一.数据库设计
根据业务需要,结合选用的数据库,设计出最有的数据存储模型并建立好表结构及表与表之间的关系使之有效的存储和高效的访问。 在系统设计开始对数据库进行良好的设计,这样才能保证以后对业务发展的需要进行改进,保证系统的稳定性。
一个好的数据库设计应该能满足:
1.高效的访问。
2.数据冗余少。
3.节约存储空间。
4.可维护性强,扩展性好。
因此,在设计方面应该:
1.尽量遵循数据库三大范式(不一定要遵循,根据需求分析)
第一范式:1NF是对属性的原子性约束,要求属性(列)具有原子性,不可再分解;(只要是关系型数据库都满足1NF)
第二范式:2NF是对记录的惟一性约束,表中的记录是唯一的,就满足2NF, 通常我们设计一个主键来实现,主键不能包含业务逻辑。
第三范式:3NF是对字段冗余性的约束,它要求字段没有冗余。 没有冗余的数据库设计可以做到。
(但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。)
2.充分考虑扩展性和维护性
3.深入分析数据库的效率(控制好时间和空间两者的关系)
......
二.数据库分表分库
1.分库:
例如一个庞大的项目,需要将其拆分为很多个小的项目,而每一个小的项目有自己单独数据库。
2.分表:
水平分割:
若数据库单表中,数据条数过多会导致效率低下,因此可以将表水平分割成多个表。
(注意:水平分割会导致查询受到限制,也会导致分页查询受到限制)
垂直分割:
如果一个表的列数过多同样也会影响性能,因此可以建立外键,将一个表垂直分割成多个表。
三.数据库索引及索引的原理
为什么需要索引?如何创建索引?
因为有些情况下使用索引能大大提高数据访问的性能。
创建索引:使用CREATE INDEX语句对表增加索引。例如:CREATE INDEX indexName ON mytable(username(length));
什么情况下适合建立索引?什么情况下不适合建立索引?
1、较频繁地作为查询条件的字段适合建立索引
2、主键是一种唯一性索引
3、高并发的情况下一般选择复合索引
4、唯一性太差的字段不适合建立索引
5、更新太频繁地字段不适合创建索引
6、不会出现在where条件中的字段不应该建立索引
7、表记录太少,不需要创建索引
索引底层原理:
四.sql语句本身的优化
1.尽量少使用select *,应该找自己需要的字段
2.如果一次不需要取出全部数据可用limit分页优化
3.尽量避免类型转换
4.where子句使用 != 或 <> 操作符优化
在where子句中使用 != 或 <>操作符,索引将被放弃使用,会进行全表查询。
如SQL:SELECT id FROM A WHERE ID != 5 优化成:SELECT id FROM A WHERE ID>5 OR ID<5
5.where子句中使用 IS NULL 或 IS NOT NULL 的优化
在where子句中使用 IS NULL 或 IS NOT NULL 判断,索引将被放弃使用,会进行全表查询。
如SQL:SELECT id FROM A WHERE num IS NULL 优化成num上设置默认值0,确保表中num没有null值,然后SQL为:SELECT id FROM A WHERE num=0
6.合理使用like模糊查询
有的时候会需要进行一些模糊查询比如:
SELECT id FROM user WHERE username like ‘%张%’,关键词 %张%,由于yue前面用到了“%”,因此该查询必然走全表扫描,除非必要,否则不要在关键词前加%
7.使用批量插入语句,节省交互
......
五.数据库读写分离
六.存储过程
合理使用存储过程也能提高性能,但存储过程的缺陷是SQL语句是死的。
七.配置MySQL本身参数
配置最大连接数,内存等
查看数据库连接数:
show variables like '%max_connections%';
如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,
就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。
对于mysql服务器最大连接数值的设置范围比较理想的是:服务器响应的最大连接数值占服务器上限连接数值的比例值在10%以上,如果在10%以下,说明mysql服务器最大连接上限值设置过高。
设置最大连接数
set GLOBAL max_connections=200;
八.清理碎片化
九.表中的数据
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
(1)越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2)简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3)尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
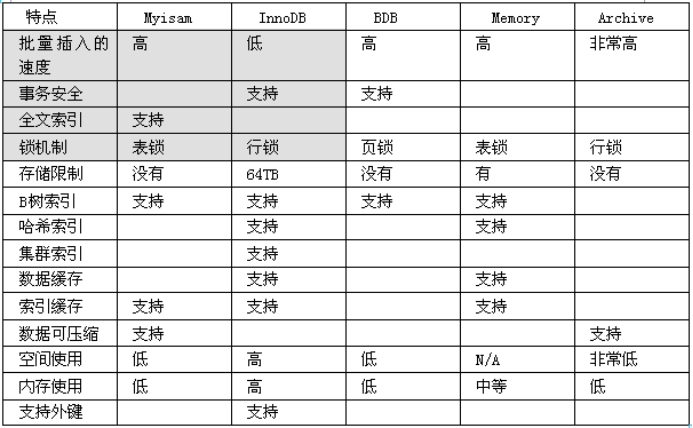
十.选择合适的存储引擎
MySQL使用的存储引擎 myisam / innodb/ memory
MyISAM 存储: 如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎. ,比如 bbs 中的 发帖表,回复表.
INNODB 存储: 对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表.
MyISAM 和 INNODB的区别:
1. 事务安全(MyISAM不支持事务,INNODB支持事务)
2. 查询和添加速度(MyISAM批量插入速度快)
3. 支持全文索引(MyISAM支持全文索引,INNODB不支持全文索引)
4. 锁机制(MyISAM时表锁,INNODB是行锁)
5. 外键 MyISAM 不支持外键, INNODB支持外键. (在PHP开发中,通常不设置外键,通常是在程序中保证数据的一致)
Memory 存储,比如我们数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory, 速度极快. (如果mysql重启的话,数据就不存在了)