为了生成最优化的算法模型,必须对数据进行理解。最快、最有效的方式是通过数据的可视化来加强对数据的理解。
接下来将通过matplotlib对数据可视化,以加强对原始数据集的理解。
单一图表
直方图(Histogram)又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据的分布情况。一般用横轴表示数据类型,纵轴表示分布情况。直方图可以非常直观展示每个属性的分布情况。通过图表可以很直观地看到数据是高斯分布、指数分布还是偏态分布。代码如下
1 from pandas import read_csv 2 import matplotlib.pyplot as plt 3 #使用pandas导入CSV数据 4 filename='/home/aistudio/work/pima_data1.csv' 5 names=['preg','plas','pres','skin','test','mass','pedi','age','class'] 6 data=read_csv(filename,names=names) 7 data.hist() 8 plt.show()

从上图可以看到,age、pedi和test也许是指数分布;mass、pres、plas也许是高斯分布。
密度图是一种表现与数据值对应的边界或域对象的图形表示方法,一般用于呈现连续变量。密度图类似于对直方图进行抽象,用平滑的线来描述数据的分布。这也是一种用来显示数据分布的图表。代码如下:
1 from pandas import read_csv 2 import matplotlib.pyplot as plt 3 4 filename='/home/aistudio/work/pima_data1.csv' 5 names=['preg','plas','pres','skin','test','mass','pedi','age','class'] 6 data=read_csv(filename,names=names) 7 data.plot(kind='density',subplots=True,layout=(3,3),sharex=False) 8 plt.show()

通过密度图来显示数据分布,相对于直方图更直观。
箱线图又称盒须图、盒式图或箱型图,是一种用于显示一组数据分布情况的统计图。因形状如箱子儿得名,在各种领域都经常被使用。
首先画一条中位数线,然后以下四位分数和上四位分数画一个盒子,上下各有一条横线,表示上边沿和下边沿,通过横线来显示数据的伸展状态,游离在边沿之外的点为异常值。
1 rom pandas import read_csv 2 import matplotlib.pyplot as plt 3 4 filename='/home/aistudio/work/pima_data1.csv' 5 names=['preg','plas','pres','skin','test','mass','pedi','age','class'] 6 data=read_csv(filename,names=names) 7 data.plot(kind='box',subplots=True,layout=(3,3),sharex=False) 8 plt.show()
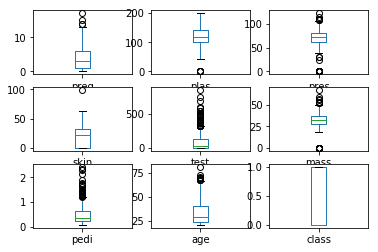
上图显示,不同属性的延伸截然不同。
相关矩阵图主要用来展示两个不同属性相互影响的程度。如果两个属性按照相同的方向变化,说明是正影响。如果两个属性朝相反的方向变化,说明是反向影响。把所有属性两两影响的关系展示出来的图表叫相关矩阵。
矩阵图法就是从多维问题的事件中找出成对的因素,排列成矩阵图,然后根据矩阵图来分析问题,确定关键点。它是一种通过多因素综合思考来探索问题的好方法。
1 from pandas import read_csv 2 import matplotlib.pyplot as plt 3 import numpy as np 4 5 filename='/home/aistudio/work/pima_data1.csv' 6 names=['preg','plas','pres','skin','test','mass','pedi','age','class'] 7 data=read_csv(filename,names=names) 8 correlations=data.corr() 9 fig=plt.figure() 10 ax=fig.add_subplot(111) 11 cax=ax.matshow(correlations,vmin=-1,vmax=1) 12 fig.colorbar(cax) 13 ticks=np.arange(0,9,1) 14 ax.set_xticks(ticks) 15 ax.set_yticks(ticks) 16 ax.set_xticklabels(names) 17 ax.set_yticklabels(names) 18 plt.show()
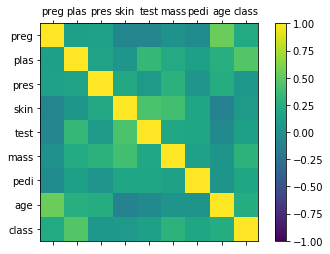
在图表的左边和上边显示的是完全相同的属性名称,通过这个矩阵可以清楚地看到各个属性两两关联的关系。
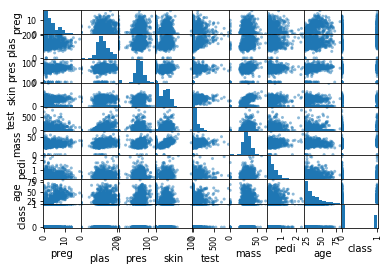
散点矩阵图表示因变量随自变量变化的大致趋势,据此可以选择合适的函数对数据点进行拟合。散点矩阵图由两组数据构成多个坐标点,考察坐标点的分布,可以判断两个变量之间是否存在某种关联或总结坐标点的分布模式。散点矩阵图将序列显示为一组点,值由点在图表中的位置表示,类别由图表中的不同标记表示。散点矩阵图通常用于比较跨类别的聚合数据。当同时考察多个变量的相关关系时,若一一绘制它们的简单散点图将十分麻烦。此时可以利用散点矩阵图来绘制各个变量间的散点图,这样可以快速发现多个变量间的主要相关性,这在进行多元线性回归时显得尤为重要。
1 from pandas import read_csv 2 import matplotlib.pyplot as plt 3 from pandas.plotting import scatter_matrix 4 5 filename='/home/aistudio/work/pima_data1.csv' 6 names=['preg','plas','pres','skin','test','mass','pedi','age','class'] 7 data=read_csv(filename,names=names) 8 scatter_matrix(data) 9 plt.show()