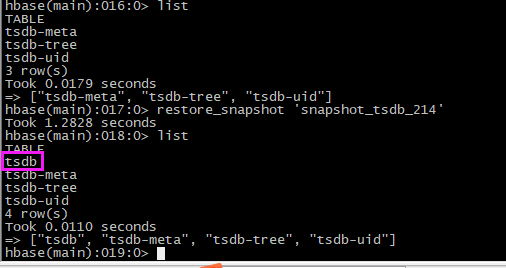
【4】验证
二、数据迁移:从一台服务器迁移到另一台服务器
本文从hbase3(ip:192.168.0.214)迁移到hbase1(ip:192.168.0.211),这两台服务器搭建的环境一样,并且做了互相免密登录,在第一步已经在hbase3对tsdb做了快照snapshot_tsdb_214,先接下来要做的是,将此快照迁移到hbase1服务器上。
1、迁移快照
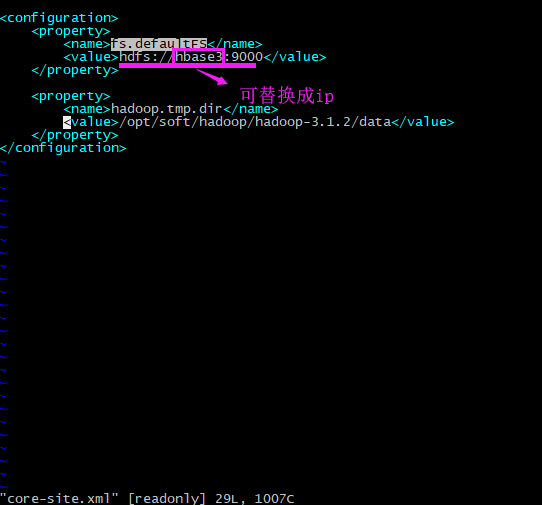
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshot_tsdb_214 -copy-from hdfs://192.168.0.214:9000/hbase -copy-to hdfs://192.168.0.211:9000/hbase -mappers 20 -bandwidth 1024
注:标黄的部分是hadoop的core-site.xml配置文件中,配置的fs.defaultFS的值。
2、解决报错:Java heap space
【1】报错日志
2019-07-11 10:09:09,875 INFO [main] snapshot.ExportSnapshot: Copy Snapshot Manifest from hdfs://192.168.0.214:9000/hbase/.hbase-snapshot/snapshot_tsdb_214 to hdfs://192.168.0.211:9000/hbase/.hbase-snapshot/.tmp/snapshot_tsdb_214 2019-07-11 10:09:10,942 INFO [main] client.RMProxy: Connecting to ResourceManager at hbase3/192.168.0.214:8032 2019-07-11 10:09:13,100 INFO [main] snapshot.ExportSnapshot: Loading Snapshot 'snapshot_tsdb_214' hfile list 2019-07-11 10:09:13,516 