章节十七:模块
1. 什么是模块
之前我们已经学过,类可以封装方法和属性,就像这样:
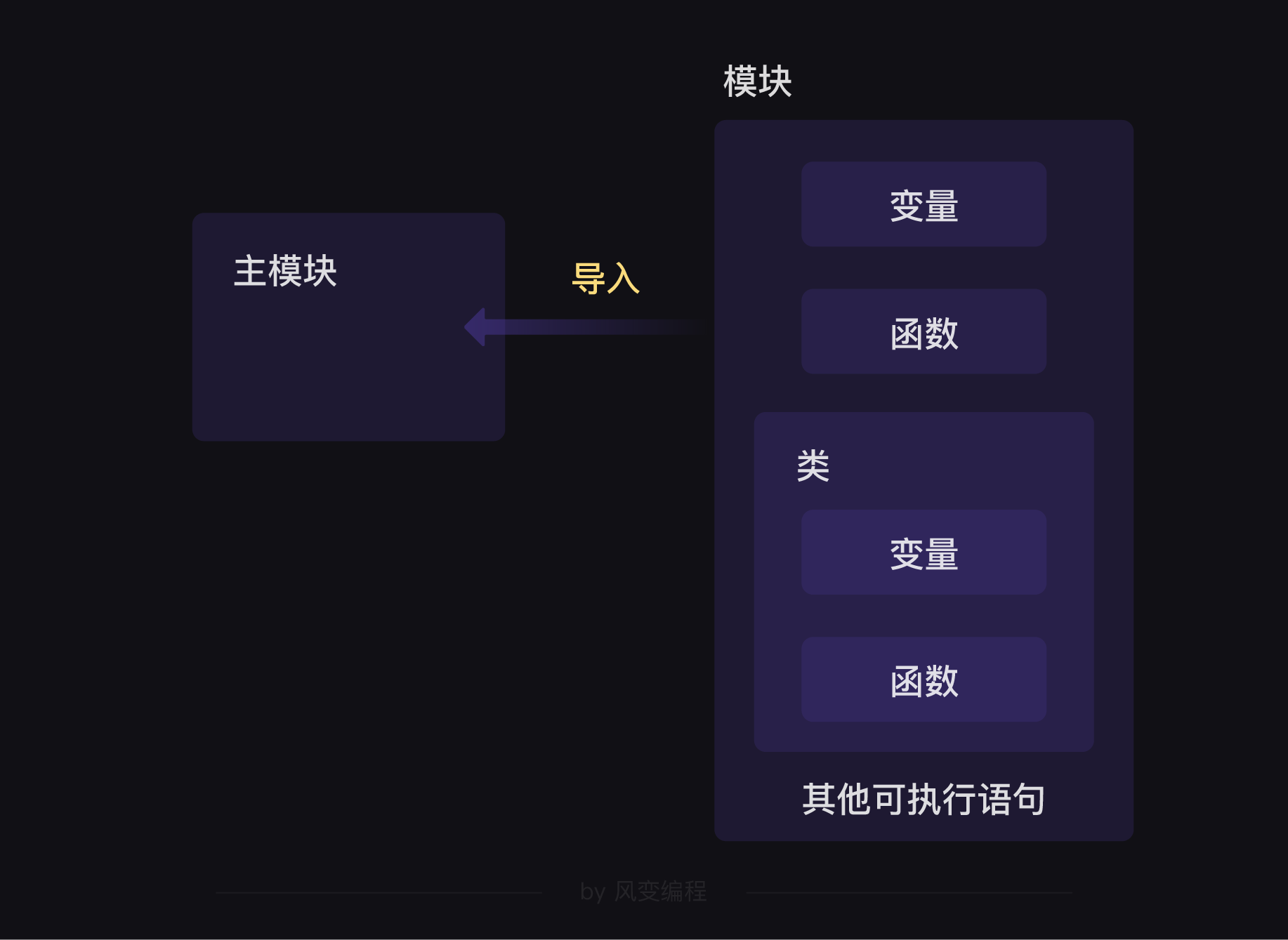
用书里的话说:模块是最高级别的程序组织单元。这句话的意思是,模块什么都能封装,就像这样:

在模块中,我们不但可以直接存放变量,还能存放函数,还能存放类。

更独特的是,定义变量需要用赋值语句,封装函数需要用def语句,封装类需要用class语句,但封装模块不需要任何语句。
之所以不用任何语句,是因为每一份单独的Python代码文件(后缀名是.py的文件)就是一个单独的模块。
如果你使用过vscode或pycharm等编程工具编写python程序,每次都需要先创建一个后缀名为.py的Python程序文件,才能运行程序:
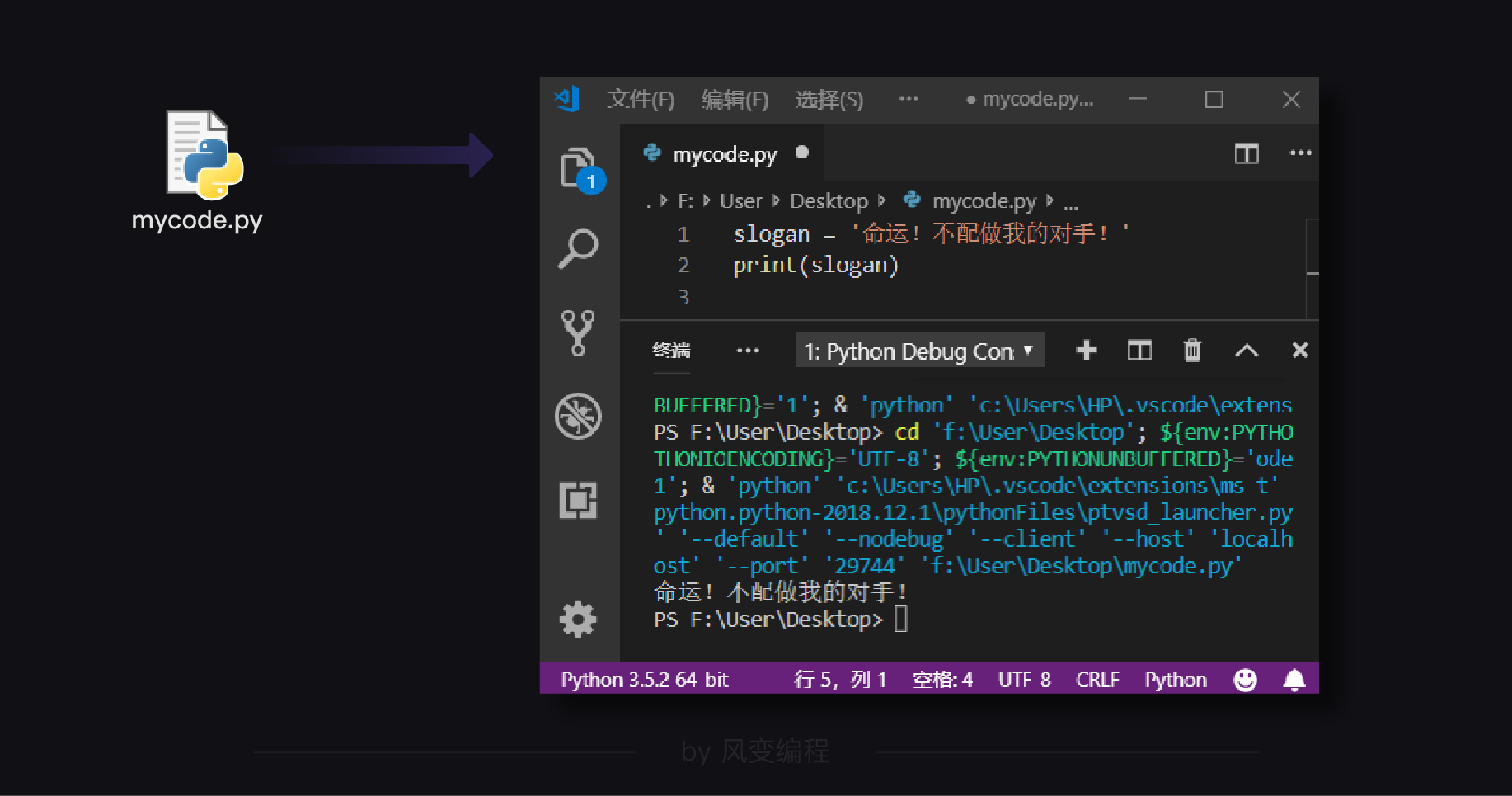
在平时的课堂教学中,其实我们每次运行的代码,本质上都是在运行一个名为main.py的程序文件:(只不过被隐藏在了终端里)
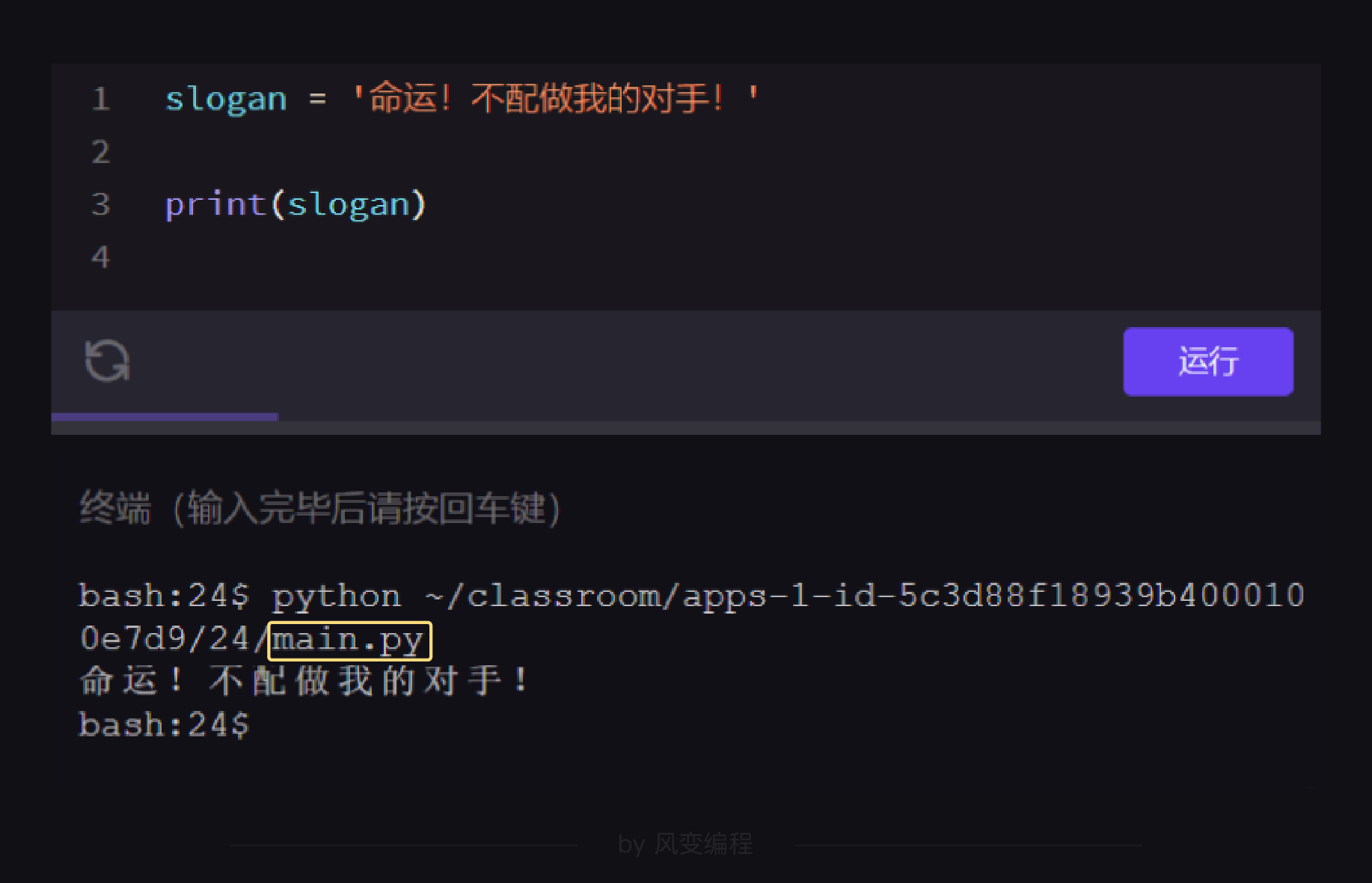
像这样:每一个单独的py文件,本质上都是一个模块。
封装模块的目的也是为了把程序代码和数据存放起来以便再次利用。如果封装成类和函数,主要还是便于自己调用,但封装了模块,我们不仅能自己使用,文件的方式也很容易共享给其他人使用。
所以,我们使用模块主要有两种方式,一种是自己建立模块并使用,另外一种是使用他人共享的模块。
2. 使用自己的模块
建立模块,其实就是在主程序的py文件中,使用import语句导入其他py文件。
我们看一个小例子,这个例子中有两个模块,一个是test.py文件,另一个是main.py文件。
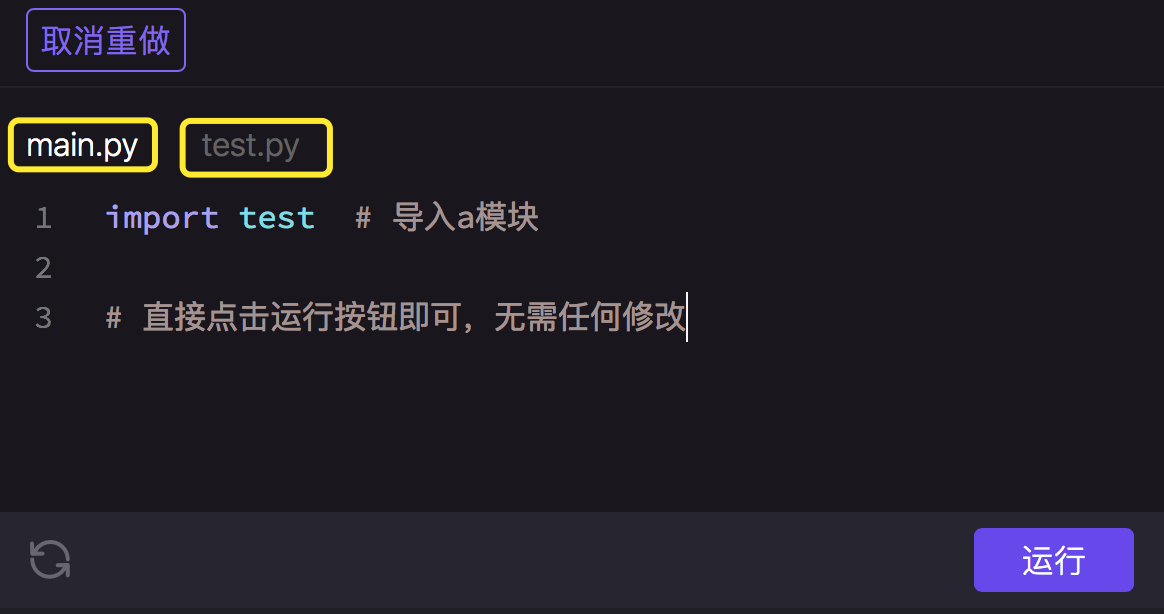
请你阅读两个文件中的代码,并直接运行main.py文件。

