作者:伝迹、谦言、临在
欢迎使用我们最近开源的EasyCV,主要聚焦于最新的Vision Transformer模型,以及相关的下游CV任务
开源地址:https://github.com/alibaba/EasyCV
ViTDet其实是恺明团队MAE和ViT-based Mask R-CNN两个工作的延续。MAE提出了ViT的无监督训练方法,而ViT-based Mask R-CNN给出了用ViT作为backbone的Mask R-CNN的训练技巧,并证明了MAE预训练对下游检测任务的重要性。而ViTDet进一步改进了一些设计,证明了ViT作为backone的检测模型可以匹敌基于FPN的backbone(如SwinT和MViT)检测模型。
ViT作为检测模型的backbone需要解决两个问题:
- 如何提升计算效率?
- 如何得到多尺度特征?
ViT-based Mask R-CNN给出了初步的解决方案,ViTDet在此基础上,对如何得到多尺度特征做了进一步的改进。
如何提升计算效率
ViT采用的global self-attention和图像输入大小(HW)的平方成正比,对于检测模型,其输入分辨率往往较大,此时用ViT作为backbone在计算量和内存消耗上都是非常惊人的,比如输入尺寸为1024x1024,采用ViT-B训练Mask R-CNN单batch就需要消耗约20-30GB显存。为了解决这个问题,ViT-based Mask R-CNN将ViT分成4个stage,每个stage的前几个block采用windowed self-attention,最后一个block采用global self-attention,比较table 3 (2)和(3)显著降低显存消耗和训练时间,而且效果只有轻微下降。

ViTDet进一步研究了如何做window的信息聚合,除了采用4个global self-attention以外,还可以采用4个residual block。如下表(a)所示,采用4个conv blocks效果是最好的,并且basic block效果最好(b)。另外表(c)和表(d)表明每个stage的最后一个block使用信息聚合,速度和精度的平衡是最好的。

Backbone
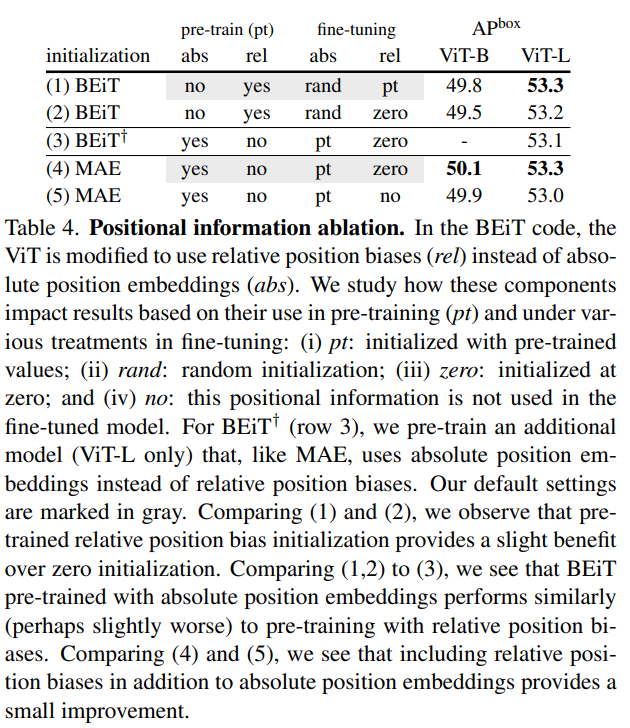
根据ViT-based Mask R-CNN论文table 4 (94)的结果,用预训练过的pos embed加上BEiT提出的relative position bias效果最好,其中将pos embed迁移到下游任务需要对pos embed的进行resize操作。
最开始实现了一版共享的relational position bias,精度上不去,感觉是打开方式不对,后来参照ViTAE的不共享relational paosition bias,能加快收敛速度,代码如下。
def calc_rel_pos_spatial(
attn,
q,
q_shape,
k_shape,
rel_pos_h,
rel_pos_w,
):
"""
Spatial Relative Positional Embeddings.
"""
sp_idx = 0
q_h, q_w = q_shape
k_h, k_w = k_shape
# Scale up rel pos if shapes for q and k are different.
q_h_ratio = max(k_h / q_h, 1.0)
k_h_ratio = max(q_h / k_h, 1.0)
dist_h = (
torch.arange(q_h)[:, None] * q_h_ratio -
torch.arange(k_h)[None, :] * k_h_ratio)
dist_h += (k_h - 1) * k_h_ratio
q_w_ratio = max(k_w / q_w, 1.0)
k_w_ratio = max(q_w / k_w, 1.0)
dist_w = (
torch.arange(q_w)[:, None] * q_w_ratio -
torch.arange(k_w)[None, :] * k_w_ratio)
dist_w += (k_w - 1) * k_w_ratio
Rh = rel_pos_h[dist_h.long()]
Rw = rel_pos_w[dist_w.long()]
B, n_head, q_N, dim = q.shape
r_q = q[:, :, sp_idx:].reshape(B, n_head, q_h, q_w, dim)
rel_h = torch.einsum('byhwc,hkc->byhwk', r_q, Rh)
rel_w = torch.einsum('byhwc,wkc->byhwk', r_q, Rw)
attn[:, :, sp_idx:, sp_idx:] = (
attn[:, :, sp_idx:, sp_idx:].view(B, -1, q_h, q_w, k_h, k_w) +
rel_h[:, :, :, :, :, None] + rel_w[:, :, :, :, None, :]).view(
B, -1, q_h * q_w, k_h * k_w)
return

