简介: 什么是算法?什么是广告算法工程师?算法工程师又是如何定义的?今天作者将就算法、电商算法为主题和我们分享他的理解,同时还将和我们分享ICBU算法团队的整体工作和2020年的一些重要技术突破。

写在最前
我个人有写年度总结的习惯,2020年我的工作职责有所变化,从垂直方向的广告算法变化到了水平横向的算法整体,所以这篇总结是关于阿里巴巴国际站(Alibaba.com,简称ICBU)算法团队的。本文内容主要包括以下几个部分:
- 第一部分,分享我对算法、电商算法的理解,以及ICBU算法团队的整体工作。
- 第二部分,ICBU算法团队在2020年的一些重要技术突破。
- 第三部分,关于工作中一些开放性问题的思考。
- 第四部分,明年的展望。
一、 ICBU算法团队简介
当年在做广告算法的时候,我曾经想过一个问题,“什么是广告算法工程师”?当时我从广告、广告算法、广告算法工程师这3个维度,分别阐述了这个问题。而现在,随着职责的变化,我问自己的问题就变成了,“什么是算法工程师?”
1 、算法
什么是算法?当我们提到《算法导论》这本书的时候,当我们给一个面试候选人出了一道“算法题”的时候,当我们提到“区块链算法”的时候,我们所说的算法,可能指的是排序算法、递归算法、随机算法、加密算法等等。这些“算法”,未必是我们现在“算法工程师”们日常工作中的最主要的内容,这其中有一些“算法”,是所有程序员必备的基础知识;而另外一些“算法”,似乎是算法工程师们所专有的。“算法(Algorithms)”这个概念太模糊,以至于不会有一个清晰的内涵和外延。
假如“算法”这个概念本身不那么清晰,那么“算法工程师”又是如何定义的呢?在国外,比如硅谷,是没有“算法工程师”这样的概念的,那里有数据科学家(Data Scientist)、应用科学家(Applied Scientist)、AI工程师(AI Engineer)、机器学习工程师(Machine Learning Engineer),唯独没有“Algorithm Engineer”这样的职位。
在国内互联网公司,最常见的对于“算法工程师”的定义,有两种:
- 工具视角:以“机器学习(或优化)”等技术为日常工作主要工具的工程师,称为算法工程师。就好比说,以“锛凿斧锯”为日常工作主要工具的工程师,我们称之为“木匠”一样,这种定义类似于Machine Learning Engineer。
- 目的视角:以“优化某可量化业务指标”为日常工作主要目的的工程师,称为算法工程师。就好比说,以“制作一个木质家具”为日常工作主要目的的工程师,我们称之为“木匠”一样,这种定义类似于“指标优化工程师”。
两种定义的视角,无所谓对错,但是会塑造出不一样的算法工程师。“工具视角”下的算法工程师,对于“工具”的使用熟练程度可能会比较高,但是可能会缺少业务感和目的感,缺少全栈化的能力和意愿;而“目的视角”下的算法工程师,与前者相反,有不错的业务感和目的感,大多数有不错的全栈化能力和意愿,但是对于“工具”的使用熟练程度未必那么高。
(PS:“目的视角”下的算法工程师的定义,引发了另外一个问题:假如说以“优化某可量化业务指标”为日常工作主要目的的工程师,是算法工程师,那么非算法岗位的其他开发工程师,是否就不关心或者说不能优化业务指标了呢?答案当然是否定的,本文就不详细展开讨论了。)
2、 电商算法
阿里的算法工程师有很大一部分是服务于电商业务的,说说我对于“电商算法”的理解:
我们认为,电商算法的主要工作,都围绕着“分配(Allocation)”二字展开,要么是“分配”本身,比如对于外投营销预算、销售佣金、广告主的P4P预算和运营红包的分配、对于销售、拍档和运营的时间精力的分配、对于买家的注意力(商机)的分配;要么就是为了更好地“分配”而做的基建或准备工作,比如对电商核心要素的数据标准化、对于视频和直播等内容更深入的理解、对于分配过程中作弊行为的识别和打击。