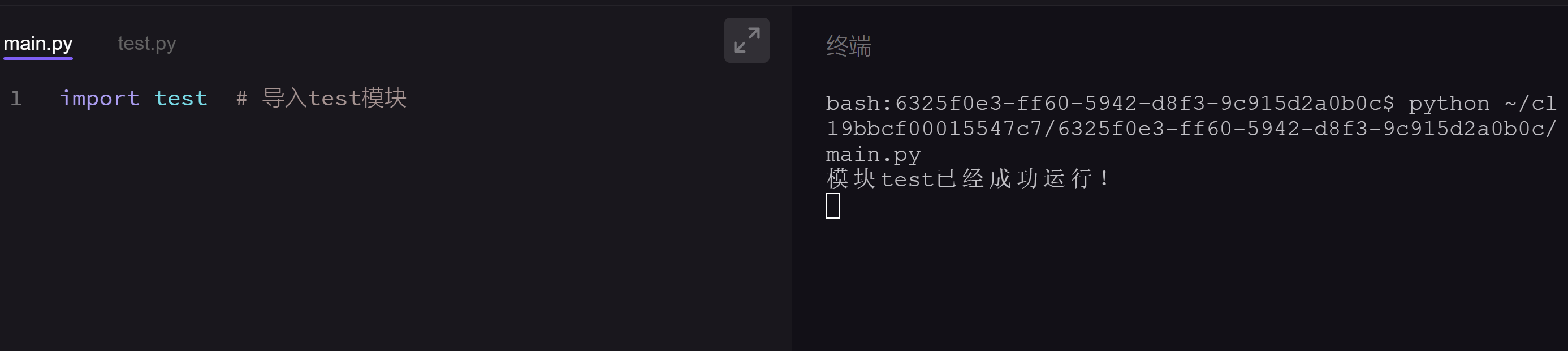
你看,是不是发现main.py文件借用并运行了test.py文件里的代码了?这就是import语句起作用了。
模块相关的常用语句主要有3个,我们接下来一个个来看。
2.1 import语句
我们使用import语句导入一个模块,最主要的目的并不是运行模块中的执行语句,而是为了利用模块中已经封装好的变量、函数、类。
再来看一个案例。
a = '我是模块中的变量a'
def hi():
a = '我是函数里的变量a'
print('函数“hi”已经运行!')
class Go2:
a = '我是类2中的变量a'
def do2(self):
print('函数“do2”已经运行!')
print(a) # 打印变量“a”
hi() # 调用函数“hi”
A = Go2() # 实例化“Go2”类
print(A.a) # 打印实例属性“a”
A.do2() # 调用实例方法“do2”
麻雀虽小,五脏俱全。这段代码中基本上展现了所有的调用方式。
现在我们要做的是把这段代码拆分成两个模块,把封装好的变量、函数、类,放到test.py文件中,把执行相关的语句放到main.py文件中。


你是否注意到,当我们导入模块后,要使用模块中的变量、函数、类,需要在使用时加上模块.的格式。请阅读主程序main.py的代码注释:
# 这是主程序main.py
# 请阅读代码注释
import test # 导入test模块
print(test.a) # 使用“模块.变量”调用模块中的变量
test.hi() # 使用“模块.函数()”调用模块中的函数
A = test.Go2() # 使用“变量 = 模块.类()”实例化模块中的类
print(A.a) # 实例化后,不再需要“模块.”
A.do2() # 实例化后,不再需要“模块.”
到这里,我们来做个练习。下面有一段代码:
sentence = '从前有座山,'
def mountain():
print('山里有座庙,')
class Temple:
sentence = '庙里有个老和尚,'
def reading(self):
print('在讲一个长长的故事。')
for i in range(10):
print(sentence)
mountain()
A = Temple()
print(A.sentence)
A.reading()
print()
请你把这段代码拆分到两个模块中,其中执行语句放到main.py文件,封装好的变量、函数和类放到story.py文件。


import语句还有一种用法是import…as…。比如我们觉得import story太长,就可以用import story as s语句,意思是为“story”取个别名为“s”。
上面的案例中,main.py文件可以写成这样:
# 文件:main.py
import story as s
for i in range(10):
print(s.sentence)
s.mountain()
A = s.Temple()
print(A.sentence)
A.reading()
print()
另外,当我们需要同时导入多个模块时,可以用逗号隔开。比如import a,b,c可以同时导入“a.py,b.py,c.py”三个文件。
好,学完了import语句,我们接着学习from … import …语句。
2.2 from … import … 语句
from … import …语句可以让你从模块中导入一个指定的部分到当前模块。格式如下:

我们来看一个例子:
# 【文件:test.py】
def hi():
print('函数“hi”已经运行!')
# 【文件:main.py】
from test import hi # 从模块test中导入函数“hi”
hi() # 使用函数“hi”时无需加上“模块.”前缀


当我们需要从模块中同时导入多个指定内容,也可以用逗号隔开,写成from xx模块 import a,b,c的形式。我们再运行一个小案例。


对于from … import …语句要注意的是,没有被写在import后面的内容,将不会被导入。
当我们需要从模块中指定所有内容直接使用时,可以写成【from xx模块 import *】的形式,*代表“模块中所有的变量、函数、类”,我们再运行一个小案例。


不过,一般情况下,我们不要为了图方便直接使用【from xx模块 import *】的形式。
这是因为,模块.xx的调用形式能通过阅读代码一眼看出是在调用模块中的变量/函数/方法,而去掉模块.后代码就不是那么直观了。
到这里我们学完了from … import …语句,再来做一个练习吧。请看以下代码:
# 【文件:story.py】
sentence = '从前有座山,'
def mountain():
print('山里有座庙,')
class Temple:
sentence = '庙里有个老和尚,'
def reading(self):
print('在讲一个长长的故事。')
# 【文件:main.py】
import story
for i in range(10):
print(story.sentence)
story.mountain()
A = story.Temple()
print(A.sentence)
A.reading()
print()
题目要求:在main.py文件导入story模块,将类Temple的属性'庙里有个老和尚,'打印出来。