INFO [main] mapreduce.JobSubmitter: number of splits:5 2019-07-11 10:09:13,798 INFO [main] mapreduce.JobSubmitter: Submitting tokens for job: job_1562738985351_0004 2019-07-11 10:09:14,061 INFO [main] impl.YarnClientImpl: Submitted application application_1562738985351_0004 2019-07-11 10:09:14,116 INFO [main] mapreduce.Job: The url to track the job: http://hbase3:8088/proxy/application_1562738985351_0004/ 2019-07-11 10:09:14,116 INFO [main] mapreduce.Job: Running job: job_1562738985351_0004 2019-07-11 10:09:23,331 INFO [main] mapreduce.Job: Job job_1562738985351_0004 running in uber mode : false 2019-07-11 10:09:23,333 INFO [main] mapreduce.Job: map 0% reduce 0% 2019-07-11 10:09:34,529 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000000_0, Status : FAILED Error: Java heap space 2019-07-11 10:09:40,659 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000001_0, Status : FAILED Error: Java heap space 2019-07-11 10:09:44,717 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000002_0, Status : FAILED Error: Java heap space 2019-07-11 10:09:44,719 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000003_0, Status : FAILED Error: Java heap space 2019-07-11 10:09:45,728 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000004_0, Status : FAILED Error: Java heap space 2019-07-11 10:09:52,781 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000000_1, Status : FAILED Error: Java heap space 2019-07-11 10:09:57,830 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000001_1, Status : FAILED Error: Java heap space 2019-07-11 10:10:03,886 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000002_1, Status : FAILED Error: Java heap space 2019-07-11 10:10:03,887 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000003_1, Status : FAILED Error: Java heap space 2019-07-11 10:10:05,910 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000004_1, Status : FAILED Error: Java heap space 2019-07-11 10:10:10,965 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000000_2, Status : FAILED Error: Java heap space 2019-07-11 10:10:16,015 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000001_2, Status : FAILED Error: Java heap space 2019-07-11 10:10:21,068 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000002_2, Status : FAILED Error: Java heap space 2019-07-11 10:10:23,083 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000003_2, Status : FAILED Error: Java heap space 2019-07-11 10:10:24,089 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000004_2, Status : FAILED Error: Java heap space 2019-07-11 10:10:30,148 INFO [main] mapreduce.Job: map 20% reduce 0% 2019-07-11 10:10:31,156 INFO [main] mapreduce.Job: map 100% reduce 0% 2019-07-11 10:10:31,161 INFO [main] mapreduce.Job: Job job_1562738985351_0004 failed with state FAILED due to: Task failed task_1562738985351_0004_m_000000 Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0 2019-07-11 10:10:31,285 INFO [main] mapreduce.Job: Counters: 12 Job Counters Failed map tasks=16 Killed map tasks=4 Launched map tasks=20 Other local map tasks=20 Total time spent by all maps in occupied slots (ms)=288607 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=288607 Total vcore-milliseconds taken by all map tasks=288607 Total megabyte-milliseconds taken by all map tasks=295533568 Map-Reduce Framework CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 2019-07-11 10:10:31,288 ERROR [main] snapshot.ExportSnapshot: Snapshot export failed org.apache.hadoop.hbase.snapshot.ExportSnapshotException: Task failed task_1562738985351_0004_m_000000 Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0 at org.apache.hadoop.hbase.snapshot.ExportSnapshot.runCopyJob(ExportSnapshot.java:839) at org.apache.hadoop.hbase.snapshot.ExportSnapshot.doWork(ExportSnapshot.java:1078) at org.apache.hadoop.hbase.util.AbstractHBaseTool.run(AbstractHBaseTool.java:154) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.hadoop.hbase.util.AbstractHBaseTool.doStaticMain(AbstractHBaseTool.java:280) at org.apache.hadoop.hbase.snapshot.ExportSnapshot.main(ExportSnapshot.java:1141)