根据资源“分配”过程本身市场化程度的高低、分配过程中人为主观因素的重要程度、被分配资源的规模量级、分配所造成的业务影响的即时性、分配对于实时性的要求,演化出了对算法团队不同的要求:
- 从以市场经济为主体,算法以中立(neutral)身份参与分配过程的方式到以宏观调控为主体,算法主动干预分配过程的方式。
- 从组合和最优化类的算法问题到机器学习类的算法问题。
- 从以模型预测精准度为目标的有监督学习任务到以长期和全局的收益(reward)最大化为目标的强化学习任务。
- 从基于强可解释性要求的树模型算法到基于弱可解释性的深度神经网络模型算法。
- 从离线的算法建模工作到提供在线实时化的算法产品化的服务。
- 从单目标优化的算法问题到多目标带约束优化的算法问题。
丰富多彩的应用场景,孕育了各种各样的问题定义,不同的问题定义又催生出了不同的算法方案以及对于算法同学能力的不同要求。
效率和公平是衡量“分配”是否是“好分配”的两个重要维度,通常来说,在分配效率还很低的时候,算法的关注点与优化的重点都在效率提升方面,对于“公平”还不会考虑太多,而一旦效率提升到接近天花板的水平之后,“公平”问题开始浮出水面,应该引起算法更多的重视。如何量化“效率和公平(尤其是公平)”不仅仅是算法问题,更涉及到道德伦理、经济学、博弈论、数据科学等交叉学科,可以说是电商算法领域最复杂最核心的问题,甚至受到了人民日报[2]的关注。
3、 ICBU算法
先从一张所谓的“算法大图”开始:
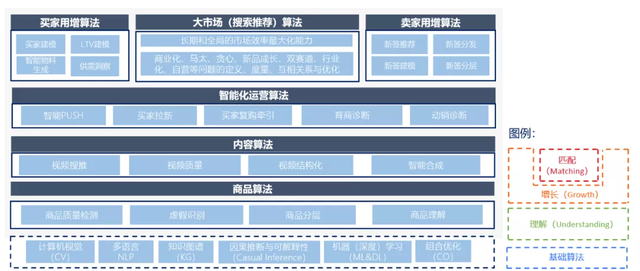
ICBU算法团队,隶属于ICBU技术部,服务于ICBU业务。它的整体工作,从上面算法大图的视角来看,可以分为3大部分:理解(Understanding)、增长(Growth)和匹配(Matching),它们也分别对应了Market Place的“货、人、场”三个部分:
理解(Understanding)
指的是基于计算机视觉(CV)、自然语言处理(NLP)、深度学习(Deep Learning)、数据标准化(Data Standardization)和知识图谱(Knowledge Graph)等基础算法能力,打造整个业务的数字化基建底盘,提升我们对于商品(货)、内容(短视频和直播)、买卖家、行业趋势、市场供需等方面的理解,提升商品、内容和商家的数字化程度,并基于这些理解去赋能增长和匹配的环节,降本增效。
增长(Growth)
指的是在固定资源成本约束下,通过算法对于资源的最优化分配,来实现电商业务核心要素的买卖家(人)最大化增长,根据所分配资源的不同,可以分成三个方面:
- 第一方面(狭义理解的)买家增长,主要是基于组合优化、趋势发现(forecasting)、最优化(Optimization)、对抗智能等基础算法能力,来最优化分配外投的市场预算,实现固定预算的情况下的业务价值(LTV/AB)最大化。
- 第二方面,卖家增长,主要是基于数据驱动、机器学习、统计建模、因果推断(Casual Inference)等基础算法能力,来最优化分配销售和拍档的时间与精力,实现有限销售和拍档规模的情况下,新签、续签的会员费营收最大化。
- 第三方面,智能运营,基于算法赋能,最优化分配运营的精力、买卖家运营红包和免服务费等运营权益,实现支付买家数、订单数、GMV和供应链营收的最大化。
匹配(Matching)
