一、什么是决策树?
决策树的原理:通过一系列问题进行if/else的推导,最终实现决策。
我们经常用决策树处理分类问题,决策树是最经常使用的数据挖掘算法。K-近邻算法可以完成很多分类任务,但是最大的缺点是给出的数据没有内在意义,决策树的优势就在于数据形式非常容易理解。
二、决策树的构造
在一个数据集上哪个特征在划分数据分类时能起到决定性作用?所以,为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。
找到那个决定性的特征后,原数据集就被划分为几个数据子集,这些数据子集会分布在第一个决策点的所有分支上,如果某个分支下的数据属于同一个类型,则可以划分数据类型,如果数据子集内的数据不属于一个类型,则需要重复划分数据子集的过程,直到所有具有相同类型的数据均在一个数据子集内。
创建分支的伪代码函数createBranch()如下所示:
检测数据集中的每个子项是否属于同一分类:
If so return 类标签;
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
return 分支节点
上面的伪代码createBranch是一个递归函数,在倒数第二行直接调用了它自己。后面我们 将把上面的伪代码转换为Python代码,这里我们需要进一步了解算法是如何划分数据集的。
决策树的一般流程 (1) 收集数据:可以使用任何方法。 (2) 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。 (3) 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。 (4) 训练算法:构造树的数据结构。 (5) 测试算法:使用经验树计算错误率。 (6) 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据 的内在含义。
三、举个例,学习决策树算法的原理过程
表3-1的数据包含5个海洋动物,特征包括:不浮出水面是否可以生存,以及是否有脚蹼。我 们可以将这些动物分成两类:鱼类和非鱼类。现在我们想要决定依据第一个特征还是第二个特征 划分数据。在回答这个问题之前,我们必须采用量化的方法判断如何划分数据。下一小节将详细 讨论这个问题。
表3-1 海洋生物数据 不浮出水面是否可以生存 是否有脚蹼 属于鱼类 1 是 是 是 2 是 是 是 3 是 否 否 4 否 是 否 5 否 是 否
下面讲解采用量化判断如何划分数据:
信息增益:计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
介绍信息增益之前,首先需要介绍一下熵的概念,这是一个物理学概念,表示“一个系统的混乱程度”。系统的不确定性越高,熵就越大。假设集合中的变量X={x1,x2…xn},它对应在集合的概率分别是P={p1,p2…pn}。那么这个集合的熵表示为:
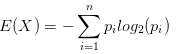
举一个的例子:对游戏活跃用户进行分层,分为高活跃、中活跃、低活跃,游戏A按照这个方式划分,用户比例分别为20%,30%,50%。游戏B按照这种方式划分,用户比例分别为5%,5%,90%。那么游戏A对于这种划分方式的熵为:

同理游戏B对于这种划分方式的熵为:

游戏A的熵比游戏B的熵大,所以游戏A的不确定性比游戏B高。用简单通俗的话来讲,游戏B要不就在上升期,要不就在衰退期,它的未来已经很确定了,所以熵低。而游戏A的未来有更多的不确定性,它的熵更高。 --------------------- 作者:It_BeeCoder 来源:CSDN 原文:https://blog.csdn.net/it_beecoder/article/details/79554388 版权声明:本文为博主原创文章,转载请附上博文链接!

程序清单1:计算给定数据集的信息熵
1 #计算训练数据最后一列的信息熵 2 def calcShannonEnt(dataSet): 3 #获取训练数据集行数(记录数) 4 numEntries = len(dataSet) 5 labelCounts = {} 6 #使用for循环从上往下逐行读取每一条记录,统计训练数据集各种标签数量有多少 7 for featVec in dataSet: 8 #取出当前这条记录的标签 9 currentLabel = featVec[-1] 10 #判断当前得到的这个标签currentLabel是否已经存在字典labelCounts的键(key)了 11 #labelCounts.keys():字典调用keys()这个函数可以获取它所有的键(key) 12 if(currentLabel not in labelCounts.keys()): 13 #如果字典labelCounts的所有键都没有当前这个标签,这个字典就新增一个键和值,键是当前这个标签,值是0 14 labelCounts[currentLabel] = 0 15 #如果字典labelCounts的所有键存在这个标签,那就把这个键对应的值加1 16 labelCounts[currentLabel] += 1 17 #声明一个变量保存最后一列的信息熵值,最后一列所有标签的熵值带入公式就可以求得该列的信息熵。 18 shannonEnt = 0.0 19 #for循环读取每一个字典的每一个键(key),也就是取得标签 20 for key in labelCounts: 21 #计算当前这个标签占的概率 22 prob = float(labelCounts[key])/numEntries 23 #将这个标签的概率带入熵的计算公式,最后就可以计算得到该列的信息熵了, 24 #因为这是计算数据集标签列的信息熵,所有该信息熵就是该数据集的信息熵 25 shannonEnt -= prob * log(prob,2) 26 #函数返回该训练数据集的信息熵 27 return shannonEnt
程序清单2:按照给定的特征划分数据集
