scrapy框架是Python爬虫的一个使用起来不错的框架,通过这个框架可以很快的爬出自己想要的数据
官方的定义是如下的图片,其实看不太懂
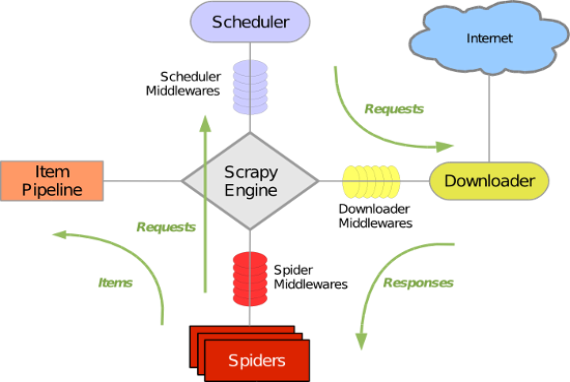
在平常使用这个框架的时候,主要用三部分,spider爬虫主体,在这里面写爬虫程序,items定义爬虫对象,pipeline对象输出管道,可以设置多个管道,,注意,使用pipeline管道时候得在setting.py中开启管道的设置,默认注释掉。
在使用scrapy框架前得先安装pywin32和下面这个Twisted模块,安装教程网上一大堆,一般只要下载好自己电脑对应的版本就不会出什么大问题
 我使用的是这个版本
我使用的是这个版本
pip install Twisted-18.4.0-cp36-cp36m-win_amd64.whl // 先安装,否则直接安装scrapy会报错
pip install –U scrapy
安装成功后就可以开始自己的第一个scrapy程序了
在pycharm自带的Terminal中输入
scrapy startproject 工程名
cd 工程名
scrapy genspider 工程名 要爬取的网站
然后就是写爬虫主程序 spider.py 更改items 更改输出管道 pipeline
最后在terminal中输出 scrapy crawl 主程序中的name 执行scrapy
这样一个基本的scrapy框架就完事了
下面是最基本的文件树