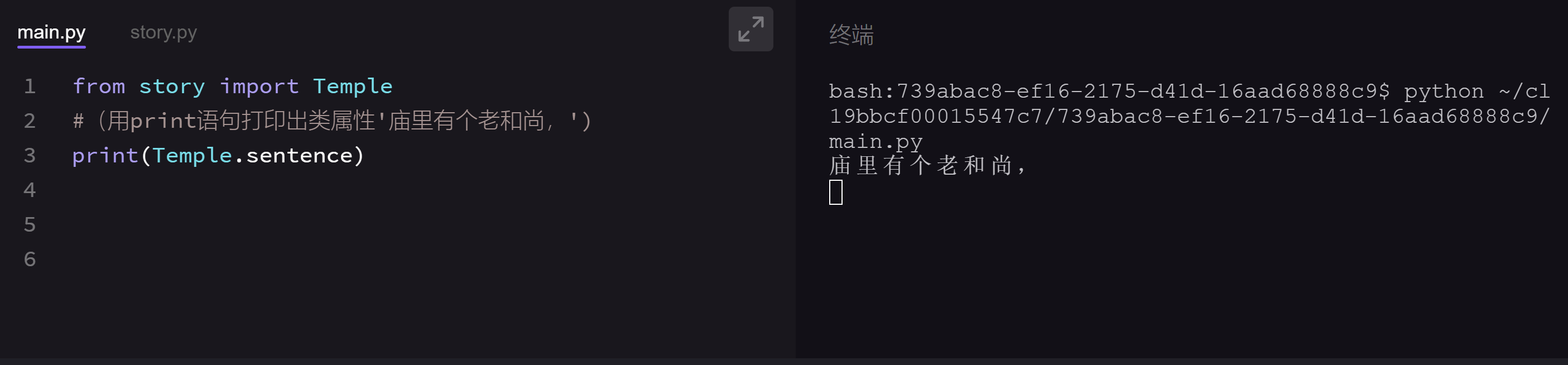
要直接使用Temple类的属性,我们需要在导入的时候指定Temple类(不能直接指定类属性)。老师的答案是这样的:
# 【文件:story.py】
sentence = '从前有座山,'
def mountain():
print('山里有座庙,')
class Temple:
sentence = '庙里有个老和尚,'
def reading(self):
print('在讲一个长长的故事。')
# 【文件:main.py】
from story import Temple
print(Temple.sentence)
学会了import语句和from … import …语句后,你就能愉快地导入模块了。我们接着学习下一个语句。
2.3 if name == 'main'
为了解释什么是【if __name__ == '__main__'】,我先给大家讲解一个概念“程序的入口”。
对于Python和其他许多编程语言来说,程序都要有一个运行入口。
在Python中,当我们在运行某一个py文件,就能启动程序 ——— 这个py文件就是程序的运行入口。
拿我们刚才的课堂练习为例:
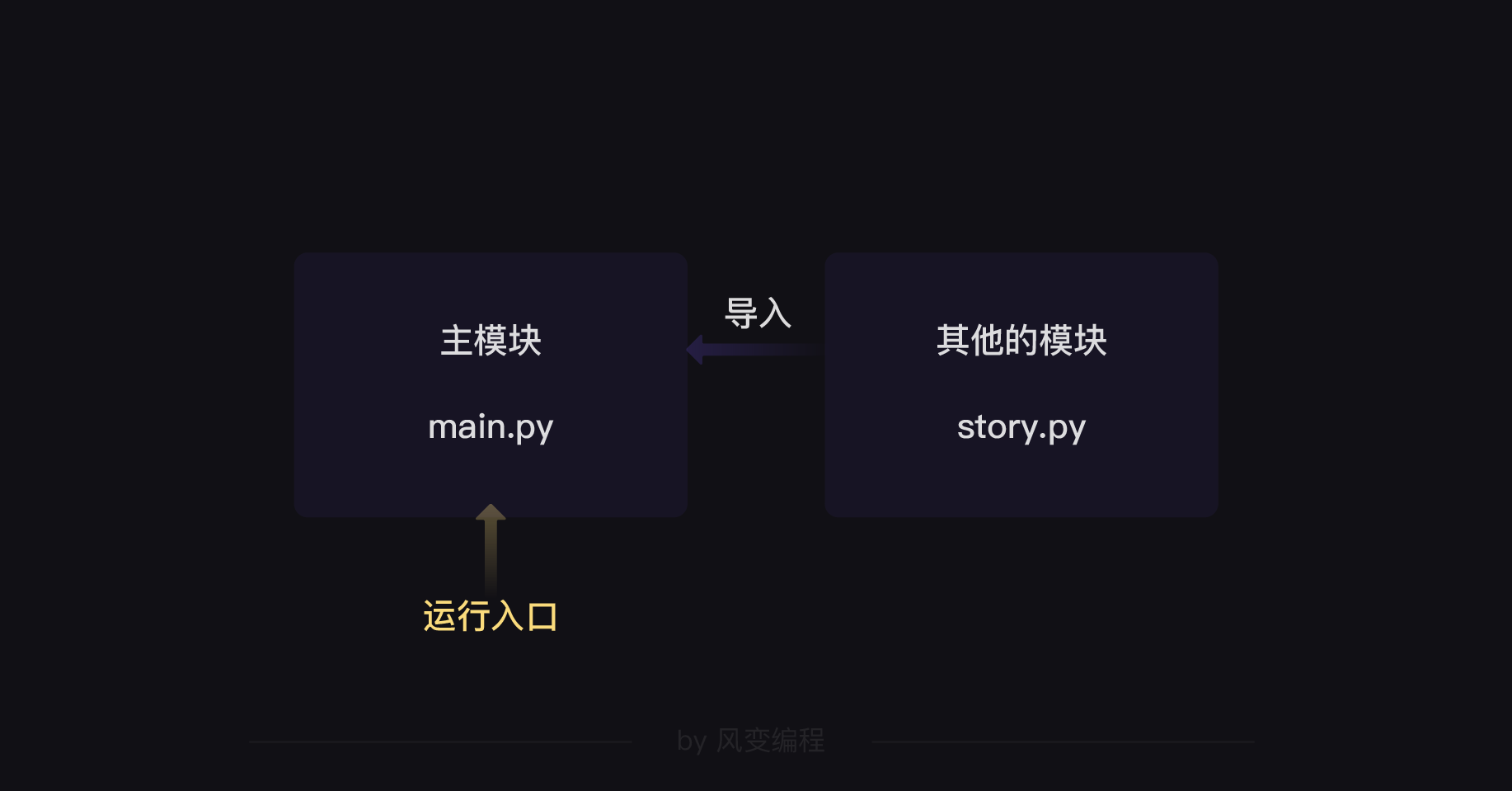
更复杂的情况,我们也可以运行一个主模块,然后层层导入其他模块:
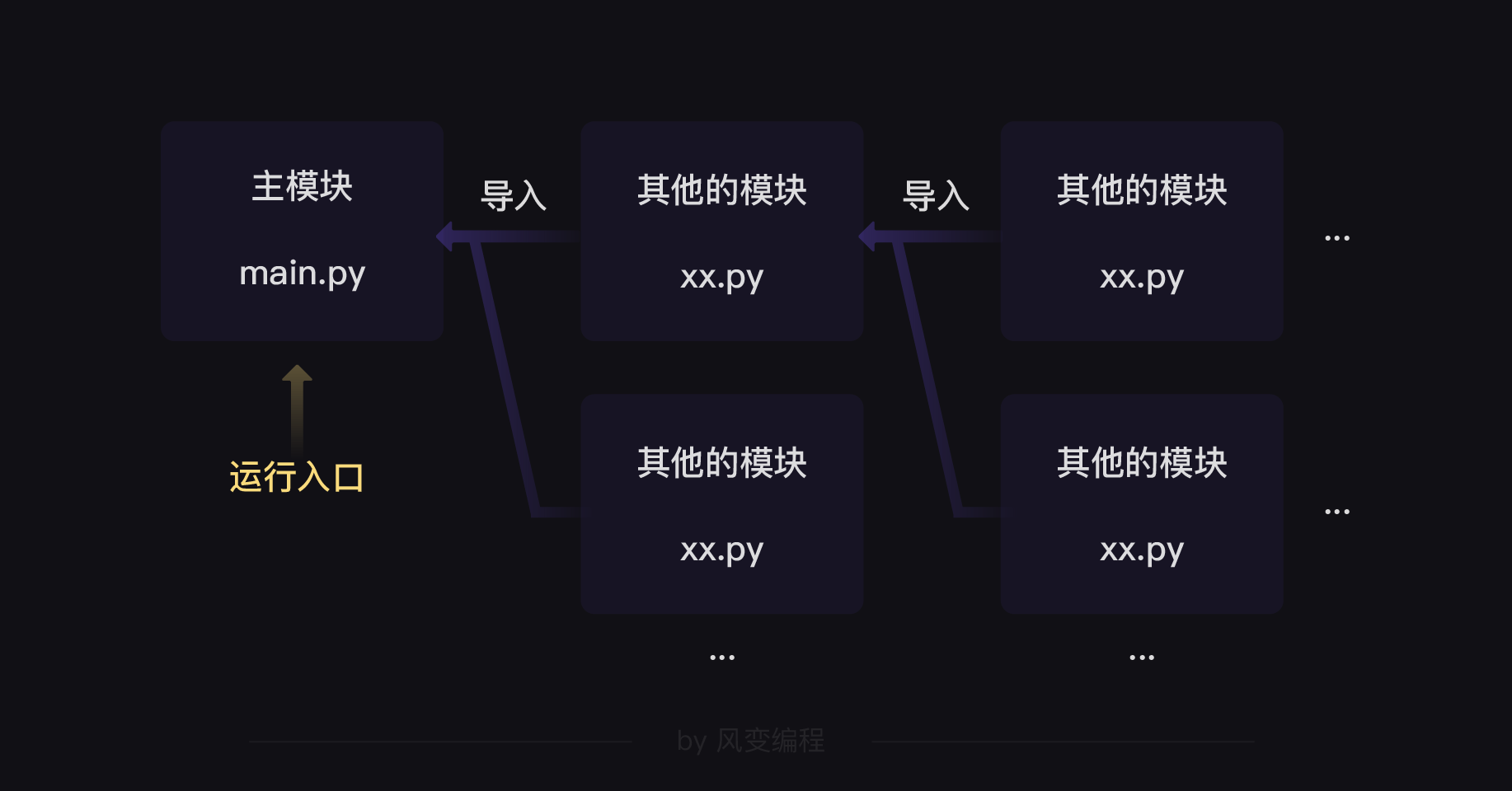
但是,当我们有了一大堆py文件组成一个程序的时候,为了【指明】某个py文件是程序的运行入口,我们可以在该py文件中写出这样的代码:
# 【文件:xx.py】
代码块 ①……
if __name__ == '__main__':
代码块 ②……
这句话的意思是这样的:
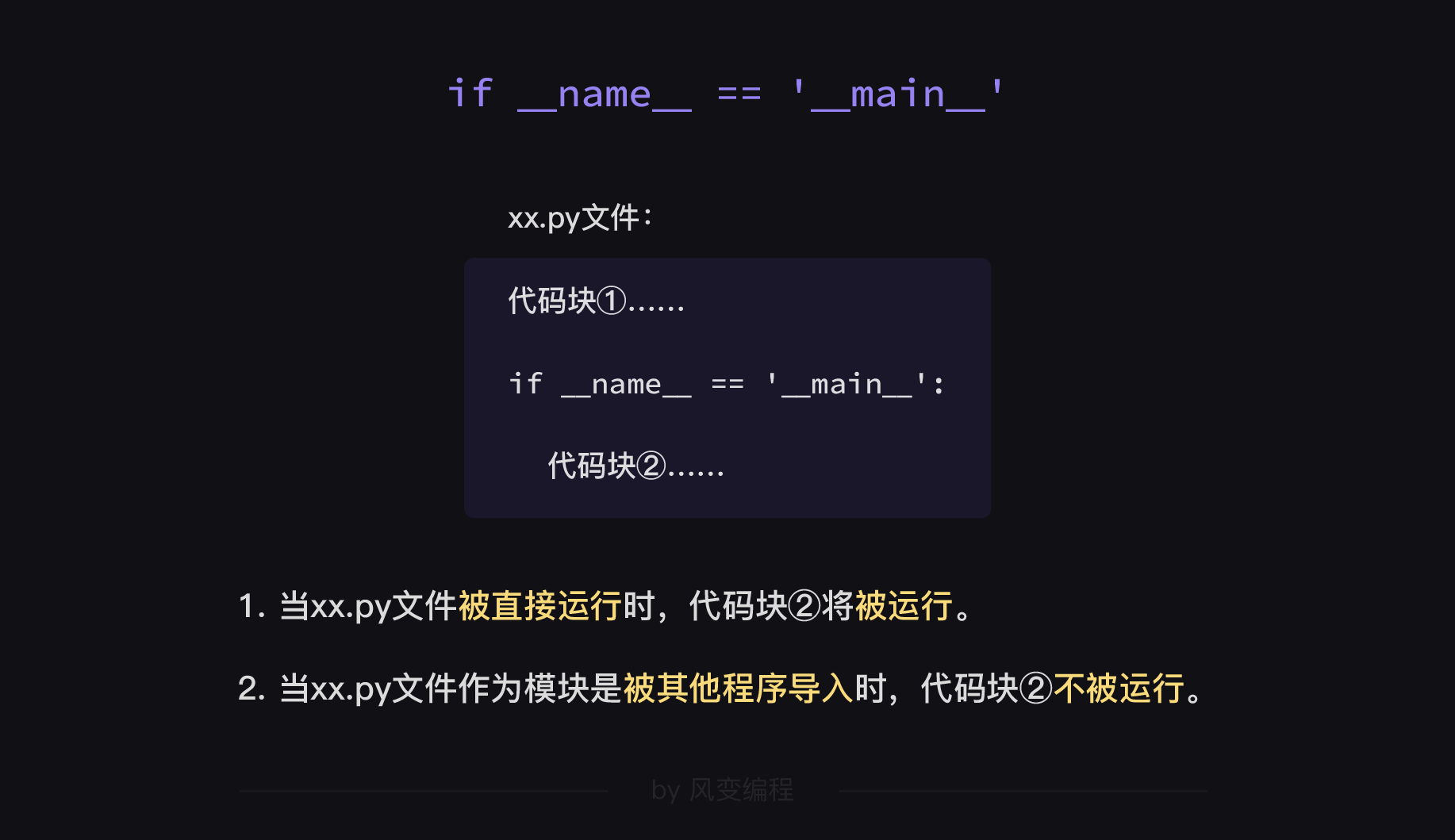
这里的【if __name__ == '__main__'】就相当于是 Python 模拟的程序入口。Python 本身并没有规定这么写,这是一种程序员达成共识的编码习惯。
第一种情况:加上这句话后,程序运行效果不会变化,我们来试试:


我们解释了“当xx.py文件被直接运行时,代码块②将被运行”,再解释一下“xx.py文件作为模块是被其他程序导入时,代码块②不被运行。”
我们来运行体验两段代码。这是第一段:

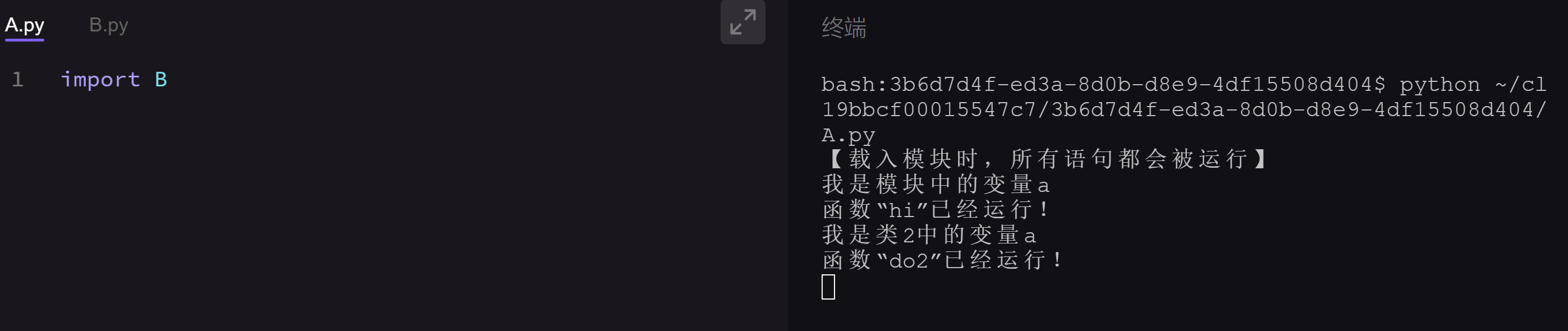
第一段代码没有使用if __name__ == '__main__',所有语句都会被运行。
这是第二段:(如果你运行A.py文件,看到运行结果什么都没有,那就是对的,请点击继续按钮)
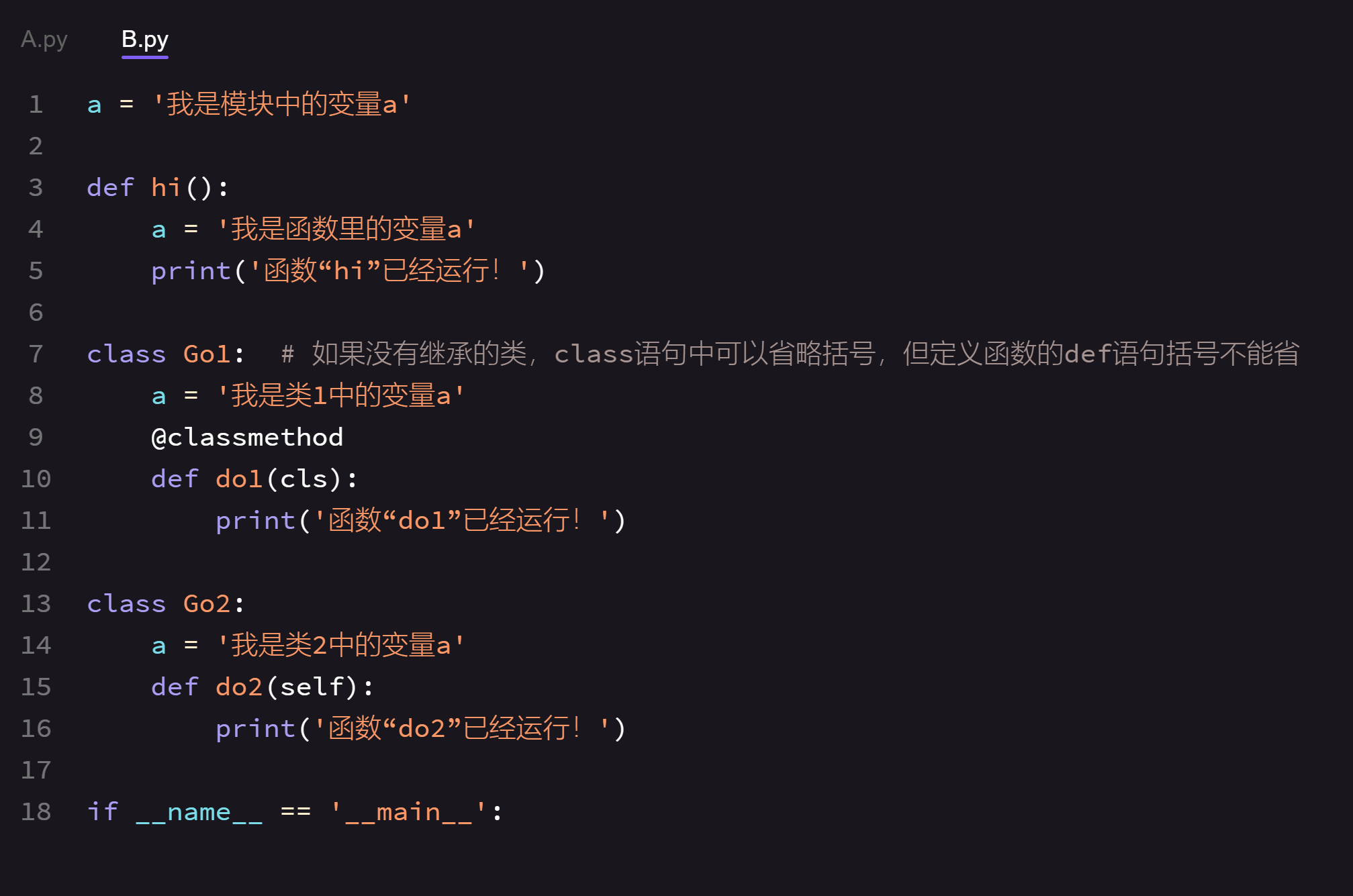
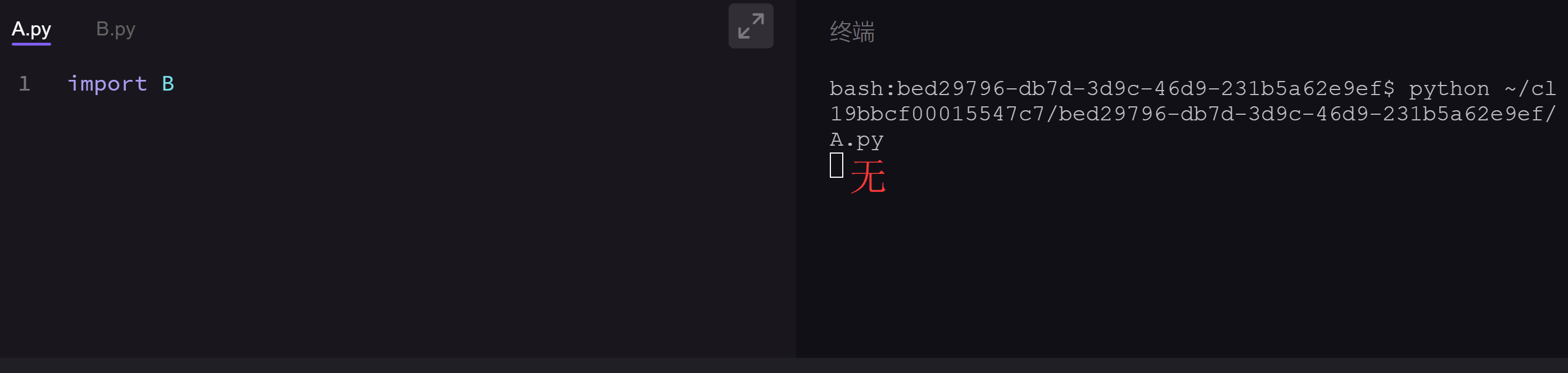
现在我们运行代码的时候,会发现if __name__ == '__main__'下的语句不会被执行。这是因为B.py文件并不是我们现在的程序运行入口,它是被A.py文件导入的。
关于这一个点目前你只需有个印象即可。接下来,我们来看看如何“使用他人的模块”。
3. 使用他人的模块
在之前的项目实操中,我们常常用到这样的语句:
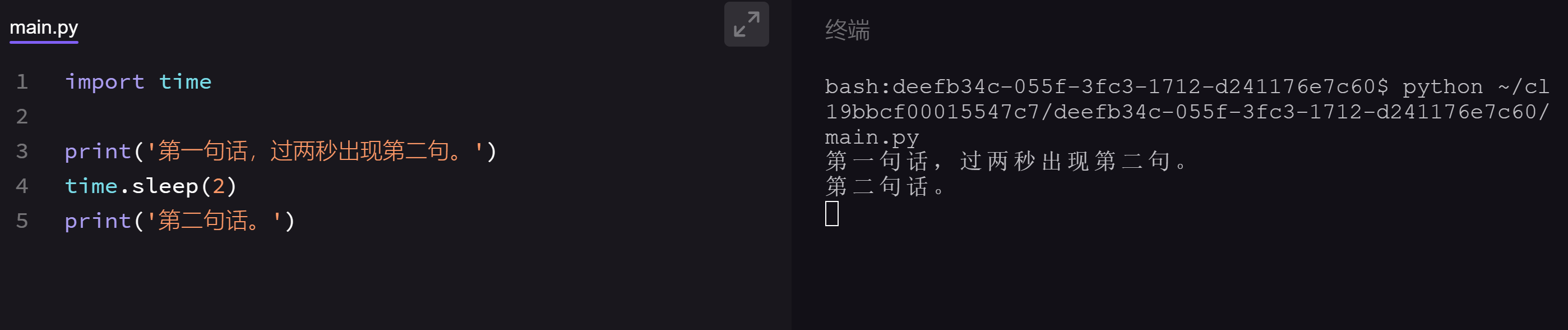
又或者用到这样的功能:
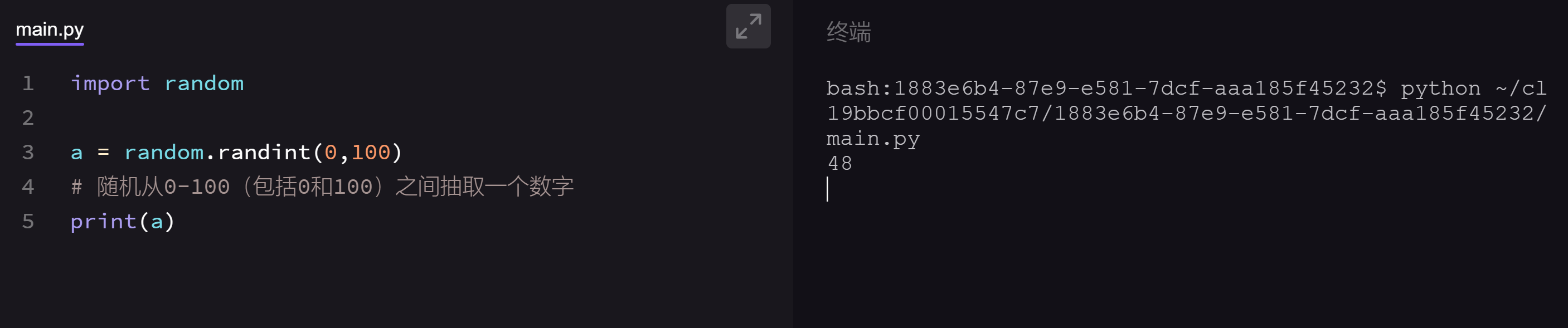
这两个例子中的第一句代码import time和import random其实就是在导入time和random模块。
3.1 初探借用模块
time模块和random模块是Python的系统内置模块,也就是说Python安装后就准备好了这些模块供你使用。
此外,Python作为一门胶水语言,一个强大的优势就是它拥有许多第三方的模块可以直接拿来使用。
如果是第三方编写的模块,我们需要先从Python的资源管理库下载安装相关的模块文件。
下载安装的方式是打开终端,Windows用户输入pip install + 模块名;苹果电脑输入:pip3 install + 模块名,点击enter即可。(需要预装python解释器和pip)
比如说,爬虫时我们会需要用到requests这个库(库是具有相关功能模块的集合),就需要在终端输入pip install requests(Windows用户)的指令。

第三方模块的使用我们会在之后的其他课程具体介绍,今天我们主要来学习Python的内置模块。
如果内置模块是用Python语言编写的话,就能找到py文件:

我们用命令random.__file__找出了random模块的文件路径,就可以去打开查看它的代码:
from warnings import warn as _warn
from types import MethodType as _MethodType, BuiltinMethodType as _BuiltinMethodType
from math import log as _log, exp as _exp, pi as _pi, e as _e, ceil as _ceil
from math import sqrt as _sqrt, acos as _acos, cos as _cos, sin as _sin
from os import urandom as _urandom
from _collections_abc import Set as _Set, Sequence as _Sequence
from hashlib import sha512 as _sha512
import _random
__all__ = ["Random","seed","random","uniform","randint","choice","sample",
"randrange","shuffle","normalvariate","lognormvariate",
"expovariate","vonmisesvariate","gammavariate","triangular",
"gauss","betavariate","paretovariate","weibullvariate",
"getstate","setstate", "getrandbits",
"SystemRandom"]
NV_MAGICCONST = 4 * _exp(-0.5)/_sqrt(2.0)
TWOPI = 2.0*_pi
LOG4 = _log(4.0)
SG_MAGICCONST = 1.0 + _log(4.5)
BPF = 53 # Number of bits in a float
RECIP_BPF = 2**-BPF
class Random(_random.Random):
VERSION = 3 # used by getstate/setstate
def __init__(self, x=None):
self.seed(x)
self.gauss_next = None
def seed(self, a=None, version=2):
if a is None:
try:
# Seed with enough bytes to span the 19937 bit
# state space for the Mersenne Twister
a = int.from_bytes(_urandom(2500), 'big')
except NotImplementedError:
import time
a = int(time.time() * 256) # use fractional seconds
if version == 2:
if isinstance(a, (str, bytes, bytearray)):
if isinstance(a, str):
a = a.encode()
a += _sha512(a).digest()
a = int.from_bytes(a, 'big')
super().seed(a)
self.gauss_next = None
……
……
由于代码太长,我们就不全部展示了。不过可以看到,random模块的源代码是这样的结构:

我们熟悉的函数random.choice(list),功能是从列表中随机抽取一个元素并返回。它的代码被找到了:
def choice(self, seq):
"""Choose a random element from a non-empty sequence."""
try:
i = self._randbelow(len(seq))
except ValueError:
raise IndexError('Cannot choose from an empty sequence')
return seq[i]
另一个熟悉的函数random.randint(a,b),功能是在a到b的范围随机抽取一个整数。它的代码也被找到了:
def randint(self, a, b):
"""Return random integer in range [a, b], including both end points."""
return self.randrange(a, b+1)
像这样,通过阅读源代码我们能找到所有能够使用的变量、函数、类方法。
虽然你可以通过看源代码的方式来理解这个模块的功能。但如果你想要高效地学会使用一个模块,看源代码并不是最佳选项。我们接着谈谈“如何自学模块”。
3.2 如何自学模块
学习模块的核心是搞清楚模块的功能,也就是模块中的函数和类方法有什么作用,以及具体使用案例长什么样。
用自学“random”模块为例,如果英文好的同学,可以直接阅读官方文档:https://docs.python.org/3.6/library/random.html
或者也可以直接百度搜索:
搜到教程后,我们重点关注的是模块中的函数和类方法有什么作用,然后把使用案例做成笔记(还记得第9关谈到的如何做学习笔记么?)。
例如random模块的关键知识(也就是比较有用的函数和类方法),可以做成这样的笔记:
import random # 调用random模块
a = random.random() # 随机从0-1之间(包括0不包括1)抽取一个小数
print(a)
a = random.randint(0,100) # 随机从0-100(包括0和100)之间抽取一个数字
print(a)
a = random.choice('abcdefg') # 随机从字符串,列表等对象中抽取一个元素(可能会重复)
print(a)
a = random.sample('abcdefg', 3) # 随机从字符串,列表等对象中抽取多个不重复的元素
print(a)
items = [1, 2, 3, 4, 5, 6] # “随机洗牌”,比如打乱列表
random.shuffle(items)
print(items)
你来运行一下试试看:

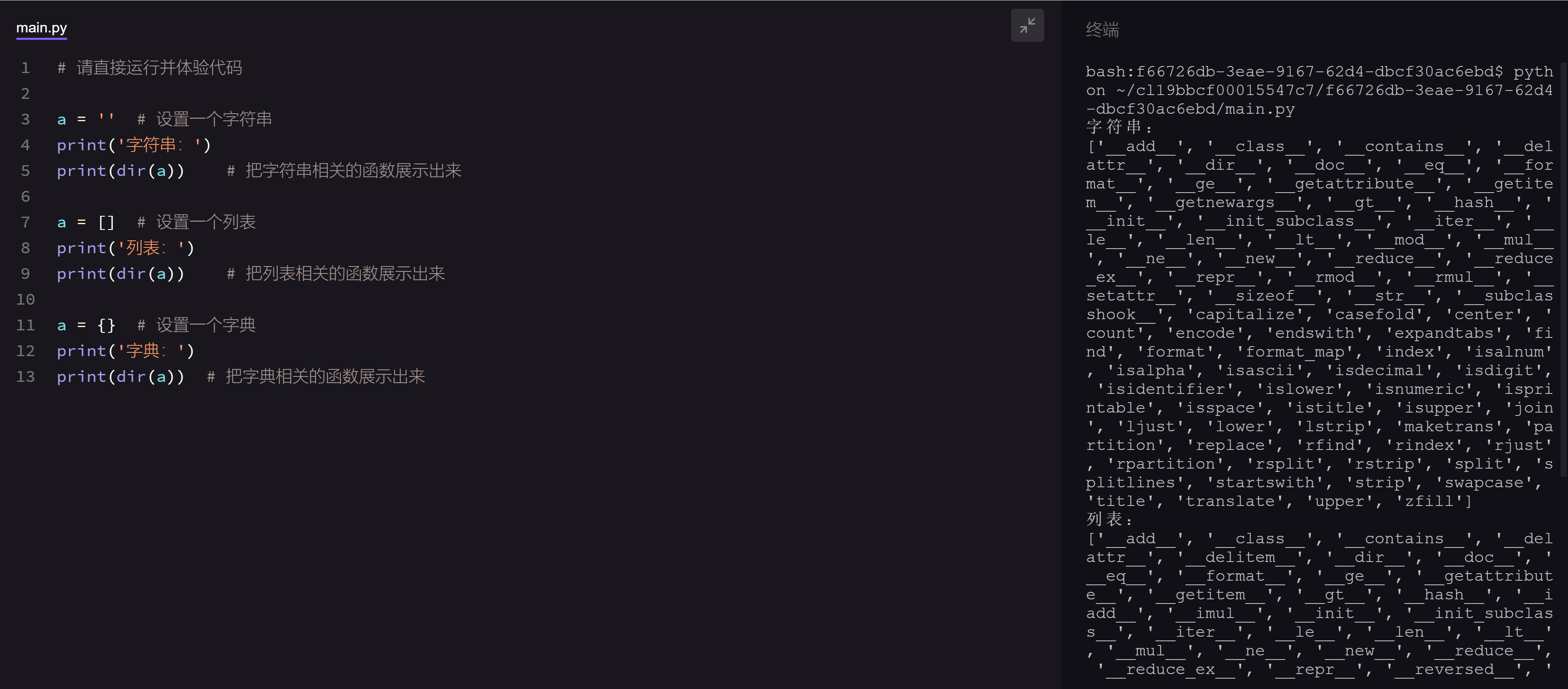
另外,我们还可以使用dir()函数查看一个模块,看看它里面有什么变量、函数、类、类方法。