将ViT作为ViTDet的预训练需要对foward过程进行改造,通过window_partition和window_reverse两个操作,对输入feature反复进行切window和还原,这样子可以充分利用ViT的预训练模型,同时提高检测的计算效率,论文中描述如上。
ViT-based Mask R-CNN和ViTDet提到的window size都是14x14,但是在输入分辨率为1024x1024的情况下,先经过一个patch_embed,就变成了64x64的分辨率,64是不能整除14的,
这里有两种处理方式:
1.在patch_embed之后加一个插值变成56x56,从ViT输出的时候再插值回64x64。
2.在patch_embed之后pad成70x70,恢复成原图的时候裁剪成64x64。
两种都试了一下,发现第二种不会掉点,而第一种可能会导致position embedding的不对齐,代码如下。
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
...
...
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B_, H * W, C)
如何得到多尺度特征

ViT模型是同质结构,如果采用的patch size为16x16,那么最终就得到一种1/16的尺度特征。但是常用的检测模型往往需要多尺度特征,大多数CNN和金字塔ViT都可以适应这种输出,比如ResNet从不同stage提取1/4,1/8,1/16和1/32的特征,并送入FPN进一步融合得到多尺度特征。ViT-based Mask R-CNN借鉴了XCiT的解决方案,将ViT的transformer blocks均分成4个部分,然后从d/4,2d/4,3d/4和d的输出分别提取1/4,1/8,1/16和1/32的特征(分别采用2个stride=2的反卷积,一个stride=2的反卷积,identity,stride=2的max pooling),然后送入FPN。

而ViTDet进一步简化了这种策略,直接用最后的1/16特征通过上采样(stride=2的反卷积)或者下采样(stride=2的max pooling)得到4个尺度的特征,而且也不再用FPN来进一步融合特征,如上图c所示。
比较table 1 (a)(b)(c)这种设计不仅简单,而且效果是最好的。

Simple feature pyramid

为了方便起见,简写为SFP。SFP先用ViT的最后一层构建出多尺度特征,然后分别接1个1x1conv做通道数reduce,再接一个3x3conv,论文中的描述如上。
论文中说在conv之后使用layernorm,那么就需要不断的进行reshape操作,实现起来会比较复杂冗余。为了实现更加简洁干净,复现采用了groupnorm等价layernorm的方式(只要把group数设置成1就可以了)。
按照ViTDet论文中的说法,应该是只有4层尺度特征,但是标准的FPN一般是5层,不清楚具体实现的时候是用的几层,本实现默认使用5层。
Mask RCNN

论文中对于mask rcnn的修改如上,总结一下:
rpn head 2conv + LN
roi head 4conv + 1fc,BN替换成LN
mask head BN替换成LN
数据增强


也就是说训练的时候,采用large scale jitter,然后padding成1024;推理的时候保持长宽比最长边不超过1024,然后padding成1024。
超参数

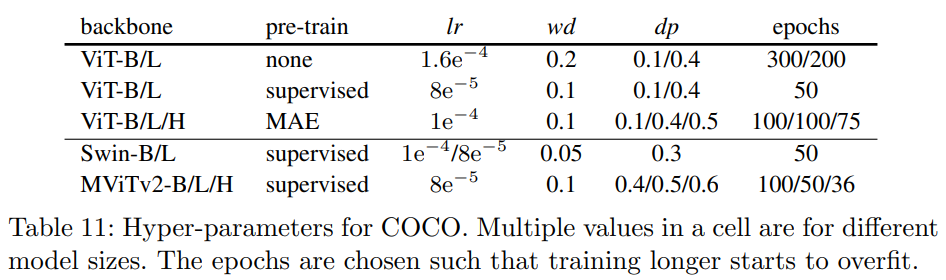
预训练默认使用mae_vit-base-p16-1600e,使用AdamW优化器,并且用step-wise lr,bs64,warmup 250 iter,lr 1e-4,weight decay 0.1,ViT-B的drop_path_rate设置成0.1。
ViTDet文章中说是layer-wise lr decay可以涨点0.3左右,但是我的实现导致最开始收敛很慢,感觉不一定有效。本实现默认不使用layer-wise lr decay。
复现ViTDet的过程中,让我惊叹的除了单尺度构建多尺度特征精度超过FPN之外,还有一点是从ViT -> SFP -> RPN Head -> RoI Head -> Mask Head的一整套流程中竟然没有使用一个BN,所有的norm都用LN替换掉了,这不是完全跟NLP对齐了。
预训练对比实验
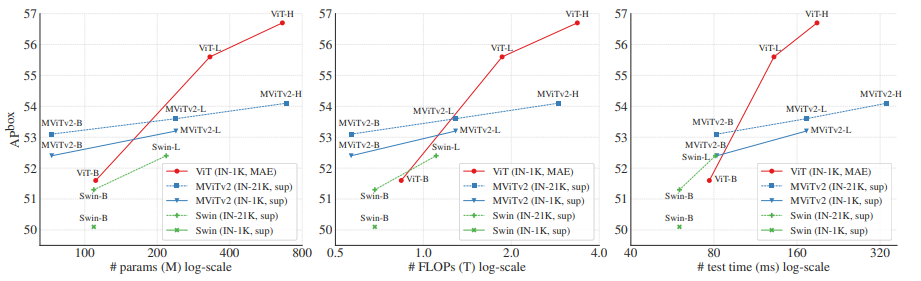
另外ViTDet还对有监督预训练和无监督预训练MAE做了对比实验,可以看到MAE可以大幅度提升AP,尤其是ViT-L,甚至超过了IN-21k有监督训练效果,如table 4所示。

