- Spark最初的设计目标是使数据分析更快——不仅运行速度快,也要能快速、容易地编写程序。为了使程序运行更快,Spark提供了内存计算,减少了迭代计算时的IO开销;而为了使编写程序更为容易Spark使用简练、优雅的Scala语言编写,基于Scala提供了交互式的编程体验。虽然,Hadoop已成为大数据的事实标准,但其MapReduce分布式计算模型仍存在诸多缺陷,而Spark不仅具备Hadoop MapReduce所具有的优点,且解决了Hadoop MapReduce的缺陷。Spark正以其结构一体化、功能多元化的优势逐渐成为当今大数据领域最热门的大数据计算平台。
- 由于Spark采用Scala语言进行开发,因此,建议采用Scala语言进行Spark应用程序的编写。Scala是一门现代的多范式编程语言,平滑地集成了面向对象和函数式语言的特性,旨在以简练、优雅的方式来表达常用编程模式。Scala语言的名称来自于“可伸展的语言”,从写个小脚本到建立个大系统的编程任务均可胜任。Scala运行于Java平台(JVM,Java 虚拟机)上,并兼容现有的Java程序。
- Spark生态系统
在实际应用中,大数据处理主要包括以下三个类型:
复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间;
基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间;
基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
Spark专注于数据的处理分析,而数据的存储还是要借助于Hadoop分布式文件系统HDFS、Amazon S3等来实现的。
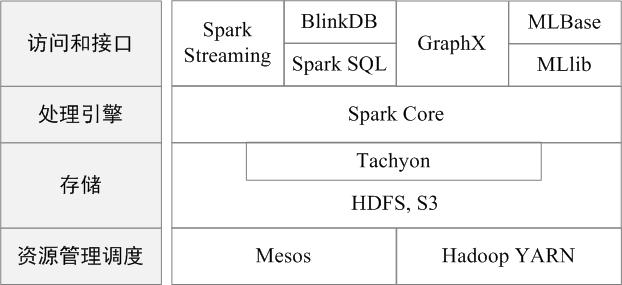
图 BDAS架构
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
Spark Core:Spark
Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache
Spark,就是指Spark Core;
Spark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。