这就像是查户口一样,可以把模块中的函数(函数和类方法)一览无余地暴露出来。对于查到的结果"__xx__"结构的(如__doc__),它们是系统相关的函数,我们不用理会,直接看全英文的函数名即可。
这样查询的好处是便于我们继续搜索完成自学。比如我们在列表中看到一个单词“seed”,我们就可以搜一搜random.seed的用法:
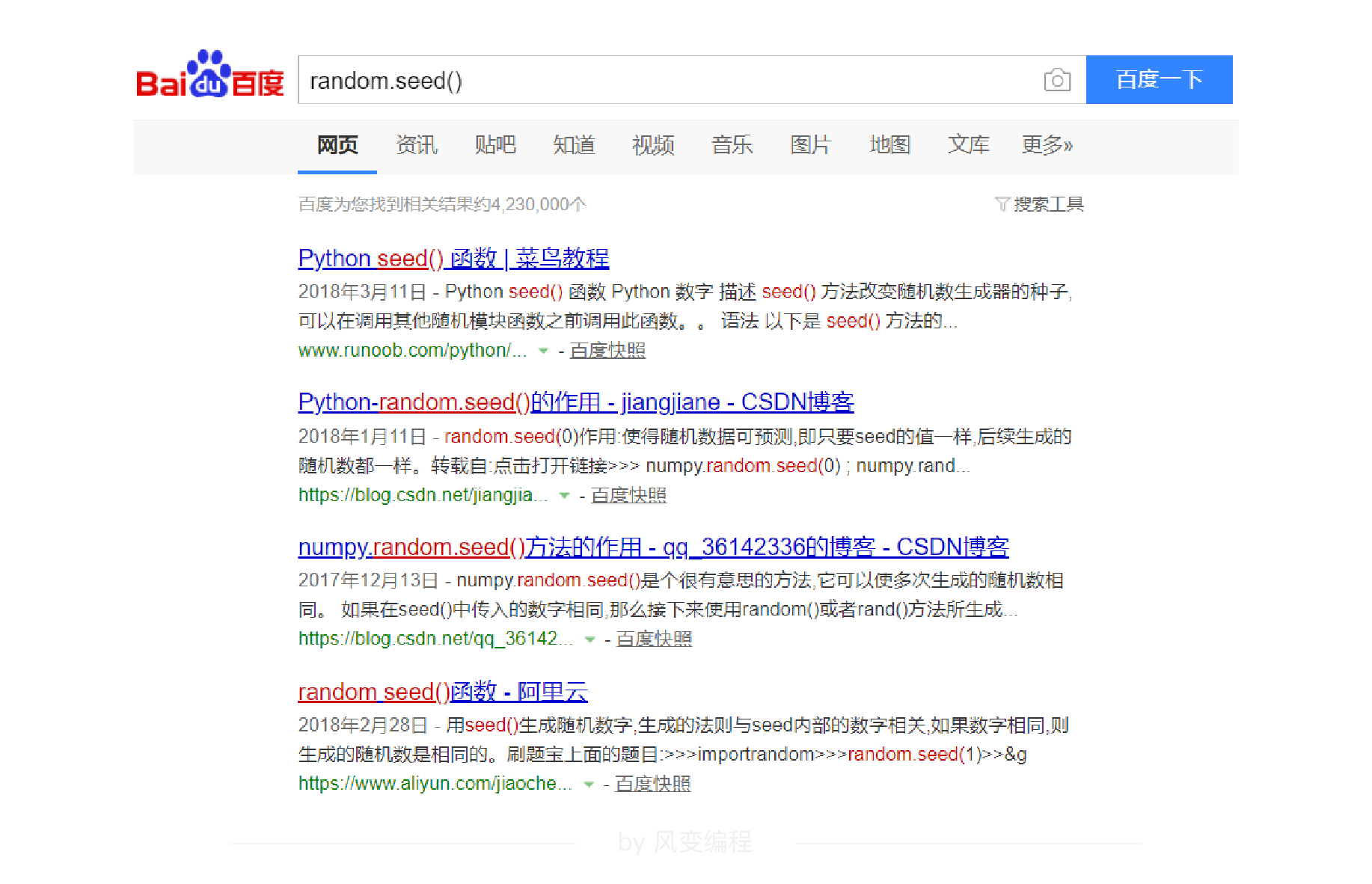
甚至不是模块,我们也可以用这种方式自学:dir(x),可以查询到x相关的函数,x可以是模块,也可以是任意一种对象。
好,我们回到模块上。再次总结一下模块的学习方法,其实可以归纳成三个问题:

这里想提醒大家的是,比较小的模块(比如random模块)可以通过这样的方式自学,大型模块的学习就比较困难(除非你有充足的专业背景知识)。
例如数据分析需要用到pandas和NumPy模块,网页开发要用到Django模块等等,这些大型模块最好还是在课程上系统学习,避免散乱的学习形不成知识体系。
以目前大家的水平来说,有一些很实用,又不难学的模块,已经足够我们探索了。在今天的最后,我想手把手带大家自学一个模块。
3.3 学习csv模块
今天想带大家学习的模块是csv模块。之所以教大家这个模块,是因为这个模块既简单又实用。
csv是一种文件格式,你可以把它理解成“简易版excel”。学会了csv模块,你就可以用程序处理简单的电子表格了。
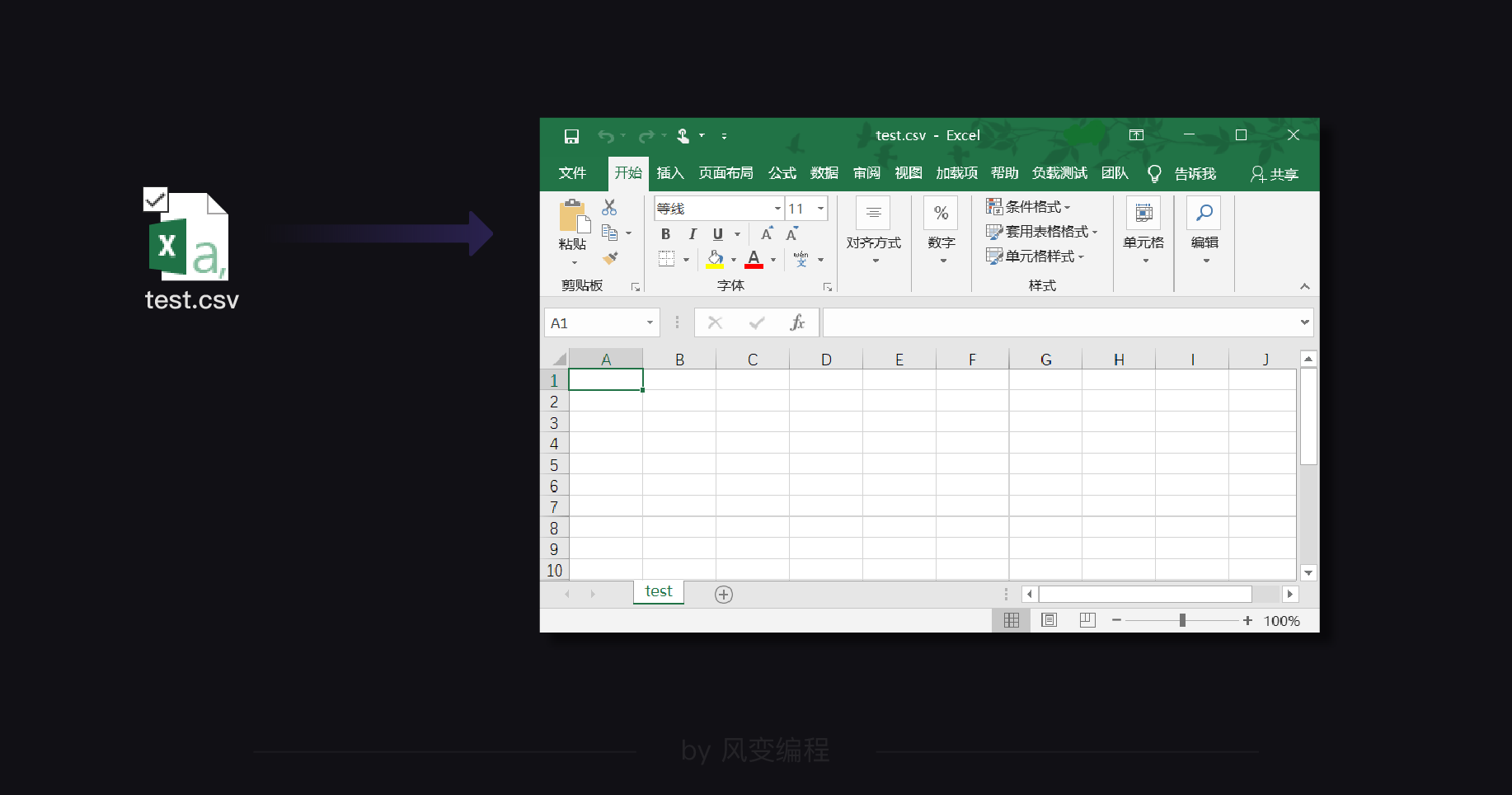
如果要手动新建csv文件,我们可以先新建一个excel表格,然后选择另存为“csv”格式即可。
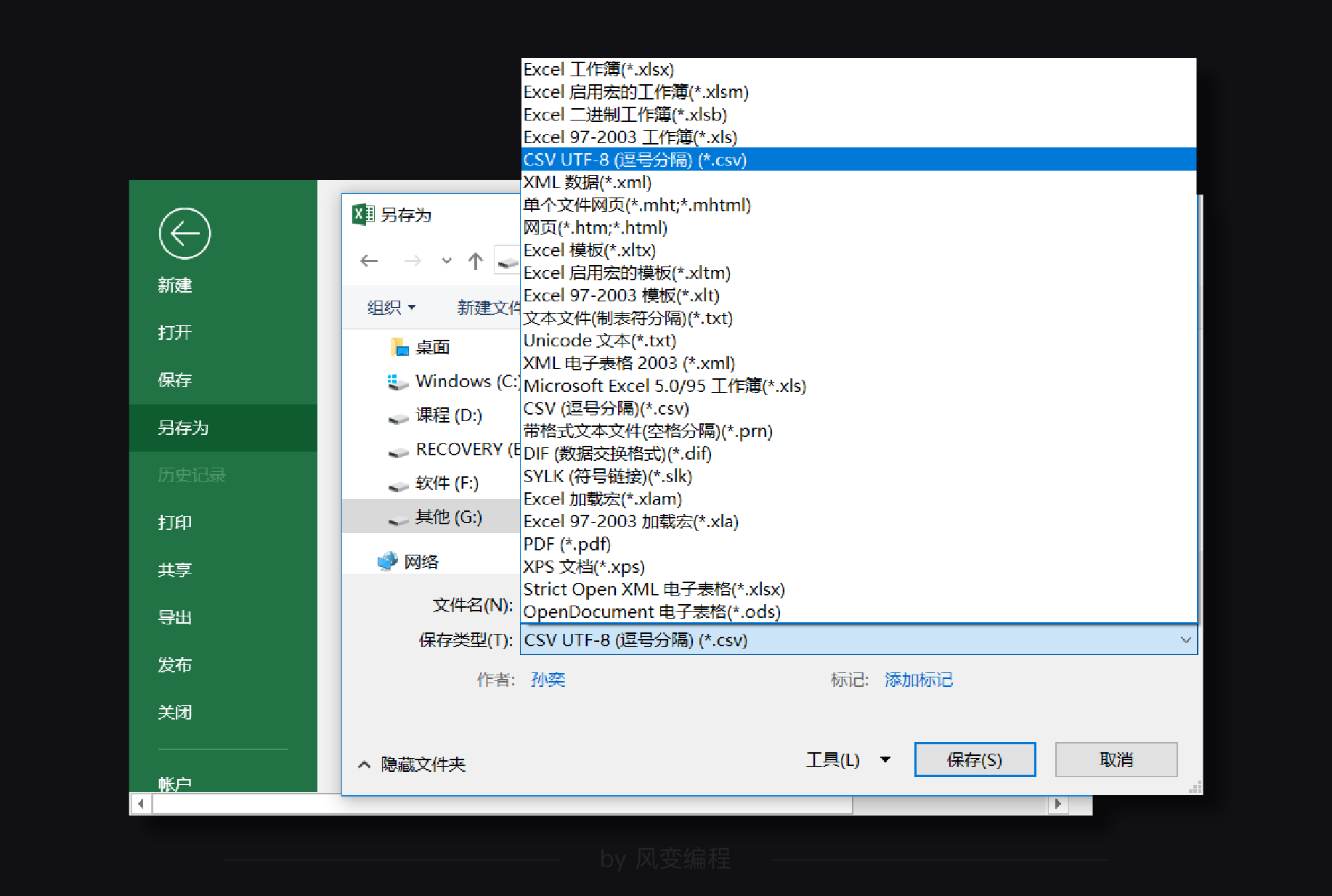
同样的,当我们有了一张csv格式的表格,我们也可以选择另存为“excel”格式。
对csv文件的介绍就到这里。下面继续学习如何用csv模块读写csv文件。
我们使用import语句导入csv模块,然后用dir()函数看看它里面有什么东西:
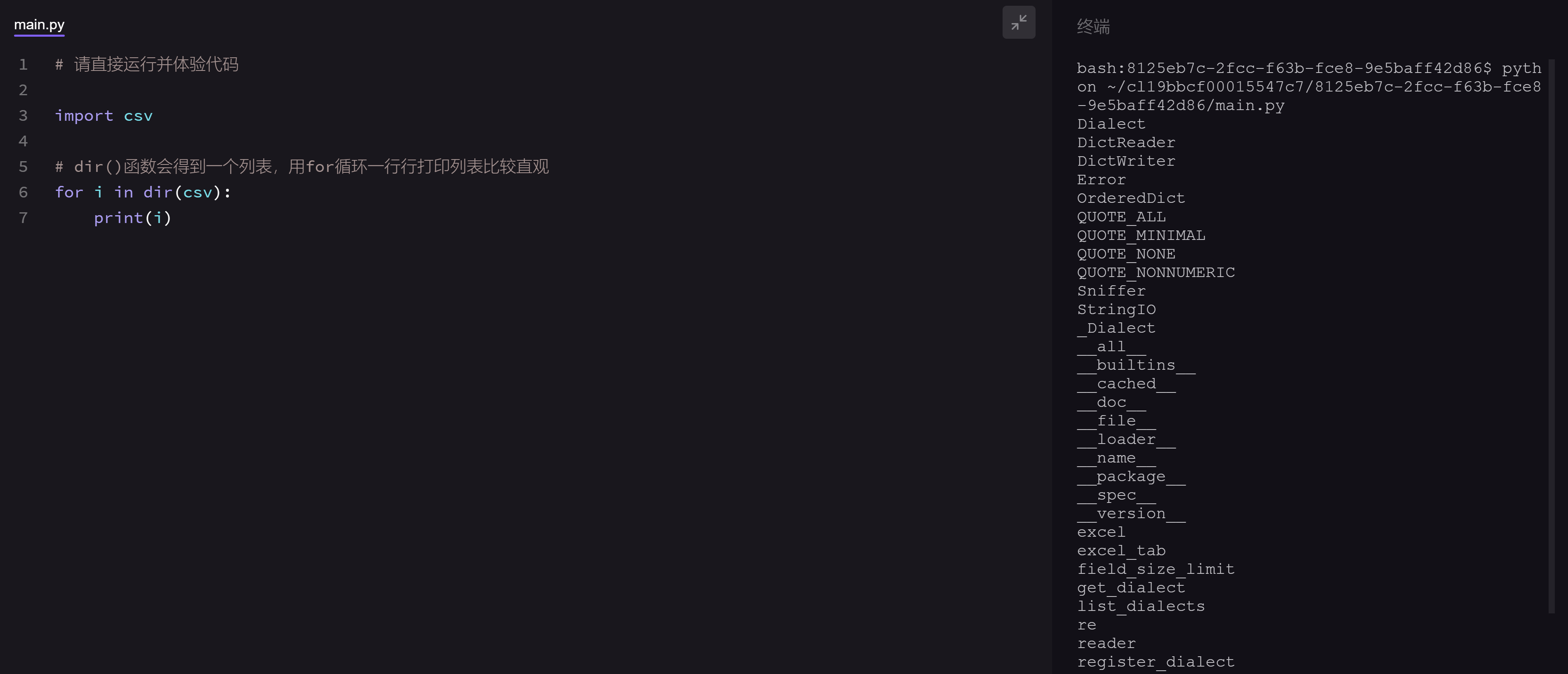
同时,我们可以搜索到csv模块的官方英文教程: https://docs.python.org/3.6/library/csv.html
中文教程:https://yiyibooks.cn/xx/python_352/library/csv.html#module-csv
如果你要通过阅读这份教程来学习csv模块的话,最简单的方式是先看案例(拉到教程的最后),遇到看不懂的函数,再倒回来查具体使用细节。