1 #这个函数是用来划分数据集的 2 #dataSet:待划分的数据集 3 #axis:这是一个特征的下标,就是根据这个特征来划分 待划分dataSet数据集的 4 #value:下标axis对应的那个特征下的某个值,根据这个值来进一步确定数据集的划分 5 def splitDataSet(dataSet, axis, value): 6 #声明一个列表用来保存划分后得到的数据集 7 retDataSet = [] 8 #使用for循环从上往下逐行读取记录 9 for featVec in dataSet: 10 #featVec:就是当前的一条记录 11 #featVec[axis]:就是数据集第axis+1个特征的值,如:featVec[1]就表示:这是第二个特征的某个取值 12 #判断这个取值是否等于axis个特征下划分数据集的值 13 if(featVec[axis] == value): 14 #如果相等就把第axis+1特征前面的数据都保存到这个列表reducedFeatVec 15 reducedFeatVec = featVec[:axis] 16 #在retDataSet右边紧接着保存第axis+1特征后面的数据都保存到这个列表reducedFeatVec 17 reducedFeatVec.extend(featVec[axis+1:]) 18 #这样就得到了一条新的数据记录,与原来featVec这条数据记录相比,它少了特征下标为axis的数据 19 #将这条新的数据保存到列表retDataSet里面 20 retDataSet.append(reducedFeatVec) 21 #返回拆分后的数据集,与原来待划分的数据集dataSet相比,retDataSet它少了特征下标为axis这一列的数据 22 return retDataSet
程序清单3:选择最好的数据集划分方式
函数chooseBestFeatureToSplit()使用了程序清单1和程序清单2的函数。
1 #一般数据集都是有很多属性的,那该选取那个属性作为决策树的根节点呢? 2 #这个函数就是确定哪个属性作为根节点的 3 #选择信息增益最大的那一列的属性作为根节点 4 5 #dataSet:当前传递过来的数据集 6 def chooseBestFeatureToSplit(dataSet): 7 #获取数据集有多少个属性,数据集最后一列是标签,不是数据集的变量属性,所以要减1 8 numFeatures = len(dataSet[0]) - 1 9 #计算这个数据集dataSet的信息熵(也就是计算最后的标签列的熵值) 10 baseEntropy = calcShannonEnt(dataSet) 11 #定义一个变量保存信息增益,所谓的信息增益就是:上面数据集dataSet的信息熵baseEntropy 与 某个特征的信息熵的差值 12 bestInfoGain = 0.0 13 #定义一个变量保存最好的一个特征的下标,所谓最好特征,就是该特征与数据集dataSet的信息熵baseEntropy的差值(信息增益), 14 #比其它特征与数据集dataSet的信息熵baseEntropy的差值(信息增益)都要大 15 bestFeature = -1 16 #从左到右逐个特征地读取(一列一列地读取原数据集的各种特征的值) 17 for i in range(numFeatures): 18 #featList:就是下标为i的特征那一列的值 19 #example:是数据集的一条记录 20 #example[i]:取得这条数据记录下标为i的数值(取得第i+1个属性的值(下标从零开始)) 21 featList = [example[i] for example in dataSet] 22 #将这列的数据去重,uniqueVals里面的元素都是唯一的 23 uniqueVals = set(featList) 24 #newEntropy这个变量是用来保存这列数据信息熵的(也就是当前这个特征的信息熵) 25 newEntropy = 0.0 26 #逐个取出该列不同的值 27 for value in uniqueVals: 28 #然后调用划分数据集函数splitDataSet 来划分当前dataSet这个数据集 29 #根据当前第i+1个特征(特征下标从零开始)和这个具体的特征值,就可以划分数据集了 30 #(这里不是很理解的话,今晚再画图跟你说一下就可以了,看着代码处理好像挺抽象复杂的,其实并不是很复杂) 31 #跟我们平时划分表格一样的思路和操作,暂时看不懂的地方不用太过去纠结的,顺其自然往下看就可以了,放心...有我在...... 32 subDataSet = splitDataSet(dataSet, i, value) 33 #subDataSet :就是根据当前特征和当前特征的value划分得到的新的数据集 34 #计算根据当前特征和当前特征的value 所占的概率 35 prob = len(subDataSet)/float(len(dataSet)) 36 #calcShannonEnt(subDataSet) :计算新得到的这个数据集的信息熵 37 #prob * calcShannonEnt(subDataSet) :给这个信息熵加权,这个权就是上面那个概率 38 #然后下标为i这个特征下的所有值对应的信息熵加权值 都累积保存到变量newEntropy中 39 newEntropy += prob * calcShannonEnt(subDataSet) 40 #结束循环后,newEntropy就是下标为i的特征的信息熵了 41 #接下来计算该列(下标为i的特征列) 信息增益,也就是与划分之前数据集dataSet的信息熵的差值 42 infoGain = baseEntropy - newEntropy 43 #计算出某列的信息增益infoGain后,判断这个信息增益是不是比预先定义的 bestInfoGain = 0.0信息增益要大 44 if (infoGain > bestInfoGain): 45 #如果根据下标i的特征划分后得到的数据集信息增益比预先定义的要大,说明根据该特征来划分数据集是可行的 46 #把当前这个大的信息增益替换掉原来预先定义的信息增益 47 bestInfoGain = infoGain 48 #使用变量bestFeature记录下最大信息增益那个特征的下标 49 bestFeature = i 50 #返回计算得到信息增益最大的那个属性的下标,根据这个下标就可以找到那个特征作为根节点了 51 return bestFeature