【2】异常分析
这个报错信息是jvm的堆内存不够,便查询了hadoop运行mapreduce的时候jvm的默认值,得知在 hadoop的mapred-site.xml配置中有一个mapred.child.java.opts的参数,用于jvm运行时heap的运行参数和垃圾回收之类的参数的配置,heap的-Xmx默认值为200m,报错说明这个值是不够的,于是解决方案就是加大这个值。
这个值设置多大合适?https://blog.csdn.net/wjlwangluo/article/details/76667999文中说:一般情况下,该值设置为 总内存/并发数量(=核数)
【3】解决方案
# 进入目录 cd /opt/soft/hadoop/hadoop-3.1.2/etc/hadoop # 进入文件编辑模式
vim mapred-site.xml # 添加以下内容 <property> <name>mapred.child.java.opts</name> <value>-Xmx1024m</value> </property>
【4】验证
# 重启hadoop、hbase:注意先停habse,并且不要要kill,因为hadoop在不断的切割,用stop停止,它会记录下来,下次启动继续切割 stop-hbase.sh stop-all.sh start-all.sh start-hbase.sh # 再次迁移快照
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshot_tsdb_214 -copy-from hdfs://192.168.0.214:9000/hbase -copy-to hdfs://192.168.0.211:9000/hbase -mappers 20 -bandwidth 1024
查看进度是成功的:
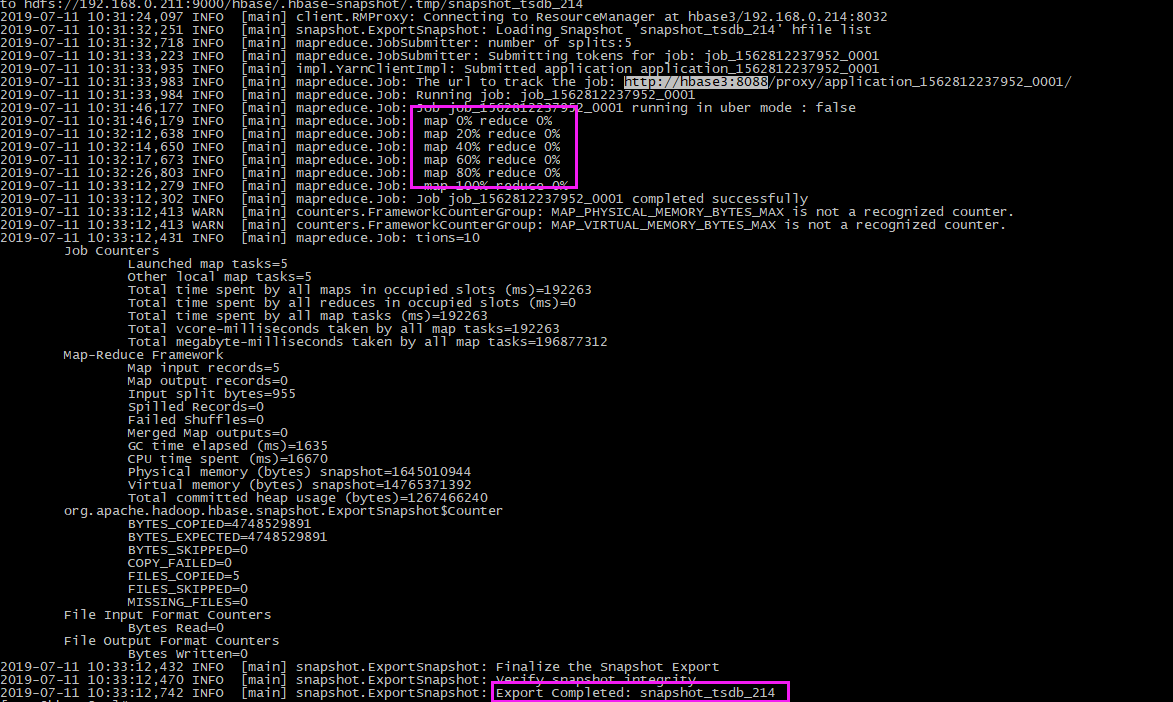
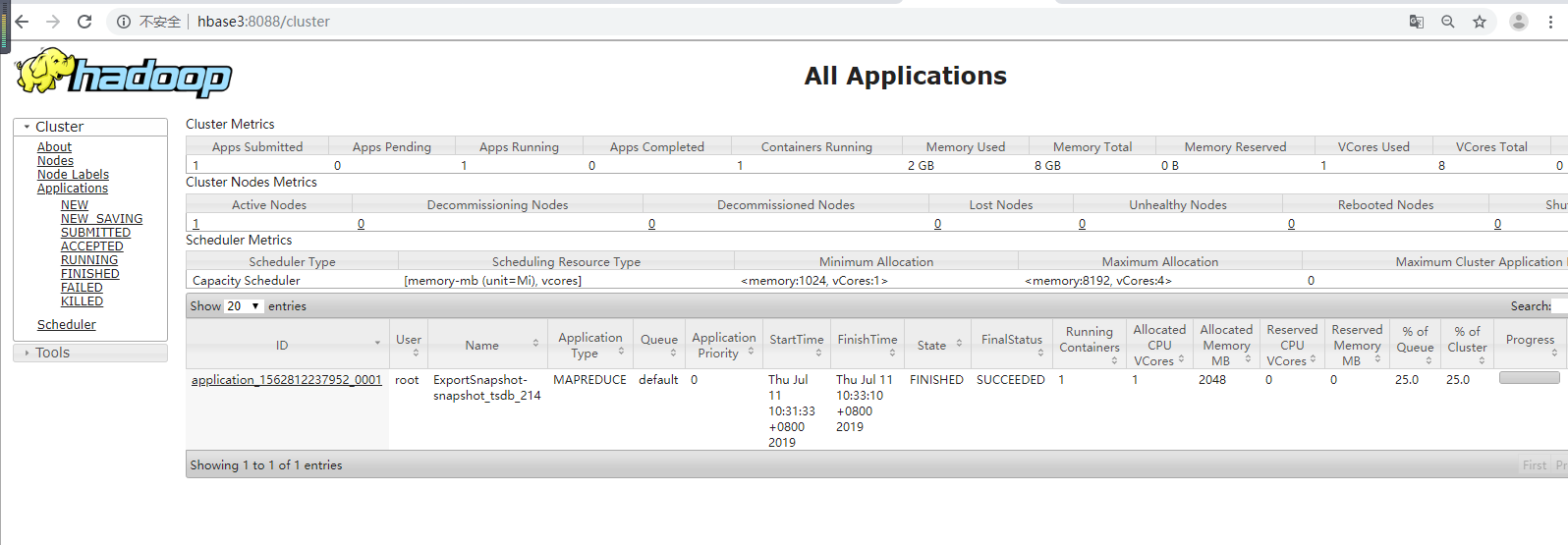
