当今数据计算领域的主要应用程序和模型可大致分为三大类:
(1)联机事务处理(OLTP)、
(2)决策支持系统(DSS)
(3)企业信息通讯(BusinessCommunications)
上述三类系统设计人员在计算平台的体系结构方面可以选择:
(1)小型独立服务器模式
(2)对称多处理SMP(Symmetrical Multi-Processing)模式
(3)大规模并行处理MPP(Massive Parallel Processing)模式
(4)非统一内存访问架构NUMA(Non Uniform Memory Access Architecture)模式
。因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,
SMP的缺点是可伸缩性有限,因为在存储器接口达到饱和的时候,增加处理器并不能获得更高的性能。
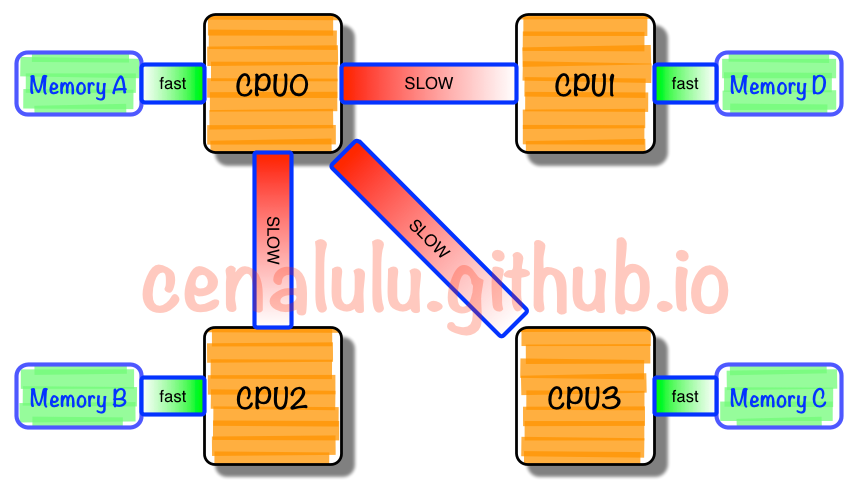
NUMA是什么
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间
(Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(Remote Access)。
所以NUMA(Non-Uniform Memory Access)就此得名。
二、NUMA相关的策略
1、每个进程(或线程)都会从父进程继承NUMA策略,并分配有一个优先node。如果NUMA策略允许的话,进程可以调用其他node上的资源。
2、NUMA的CPU分配策略有cpunodebind、physcpubind。
cpunodebind规定进程运行在某几个node之上
physcpubind可以更加精细地规定运行在哪些核上
3、NUMA的内存分配策略有localalloc、preferred、membind、interleave。
localalloc规定进程从当前node上请求分配内存
preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存
interleave规定进程从指定的若干个node上以RR算法交织地请求分配内存
使用numactl –interleave来修改NUMA策略即可。
参考:
cpu三大架构 numa smp mpp
cenalulu: numa