需求
假设我们有一张各个产品线URL的访问记录表,该表仅仅有两个字段:product、url,我们需要统计各个产品线下访问次数前10的URL是哪些?
解决方案
(1)模拟访问记录数据

模拟数据记录共有1000条,其中包括10个产品线:product1、product2、…、product10,100个URL:url1、url2、…、url100,为了简化生成数据的过程,产品线和URL均使用了随机数。一条记录为一个字符串,产品线与URL使用空格进行分隔。模拟数据存储在一个名为“data”的列表中,通过parallelize的方式形成一个RDD:table,再使用inferSchema的方式注册为一张临时表“product_url”。
表“product_url”的示例数据如下:
(2)统计各个产品线下各个URL的访问次数

这个逻辑使用Spark SQL即可以实现,示例数据如下:
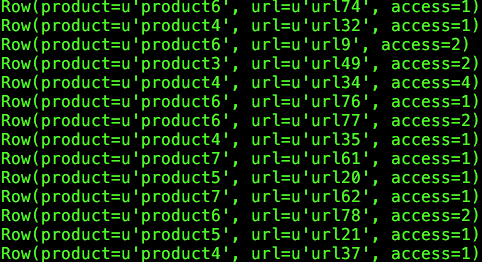
可以看出,数据多出了一个字段access,用于表示某产品线下某个URL的访问次数。
此外,如果我们有一个数据类型为Row的变量row,可以通过row.product、row.url、row.access或者row[0]、row[1]、row[2]访问product、url、access对应的数据。
(3)“分区排序取值”
我们的统计需求有一个明显的分界线:产品线,Top N的处理逻辑可以转变为:
a. 根据分界线做分区,即每一个产品线的记录进入同一个分区;
b. 每一个分区(产品线)内根据URL的访问次数(access)排序(降序);
c. 每一个分区(产品线)内取前N条数据即可。
a、b实际就是一个“分区排序”的过程,Spark RDD也为“分区排序”提供了非常方便的API:repartitionAndSortWithinPartitions,但是该函数需要传入的数据类型要求为(key, value),因此我们需要对(2)中的数据做一下简单的处理:

其实就是将数据类型Row映射为元组(Row, None),示例数据如下:

此外repartitionAndSortWithinPartitions还需要两个函数:partitionFunc、keyFunc,这两个函数都需要接收一个参数,该参数为(key, value)中的key。
partitionFunc用于根据(key, value)中的key如何选取分区,返回值要求为整型,数值即为分区号,即0表示分区0,1表示分区1,…。

这里key的数据类型即为Row。
因为我们模拟了10个产品线,每一个产品线的数据需要被划分到同一个分区内,因此我们也需要10个分区(分区序号为0—9),根据产品线划分分区的规则为:产品线product1的分区为0,产品线product2的分区为1,…,产品线product10的分区为9。其中key[0]为产品线名称,key[0][7]为产品线名称中的随机数,将key[0][7]转换为整数并减一即可得到对应的分区号。
keyFunc用于根据(key, value)中的key如何排序,“分区内排序”时即根据该函数的返回值进行排序。
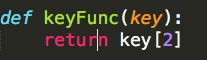
其中,key[2]为访问次数access,我们就是需要在某个分区(产品线)内根据URL的访问次数做排序。
函数partitionFunc、keyFunc准备好之后,我们可以开始调用repartitionAndSortWithinPartitions:

需要注意的是,numPartitions值为10,该值取决于分区(产品线)的个数;ascending值为False,该值表示分区内排序时使用降序。
“分区排序”之后我们即可以开始“取值”,取值的过程比较简单:在每个分区内即前N(这里假设为10,即top 10)个值,将这些值“汇总”之后即可得出各个产品线下URL访问次数的Top 10。
考虑到我们需要“汇总”的需求,因此不能使用foreachPartition,需要通过mapPartitions实现,它需要一个函数:f,函数f的参数为一个“迭代器”,通过这个“迭代器”可以遍历分区内的所有数据。

从上面的代码可以看出,我们就是通过“迭代器”iter获取分区内的前10条数据(如果分区内的数据条数大于或等于10的话)。
“汇总”(collect)结果:

rows中保存着各个产品线下URL访问次数的Top 10记录。
(4)结果处理
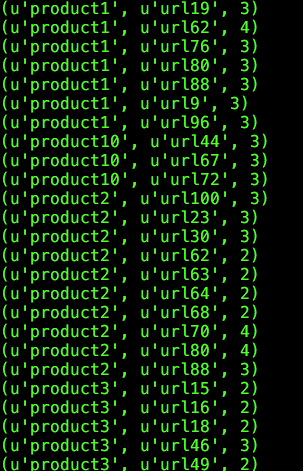
计算完成之后,我们可以对结果进行一些处理,如:根据产品线、URL根据字典序排序并输出,代码如下:

示例数据:
总结
使用Spark解决Top N问题时,只需要经过“划分分区、分区内排序、分区内取值”三个过程即可完成。