和其他层次化的backbone相比,ViTDet也取得了最好的效果,如table 5所示。

效果图
最终复现的基于ViT-Base的ViTDet_MaskRCNN精度为50.6,比论文低0.6,可能还有一点点小细节没有考虑到的。

|
model |
base |
cur |
detials |
box_AP |
mask_AP |
lr |
epoch |
RunTime(hours) |
bs(total=imgs/gpu x gpu_nums x cumulative_iters) |
comments |
|
ViTDet |
- |
E0 |
|
50.6 |
45.0 |
step |
100 |
59 |
8node8bs=64 |
Tutorial
接下来,我们将通过一个实际的例子介绍如何基于EasyCV进行ViTDet算法的训练,也可以在该链接查看详细步骤。
一、安装依赖包
如果是在本地开发环境运行,可以参考该链接安装环境。若使用PAI-DSW进行实验则无需安装相关依赖,在PAI-DSW docker中已内置相关环境。
二、数据准备
你可以下载COCO2017数据,也可以使用我们提供了示例COCO数据
wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/data/small_coco_demo/small_coco_demo.tar.gz && tar -zxf small_coco_demo.tar.gz
mkdir -p data/ && mv small_coco_demo data/coco
data/coco格式如下:
data/coco/
├── annotations
│ ├── instances_train2017.json
│ └── instances_val2017.json
├── train2017
│ ├── 000000005802.jpg
│ ├── 000000060623.jpg
│ ├── 000000086408.jpg
│ ├── 000000118113.jpg
│ ├── 000000184613.jpg
│ ├── 000000193271.jpg
│ ├── 000000222564.jpg
│ ...
│ └── 000000574769.jpg
└── val2017
├── 000000006818.jpg
├── 000000017627.jpg
├── 000000037777.jpg
├── 000000087038.jpg
├── 000000174482.jpg
├── 000000181666.jpg
├── 000000184791.jpg
├── 000000252219.jpg
...
└── 000000522713.jpg
三、模型训练和评估
以vitdet-base为示例。在EasyCV中,使用配置文件的形式来实现对模型参数、数据输入及增广方式、训练策略的配置,仅通过修改配置文件中的参数设置,就可以完成实验配置进行训练。可以直接下载示例配置文件。
查看easycv安装位置
# 查看easycv安装位置
import easycv
print(easycv.__file__)
export PYTHONPATH=$PYTHONPATH:root/EasyCV
执行训练命令
单机8卡:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 --master_port=29500 tools/train.py configs/detection/vitdet/vitdet_100e.py --work_dir easycv/vitdet --launcher pytorch --fp16
8机8卡:
cp EasyCV/tools/launch.py ./ && cp EasyCV/tools/train.py ./ &&python -m launch --nproc_per_node=8 train configs/detection/vitdet_dlc/vitdet_100e.py --work_dir easycv/vitdet_100e --launcher pytorch --fp16
执行评估命令
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 --master_port=29500 tools/train.py configs/detection/vitdet/vitdet_100e.py --work_dir easycv/vitdet --launcher pytorch --fp16 --eval
Reference
模型细节来源:
- ViT-based Mask RCNN https://arxiv.org/abs/2111.11429
- ViTDet https://arxiv.org/abs/2203.16527
代码实现:
https://github.com/alibaba/EasyCV/blob/master/easycv/models/backbones/vitdet.py
https://github.com/tuofeilunhifi/EasyCV/blob/master/easycv/models/detection/vitdet/sfp.py
EasyCV往期分享
原文链接:http://click.aliyun.com/m/1000346408/
本文为阿里云原创内容,未经允许不得转载。