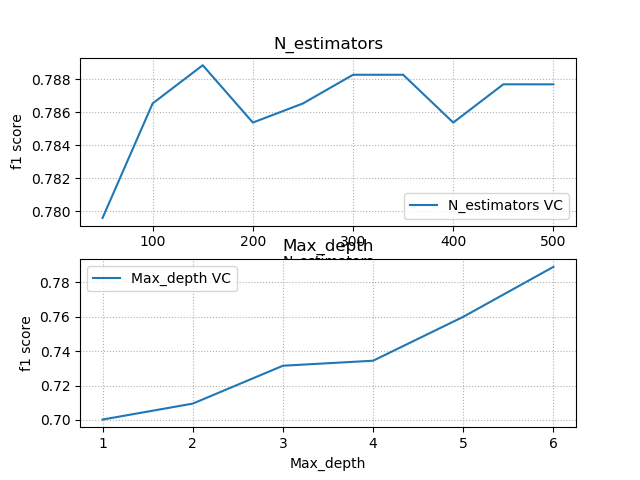
''' 验证曲线:模型性能 = f(超参数)----通过优化模型参数,达到优化模型预测结果,使得模型预测更加精准 验证曲线所需API: train_scores, test_scores = ms.validation_curve( model, # 模型 输入集, 输出集, 'n_estimators', #超参数名 np.arange(50, 550, 50), #超参数序列 cv=5 #折叠数 ) train_scores的结构: 超参数取值 第一次折叠 第二次折叠 第三次折叠 第四次折叠 第五次折叠 50 0.91823444 0.91968162 0.92619392 0.91244573 0.91040462 100 0.91968162 0.91823444 0.91244573 0.92619392 0.91244573 ... ... ... ... ... ... test_scores的结构与train_scores的结构相同。 案例:在小汽车评级案例中使用验证曲线选择较优参数。 ''' import numpy as np import matplotlib.pyplot as mp import sklearn.preprocessing as sp import sklearn.ensemble as se import sklearn.model_selection as ms import sklearn.metrics as sm import warnings warnings.filterwarnings('ignore') data = [] with open('./ml_data/car.txt', 'r') as f: for line in f.readlines(): sample = line[:-1].split(',') data.append(sample) data = np.array(data) # print(data.shape) # 整理好每一列的标签编码器encoders # 整理好训练输入集与输出集 data = data.T # print(data.shape) encoders = [] train_x, train_y = [], [] for row in range(len(data)): encoder = sp.LabelEncoder() if row < len(data) - 1: # 不是最后列 train_x.append(encoder.fit_transform(data[row])) else: # 是最后一列,作为输出集 train_y = encoder.fit_transform(data[row]) encoders.append(encoder) train_x = np.array(train_x).T # 训练随机森林分类器 model = se.RandomForestClassifier(max_depth=6, n_estimators=150, random_state=7) # 获取n_estimators的验证曲线 train_scores, test_scores = ms.validation_curve(model, train_x, train_y, 'n_estimators', np.arange(50, 550, 50), cv=5) # print('test_scores', test_scores, sep=' ') # print(np.mean(test_scores, axis=1)) # 获取max_depth的验证曲线 train_scores1, test_scores1 = ms.validation_curve(model, train_x, train_y, 'max_depth', np.arange(1, 7), cv=5) # print('test_scores1', test_scores1, sep=' ') # print(np.mean(test_scores1, axis=1)) # 训练之前进行交叉验证 cv = ms.cross_val_score(model, train_x, train_y, cv=4, scoring='f1_weighted') # print(cv.mean()) model.fit(train_x, train_y) # 自定义测试集,预测小汽车的等级 # 保证每个特征使用的标签编码器与训练时使用的标签编码器匹配 data = [ ['high', 'med', '5more', '4', 'big', 'low', 'unacc'], ['high', 'high', '4', '4', 'med', 'med', 'acc'], ['low', 'low', '2', '4', 'small', 'high', 'good'], ['low', 'med', '3', '4', 'med', 'high', 'vgood']] data = np.array(data).T test_x, test_y = [], [] for row in range(len(data)): encoder = encoders[row] # 每列对应的标签编码器 if row < len(data) - 1: test_x.append(encoder.transform(data[row])) # 这里需要训练了,直接转换 else: test_y = encoder.transform(data[row]) test_x = np.array(test_x).T pred_test_y = model.predict(test_x) print(pred_test_y) pred_test_y = encoders[-1].inverse_transform(pred_test_y) test_y = encoders[-1].inverse_transform(test_y) # print(pred_test_y) # print(test_y) # 画图显示验证曲线 mp.figure('Validation Curve', facecolor='lightgray') mp.subplot(211) mp.title('N_estimators') mp.xlabel('N_estimators') mp.ylabel('f1 score') mp.grid(linestyle=":") mp.plot(np.arange(50, 550, 50), np.mean(test_scores, axis=1), label='N_estimators VC') mp.legend() mp.subplot(212) mp.title('Max_depth') mp.xlabel('Max_depth') mp.ylabel('f1 score') mp.grid(linestyle=":") mp.plot(np.arange(1, 7), np.mean(test_scores1, axis=1), label='Max_depth VC') mp.legend() mp.show() 输出结果: [2 0 0 3] ['unacc' 'acc' 'acc' 'vgood'] ['unacc' 'acc' 'good' 'vgood']