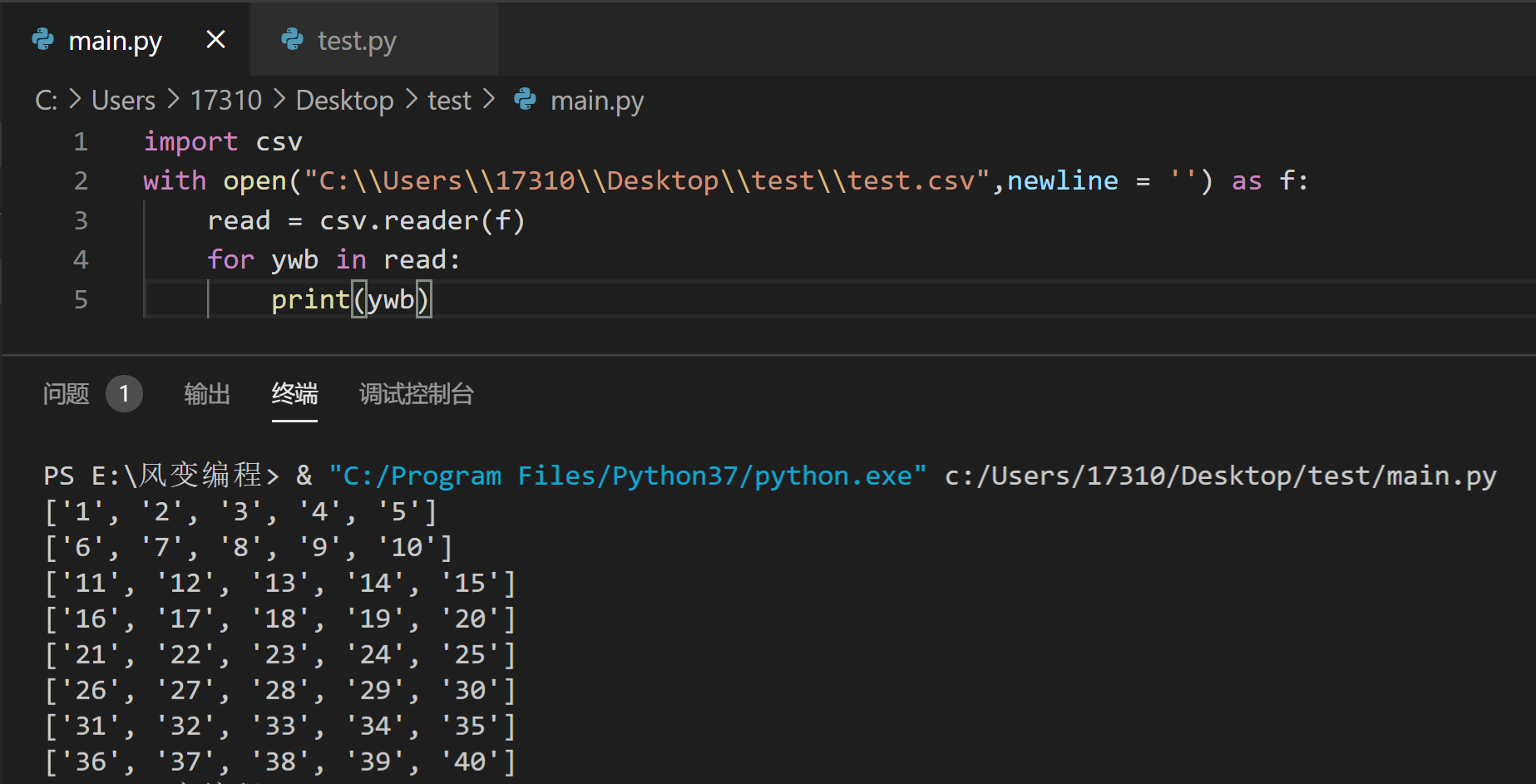
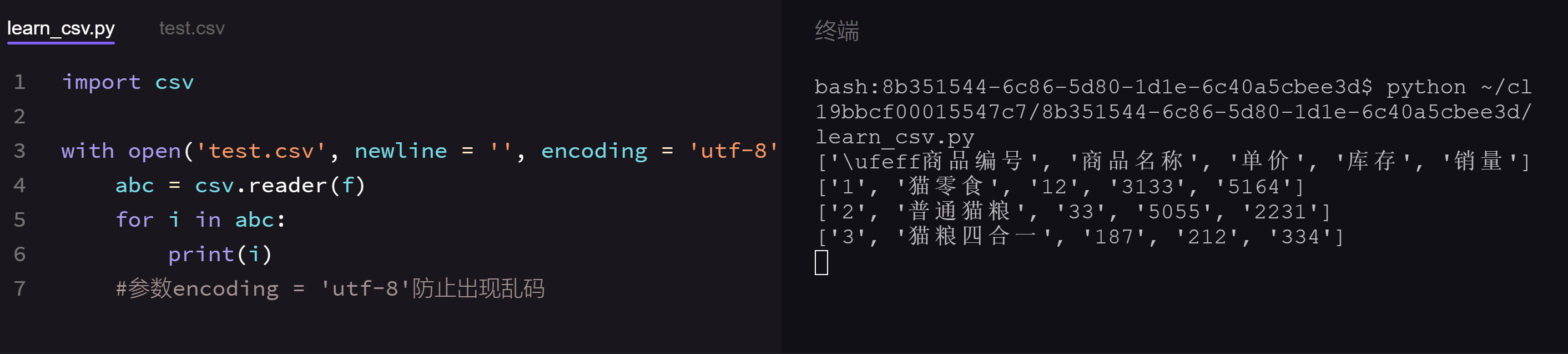
现在我们也跟着案例动手试试如何读取csv文件,可见open()后面跟了两个参数,用csv.reader(文件变量)创建一个reader对象。
我们新建了一个名为test.csv的文件,里面的内容是这样:
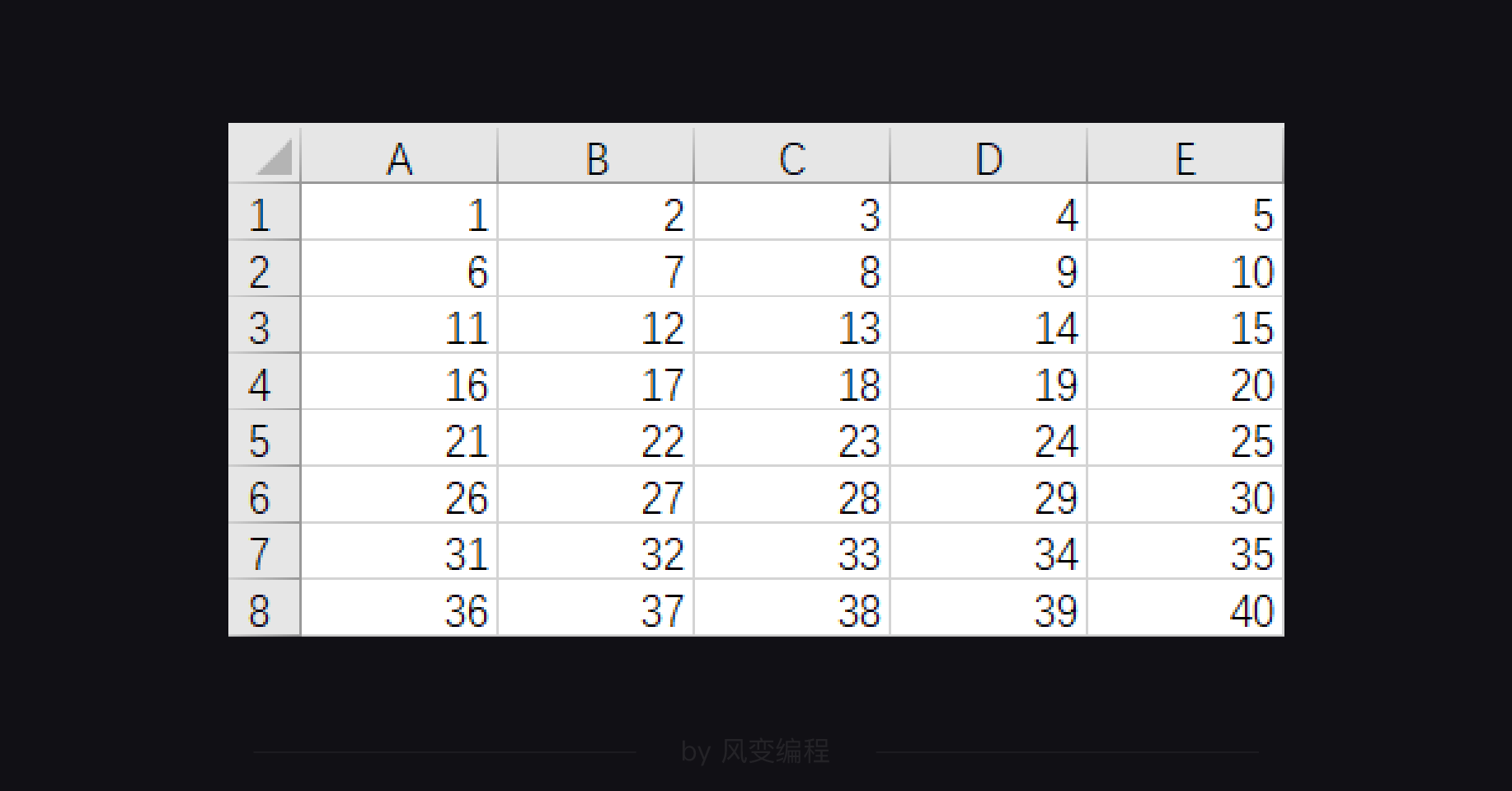
然后我们运行learn_csv.py文件的几行代码,你就能print出csv文件中的每一行信息。
import csv
with open("C:\\Users\\17310\\Desktop\\test\\test.csv",newline = '') as f:
read = csv.reader(f)
for ywb in read:
print(ywb)
我们可以看到,终端输出的每一行信息都是一个列表。
我们来做一个练习,下面有一个csv文件:
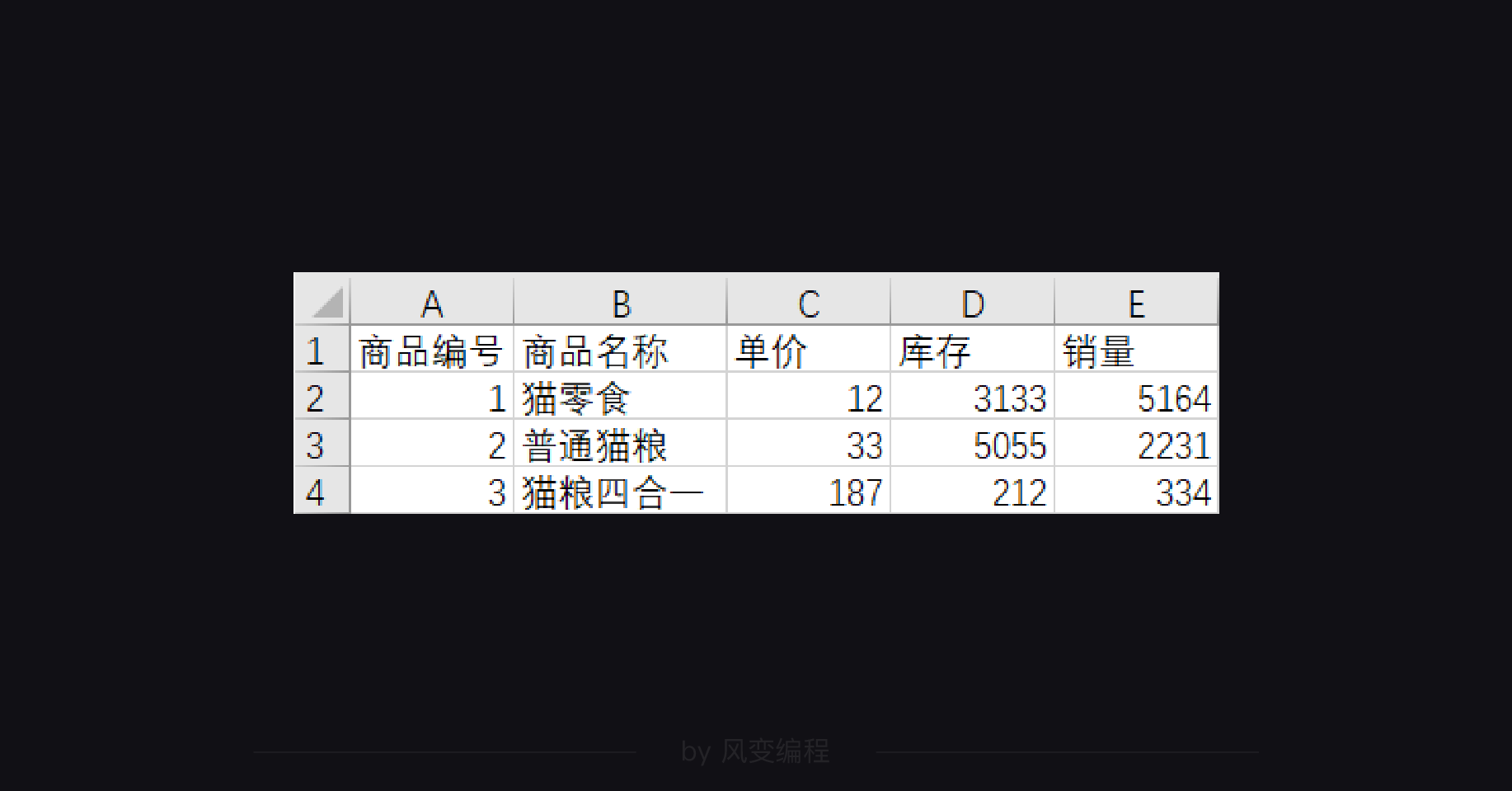
你来试试把它的每一行打印出来吧:
以上就是读取csv文件的写法,接下来我们来看如何往csv格式文件写入数据。
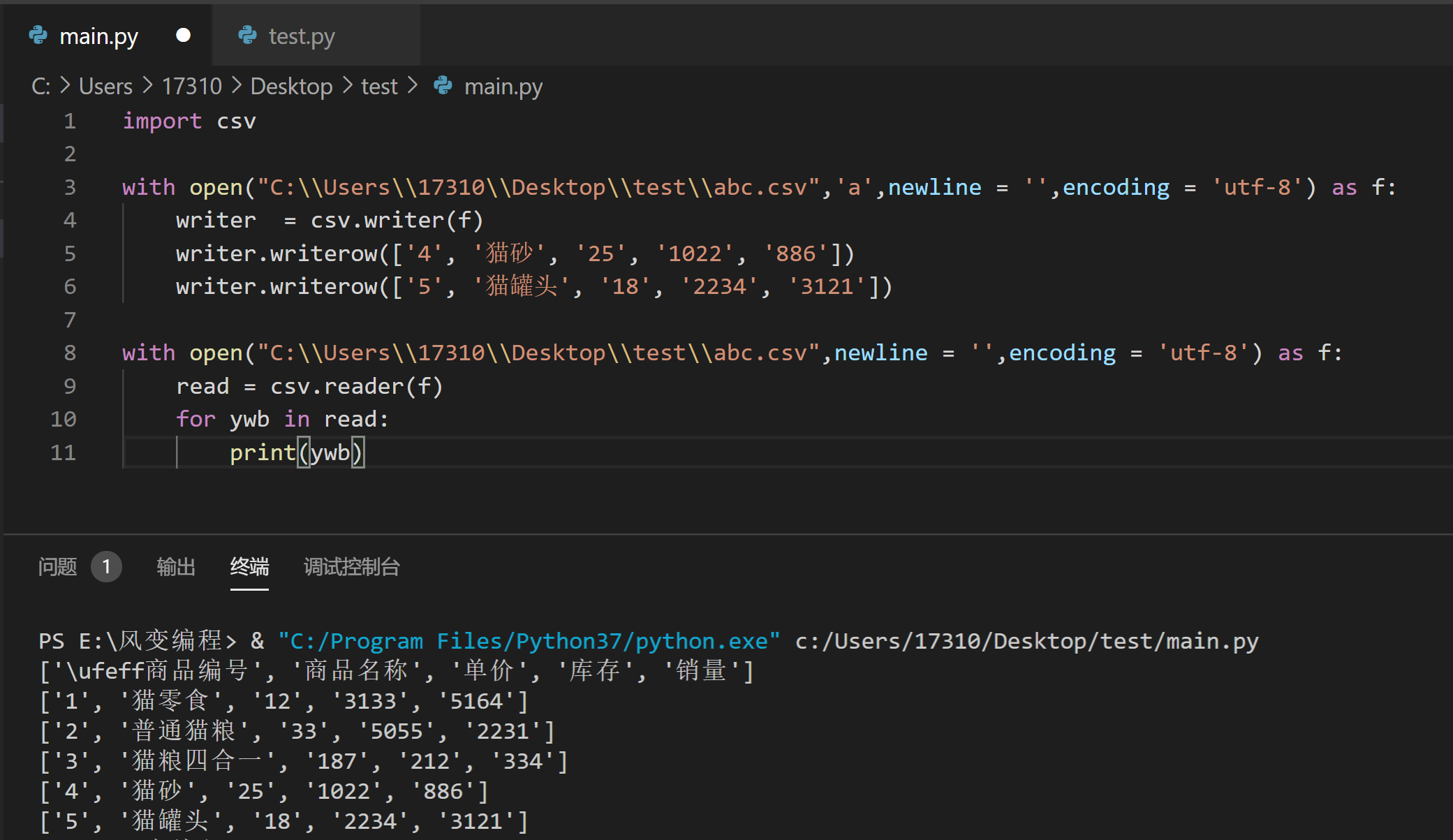
写入数据的方式是这样的:

先创建一个变量名为writer(也可以是其他名字)的实例,创建方式是writer = csv.writer(x),然后使用writer.writerow(列表)就可以给csv文件写入一行列表中的内容。
另外关于open函数的参数,也就是图中的'a',我们来复习一下:

我们来做一个练习,还是这个商品列表的csv文件:
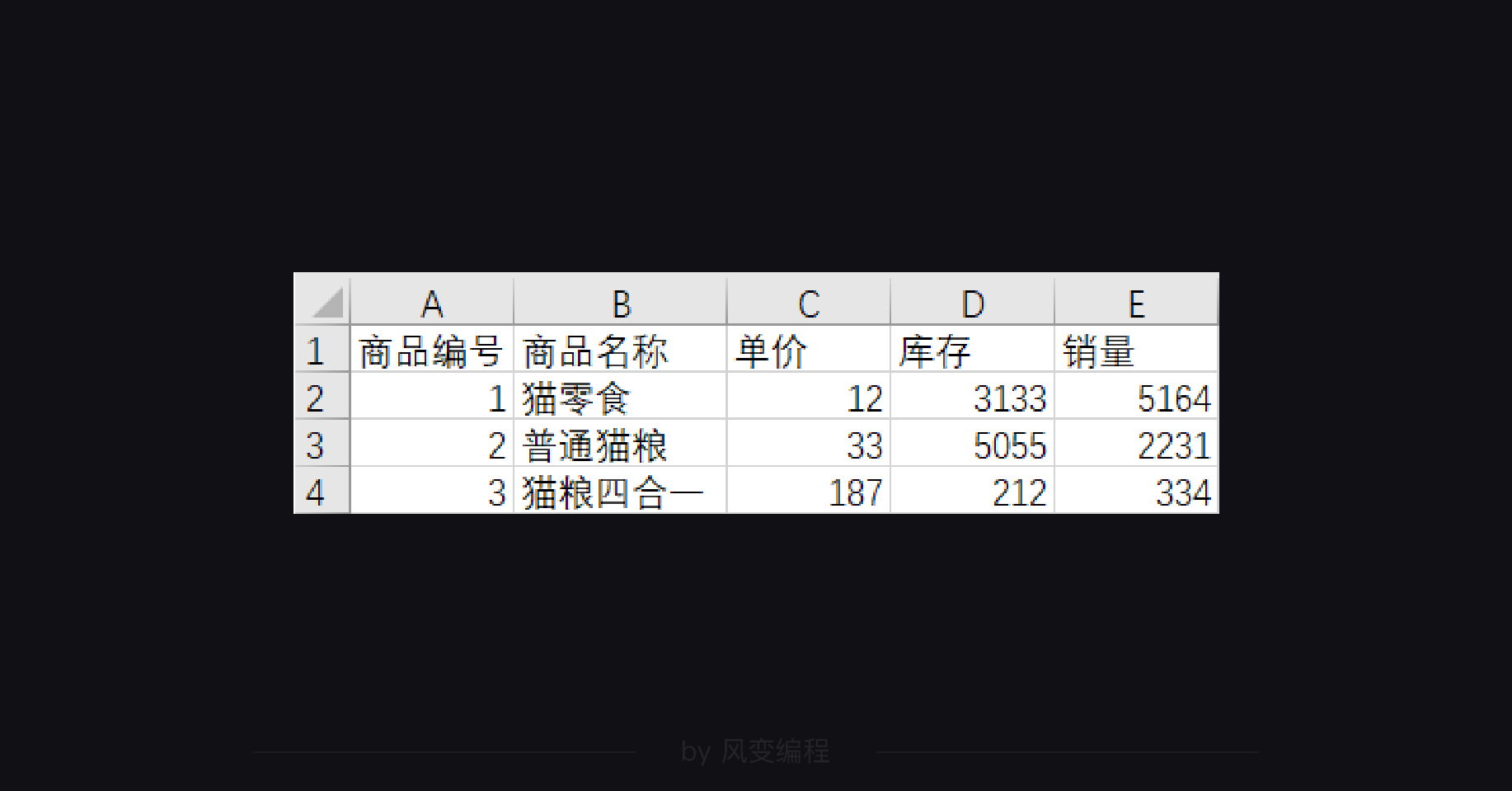
你来试试用writerow()方法为它追加写入两行列表吧:['4', '猫砂', '25', '1022', '886']、['5', '猫罐头', '18', '2234', '3121']。
#插入语句
import csv
with open("C:\\Users\\17310\\Desktop\\test\\abc.csv",'a',newline = '',encoding = 'utf-8') as f:
writer = csv.writer(f)
writer.writerow(['4', '猫砂', '25', '1022', '886'])
writer.writerow(['5', '猫罐头', '18', '2234', '3121'])
到这里,最基本的csv表格读取和录入方法我们就已经学会了。csv模块虽然比random模块稍微复杂一点点,但按照模块三问(这模块有哪些函数可用?有哪些属性或方法可用?使用格式是什么?)的学习方式,我们一样可以学会它的基本用法。
这里先卖一个关子。后面的两个实操项目,我们会展示如何应用csv模块的相关知识。
最后,对今天的知识做个总结:


4. 习题练习
4.1 习题一
1.练习介绍
我们会通过今天的作业,了解Python的一个内置模块“time模块”的更多用法。
2.练习要求
在课堂上,我们见过了同样是内置模块的“csv模块”在数据处理方面的强大之处。
而这个练习,我们会和我们的老朋友“time模块”打交道,了解它的更多用法。
下面会先看一个没用模块的“时间记录器”,再借两个网址的知识,对其升级。
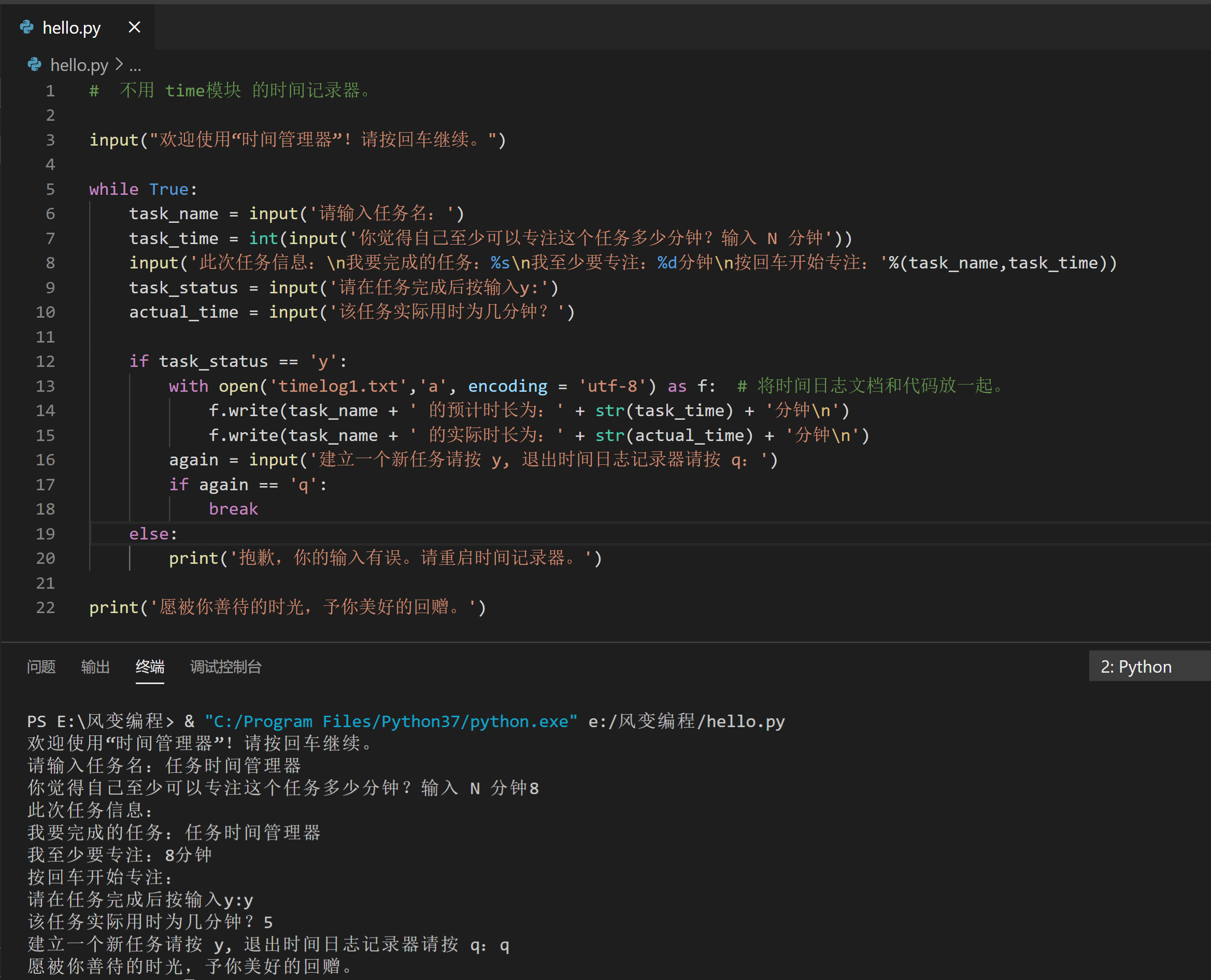
3.一个没用模块的“时间记录器”
请运行下侧的代码,并读懂代码中的每一行。
涉及知识:判断、循环、文件读写等。
注:新建文件,在“步骤”旁的“文件”里查看。
# 不用 time模块 的时间记录器。
input("欢迎使用“时间管理器”!请按回车继续。")
while True:
task_name = input('请输入任务名:')
task_time = int(input('你觉得自己至少可以专注这个任务多少分钟?输入 N 分钟'))
input('此次任务信息:\n我要完成的任务:%s\n我至少要专注:%d分钟\n按回车开始专注:'%(task_name,task_time))
task_status = input('请在任务完成后按输入y:')
actual_time = input('该任务实际用时为几分钟?')
if task_status == 'y':
with open('C:\\Users\\17310\\Desktop\\test\\timelog1.txt','a', encoding = 'utf-8') as f: # 将时间日志文档和代码放一起。
f.write(task_name + ' 的预计时长为:' + str(task_time) + '分钟\n')
f.write(task_name + ' 的实际时长为:' + str(actual_time) + '分钟\n')
again = input('建立一个新任务请按 y, 退出时间日志记录器请按 q:')
if again == 'q':
break
else:
print('抱歉,你的输入有误。请重启时间记录器。')
print('愿被你善待的时光,予你美好的回赠。')
4.为“时间记录器”加上time模块
只要我们想通过编程做到更多的事,就避不开主动了解更多知识。
所以,这次的练习,想将主动权更多地交在大家手里。
请你通过搜索和自学,了解并运用下面两个新知识:
time模块中的时间戳(可进行日期运算)和格式化日期(可将日期转换成平常我们所见的格式);
倒计时的功能怎么用print()函数实现,属于之前没有讲过的方法,需要去搜索新的知识。
假设你对自己的搜索能力有信心,想尽快完成这个练习,可点开下面两个链接:
http://www.runoob.com/python/python-date-time.html
https://jingyan.baidu.com/article/48a420571dfd70a925250410.html
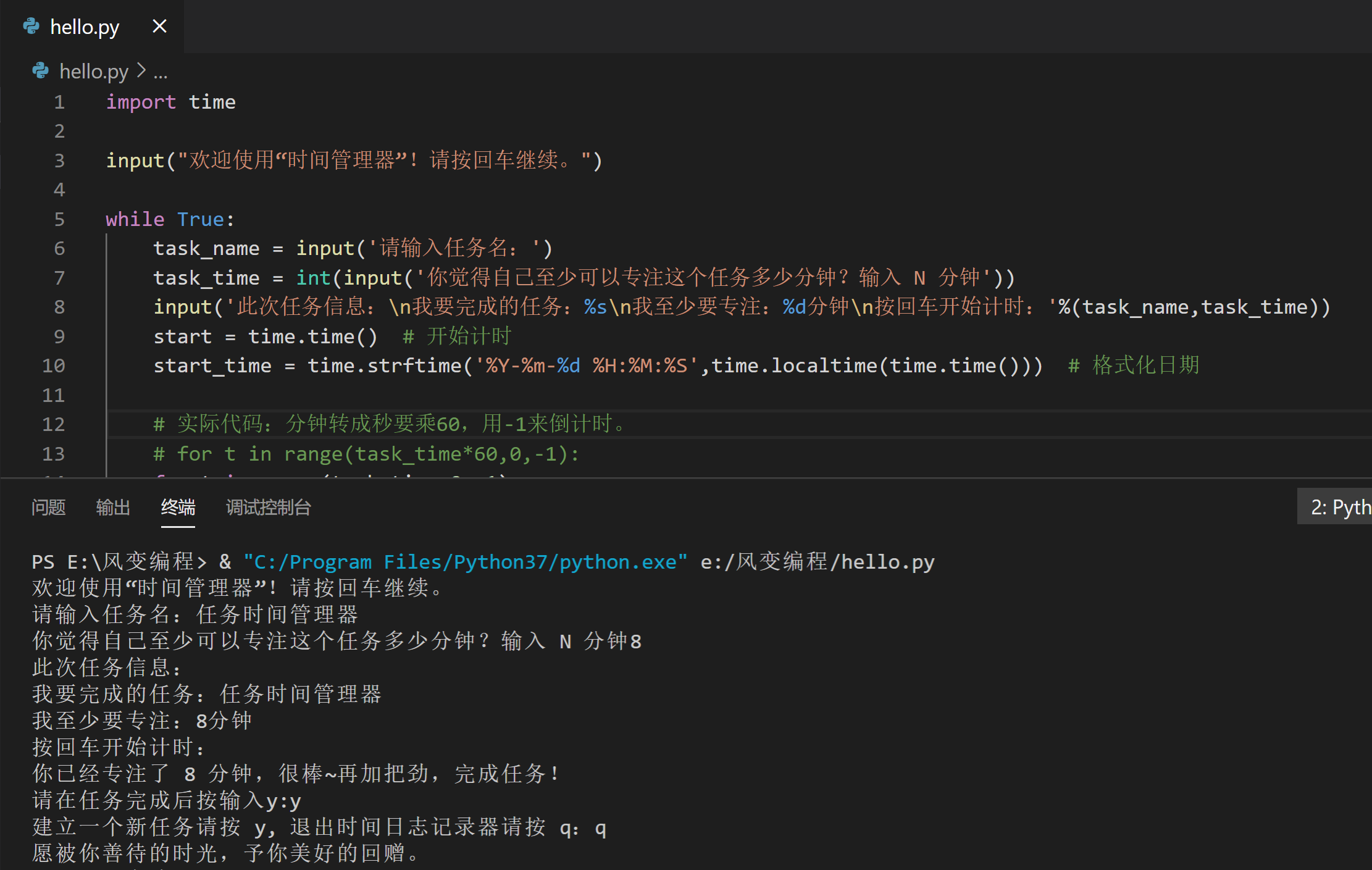
import time
input("欢迎使用“时间管理器”!请按回车继续。")
while True:
task_name = input('请输入任务名:')
task_time = int(input('你觉得自己至少可以专注这个任务多少分钟?输入 N 分钟'))
input('此次任务信息:\n我要完成的任务:%s\n我至少要专注:%d分钟\n按回车开始计时:'%(task_name,task_time))
start = time.time() # 开始计时
start_time = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())) # 格式化日期
# 实际代码:分钟转成秒要乘60,用-1来倒计时。
# for t in range(task_time*60,0,-1):
for t in range(task_time,0,-1):
info = '请专注任务,还要保持专注 ' + str(t) + ' 秒哦!'
print(info,end="")
print("\b"*(len(info)*2),end="",flush=True)
time.sleep(1)
print('你已经专注了 %d 分钟,很棒~再加把劲,完成任务!'%task_time) # 倒计时后,才继续运行之后的代码。
# 询问任务是否完成
task_status = input('请在任务完成后按输入y:')
if task_status == 'y':
end = time.time() # 一定用户按了 y,就记下结束时间。
end_time = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())) # 日期格式化
actual_time = int((end -start)/60) # 始末时间相减,从秒换算到分,除以60。
start_end = start_time + '——' + end_time + '\n'
with open('C:\\Users\\17310\\Desktop\\test\\timelog3.txt','a', encoding = 'utf-8') as f:
f.write(task_name + ' 的预计时长为:' + str(task_time) + '分钟\n')
f.write(task_name + ' 的实际时长为:' + str(actual_time) + '分钟,具体时间为:' + start_end)
again = input('建立一个新任务请按 y, 退出时间日志记录器请按 q:')
if again == 'q':
break
else:
print('抱歉,你的输入有误。请重启时间记录器。')
print('愿被你善待的时光,予你美好的回赠。')
4.2 习题二
1.练习介绍
通过这个练习,我们会用模块去实现上一关卡的选做题“古诗默写”。
2.练习要求
这个练习,我们会接触一个新的Python内置模块:os(文件/目录方法)。
这个模块中的许多方法,配合文件读写以及数据处理,可以让一些工作得以自动化。
当然,在一个练习里,我们不会奢求那么多,先体验一下os模块里的3个方法即可。
3.代码回顾
我们先回顾一下不用模块是如何出古诗默写题的:
list_test = ['一弦一柱思华年。\n','只是当时已惘然。\n']
with open ('poem1.txt','r') as f:
lines = f.readlines()
with open('poem1.txt','w') as new:
for line in lines:
if line in list_test:
new.write('____________。\n')
else:
new.write(line)
4.os 模块中的替换方法
可能你会觉得这么操作更麻烦,但假设要你处理大量的文档,模块会让你的代码更清晰更简洁。
import os
list_test = ['一弦一柱思华年。\n','只是当时已惘然。\n']
with open ('poem3.txt','r') as f:
lines = f.readlines()
with open('poem_new.txt','w') as new:
for line in lines:
if line in list_test:
new.write('____________。\n')
else:
new.write(line)
os.replace('poem_new.txt', 'poem3.txt')