程序清单4:创建树的函数代码
1 #这是一个根据训练数据集生成一棵决策树的函数 2 #dataSet:训练数据集 3 #labels:训练数据集每一列的属性 4 def createTree(dataSet,labels): 5 #获取数据集的标签列 6 classList = [example[-1] for example in dataSet] 7 #判断标签列表是不是只剩下一种类别 8 if(classList.count(classList[0]) == len(classList)): 9 #如果是就返回这个标签,结束本次对函数createTree的调用,这个返回去的标签就作为决策树的一个叶子节点 10 return classList[0] 11 #判断数据集是不是只剩下一列数据 12 if(len(dataSet[0]) == 1): 13 #是的话,那这列数据便是数据集最后的标签列,这时通过调用majorityCnt函数来统计, 14 #结束本次对函数createTree的调用该返回那个类别标签 15 return majorityCnt(classList) 16 #调用chooseBestFeatureToSplit来获得当前数据集dataSet的最优划分特征下标 17 bestFeat = chooseBestFeatureToSplit(dataSet) 18 #根据这个下标找到对应的那个特征 19 bestFeatLabel = labels[bestFeat] 20 #使用字典保存一棵决策树,根节点就是上面的那个特征 21 myTree = {bestFeatLabel:{}} 22 #定义一个列表保存除去那个bestFeatLabel最优特征外的其它特征 23 temp = [] 24 #使用for循环逐个地读取特征 25 for i in labels: 26 #判断如果这个特征i不是上面的那个最优特征,就保存到temp里面 27 if(i != labels[bestFeat]): 28 temp.append(i) 29 #将除去那个bestFeatLabel最优特征外的其它特征作为剩下新的数据集特征 30 labels = temp 31 #取出最优特征bestFeatLabel那列的所有值 32 featValues = [example[bestFeat] for example in dataSet] 33 #将这列最优特征的值去重 34 uniqueVals = set(featValues) 35 #逐个取出该列不同的值 36 for value in uniqueVals: 37 #复制一份新的特征列表,记为:subLabels 38 subLabels = labels[:] 39 #这棵树现在根节点就是字典的键bestFeatLabel,条件值是字典的值value 40 #递归调用生成决策树这个createTree函数,一直重复上面的过程.....直到数据集只剩下标签列为止 41 # splitDataSet(dataSet, bestFeat, value):把切分后的数据集当做新的数据集 42 #subLabels:新数据集的特征列表 43 #(这个递归过程今晚回去了再详细画图跟你说说...) 44 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels) 45 #返回一棵决策树 46 return myTree
程序清单5:测试算法:使用决策树执行分类
1 这个函数是使用决策树来对未知标签数据进行预测分类的,也就是通过遍历一棵决策树来取得未知标签的预测值 2 #inputTree:一棵决策树 3 #featLabels:未知标签的数据的列名(属性) 4 #testVec:未知标签数据的值 5 def classify(inputTree,featLabels,testVec): 6 #获取根节点 7 for i in inputTree.keys(): 8 firstStr = i 9 break 10 #根据根节点firstStr,获取根节点下的子树 11 secondDict = inputTree[firstStr] 12 #获取根节点这个特征所在特征列表featLabels的位置下标 13 featIndex = featLabels.index(firstStr) 14 #根据根节点的下标,获取对应未知标签数据中的下标对应的值 15 key = testVec[featIndex] 16 #把上面得到的那个值作为子树的键,得到根节点的子树下的内容valueOfFeat 17 valueOfFeat = secondDict[key] 18 #判断valueOfFeat是不是字典,如果不是说明它就是叶子节点了,也就是那个需要返回的标签了 19 if isinstance(valueOfFeat, dict): 20 #如果子树下的内容还是字典,那就把valueOfFeat当成新的一棵树,继续调用classify这个函数,重复上面的过程 21 classLabel = classify(valueOfFeat, featLabels, testVec) 22 else: 23 #如果不是字典(子树),而是叶子节点(某个标签类别)的话,就直接返回这个标签就可以了 24 #这个返回的标签就是:对未知标签数据的一个预测标签 25 classLabel = valueOfFeat 26 #返回的就是对未知标签数据预测的标签 27 return classLabel