迁移过程中,在hbase1 上会产生 快照的 ./tmp文件
# 查看 hdfs上快照文件 hdfs dfs -ls -R /hbase/.hbase-snapshot
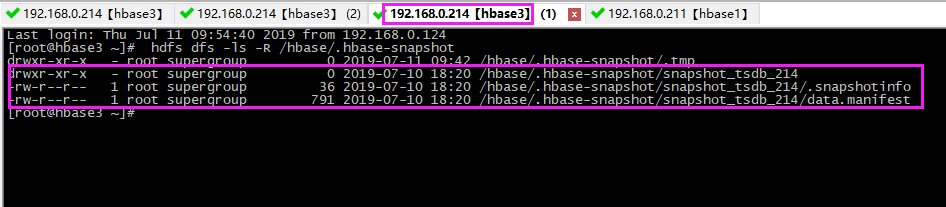
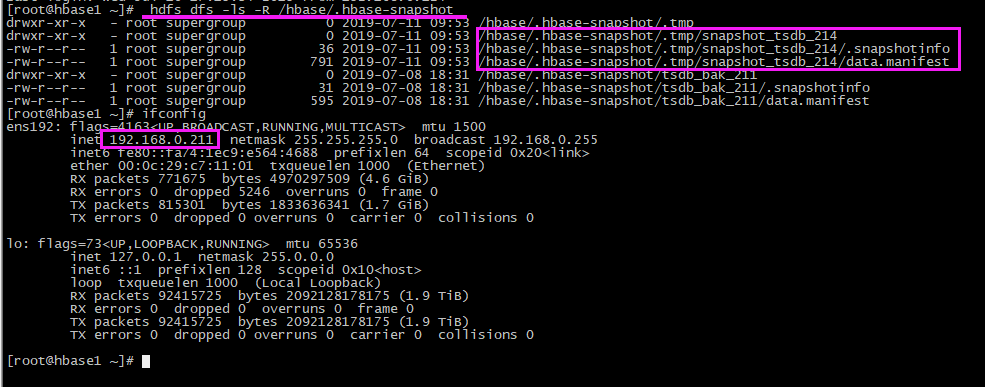
迁移完毕,在hbase1 上会生成了相应的快照
# 进入shell命令
habase shell
# 查看快照
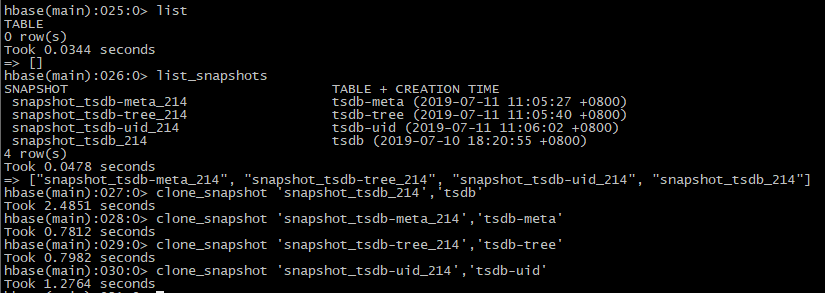
list_snapshot

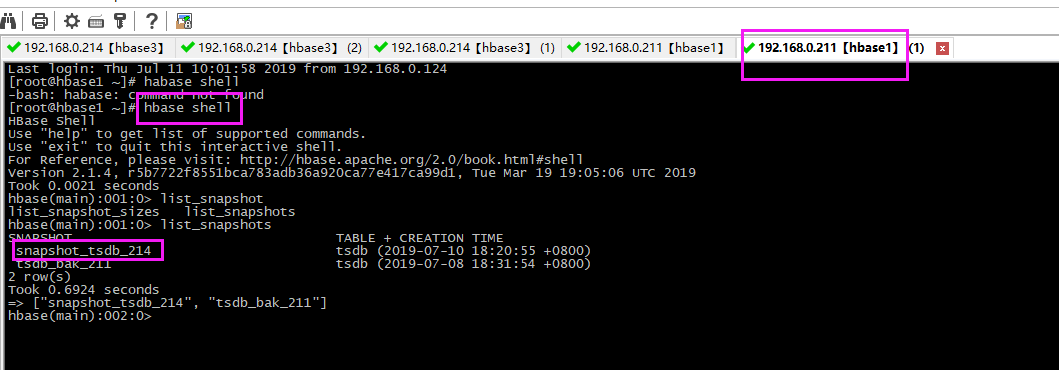
3、恢复数据
【1】删除hbase1的原始数据
## 我这里还是直接删除tsdb表 # disable表 disable 'tsdb' # 查看 drop 'tsdb'
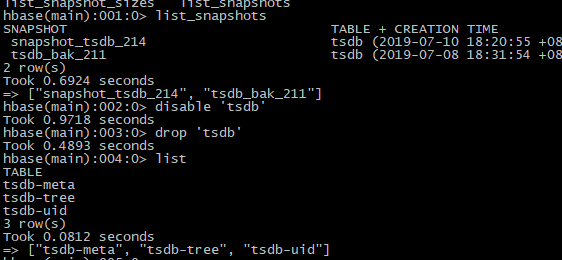

【2】还原数据
clone_snapshot 'snapshot_tsdb_214','tsdb'
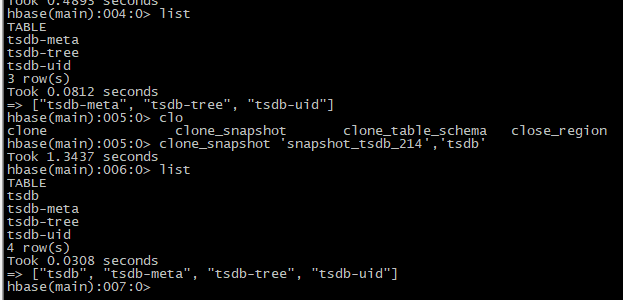
【3】验证
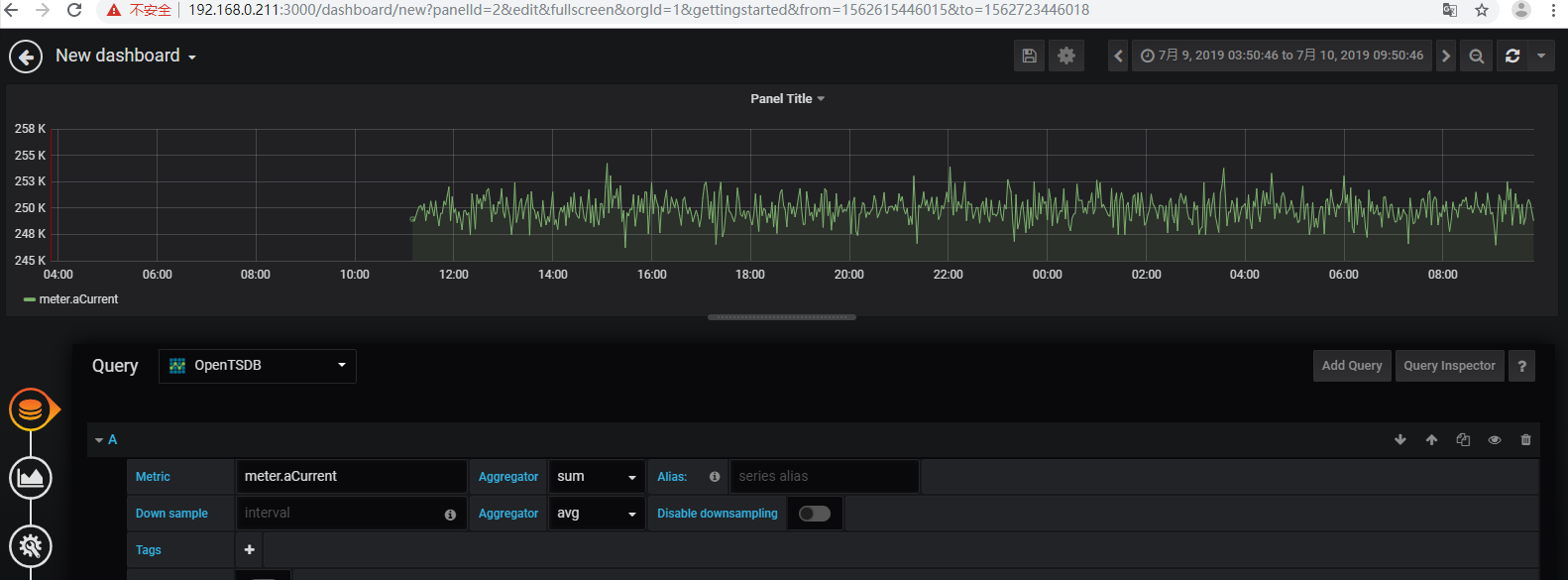
查验tsdb表存在且有数据,但是grafana查验无数据

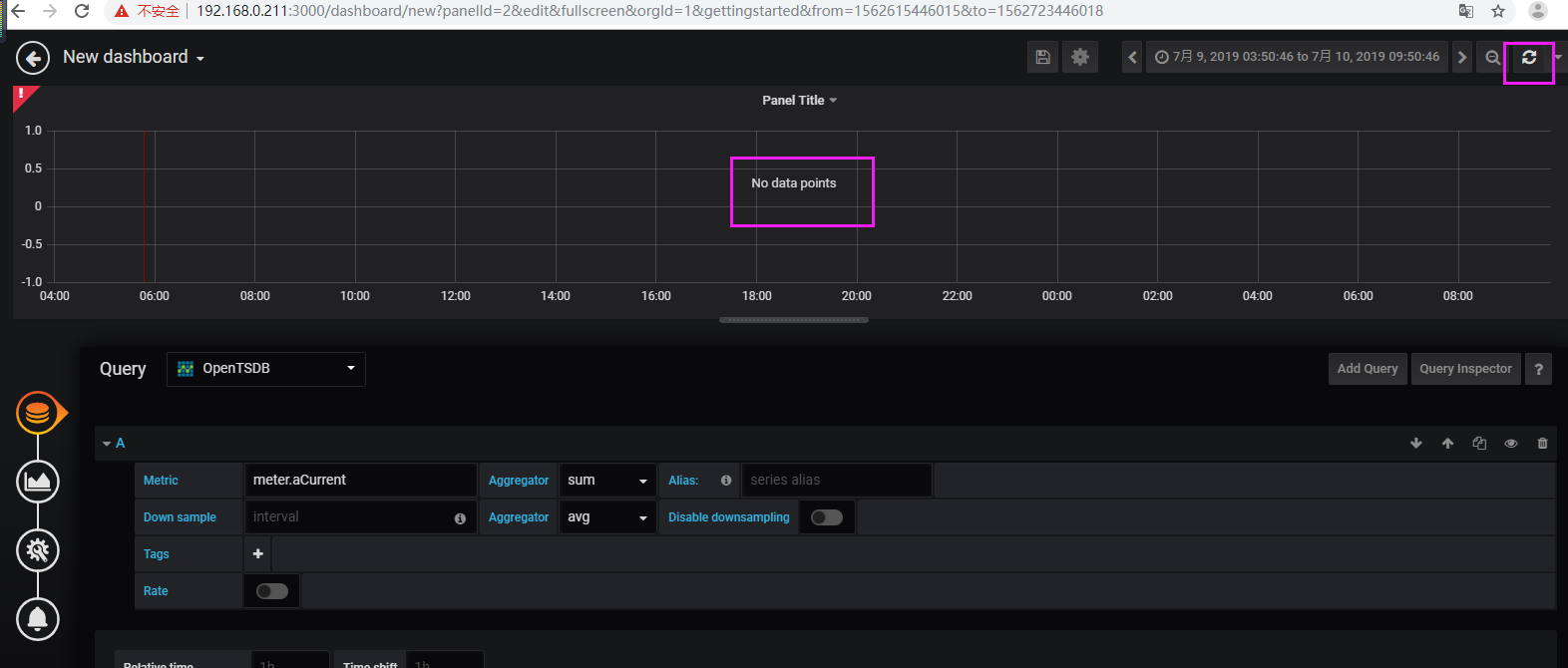
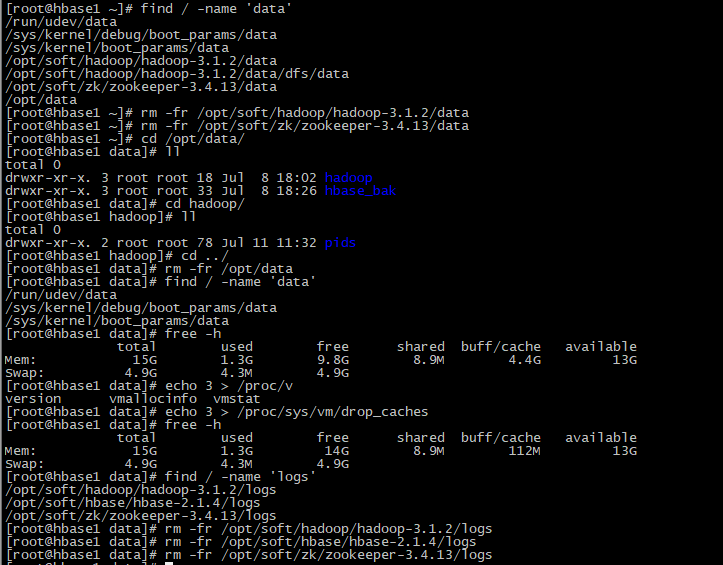
停止hadoop、zookeeper、hbase、opentsdb,删除了hbase1上的所有logs和data,格式化hdfs之后,再重启所有程序,再将tsdb相关的4个快照从214迁移过来进行还原,再次刷新就有数据了
三、总结
1、后面经验证,是opentsdb挂掉了,当opentsdb正常的时候,直接到上面第2步,只需要备份还原tsdb皆可。
2、另外验证restore_snapshot未成功,所以暂定还原用 clone_snapshot方法。
3、已验证,将快照传到目的服务器后,关闭源服务器,也可以进行还原。
4、验证:先把快照拷贝到本地,然后再上传到目的服务器的hdfs里面,进行恢复,结果:验证失败。