指的是在包括搜索、推荐和广告在内的大市场,完成买卖家的高效撮合匹配。主要是基于机器学习、最优化和E&E等基础算法能力,在最大化市场长期和全局的匹配效率,追求有效商机极大产出(AB/Pay/GMV)的同时,实现商机在自然品和广告品之间的合理分配(商业化问题)、商机在首次商机和往复商机之间的合理分配(贪心问题)、商机在头部商家和尾部商家之间的合理分配(马太问题)、商机在新品和爆品之间的合理分配(新品成长问题)、商机在RTS品和询盘品之间的合理分配(双赛道问题)、商机在CGS和GGS商家之间的合理分配(GGS问题)、商机在各个行业之间的合理分配(行业化问题)、算法需要回答如何定义和度量(Define & Measure)上述7个“合理”,它们之间的关系,以及如何优化它们。
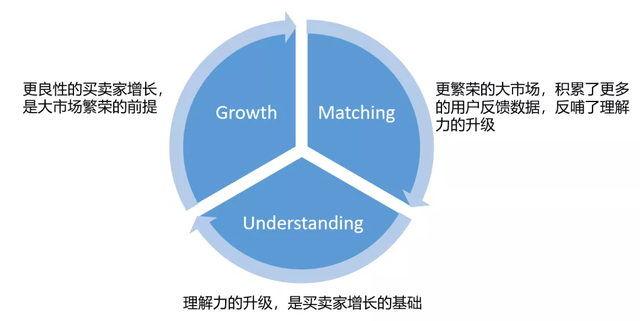
如上图所示,理解、增长和匹配,形成了一个:理解->增长->匹配->增长……的飞轮,带动整个ICBU业务的数字智能化的进程。
二 、2020年ICBU算法工作总结
接下来分别向大家分享一下“理解”、“增长”和“匹配”三个领域的重要技术成果(以下内容引用自ICBU算法团队相关文章)。
1、 理解(Understanding)
场景底料挖掘
Alibaba.com国际站中,场景导购在首页中占据着非常重要的地位,但长期起来并没有体系化的场景生成方案,基本依靠人工经验来完成场景的构建,而且B类采购的专业性、跨境贸易的文化多样性、国际环境的不确定性更为有效的导购场景设置了天然的障碍。因此我们针对B类采购的需求,构建了B类场景生成方案,包含了2大特色:
- 基于cpv的细分市场生成。
- 模拟用户组合采购的事件场景生成。
在网站App首页、搜索推荐、云主题等场景应用,在过去一年里,算法对场景内容的丰富和优化,为网站带来了AB和支付买家数提升的业务价值。
智能发品
ICBU作为承接全球B类买家寻源的重要电商平台之一,一直致力于帮助来自国内的供应商(CGS)和海外供应商(GGS)发布优质的商品信息。商品表达的丰富度和确定性一直是影响买家询盘,交易转化的重要因素。为了解决很多商家缺乏运营能力、表达能力弱、重要属性不填或者滥填、不知道该怎么填写合理的商品标题等问题,算法建立标题属性自动生成工具,其中提出了两大创新点:
- finetuning预训练文本生成模型BART,构建了文本生成模型。
- 结合ICBU流量特性,将生成语料更符合B类电商检索和阅读。
项目上线实验效果为,在商品信息丰富度上整体约提升6%,算法推荐标题内容采纳率CGS约32%,GGS约42%,实验对比发现通过智能发布的商品在曝光效果提高约40%。
电商场景下的细粒度图像分类
商品图像是商品信息展示最重要的组成部分之一,网站图像质量经过商品信息治理后已有很大提升,但仍缺乏对图像内容的识别和理解能力。同时,B类商品标准化需要结合图像标签能力进行商品信息扩展和校验,输出商品结构化表达。我们针对网站需求构建的图像标签服务具有以下特色:
- 细粒度图像分类模型。为提高对相似商品识别的区分能力,提出一种基于主体分割和图关系网络的图像标签识别方法,扩大图像标签的精准度和召回率。
- 沉淀了B类特色图像标签体系,基于CPV品类体系抽象出外观有显著区分度的品类以及属性作为图像标签输出能力,标签体系已覆盖交易TOP15行业,数千个品类标签。
该项目会应用于搜索相关性提升和商品内容理解,沉淀的技术创新《Object Decoupling with Graph Correlation for Fine-Grained Image Classification》已投稿于ICME2021会议。
视频检测、分析、创意
在视频创意外投承接项目中,我们基于对视频智能创作流程的理解,设计出了一套基于优质视频进行视频合成的方法,提出视频智能裁切等创新点,解决了视频智能多尺寸、视频素材优选、视频创意美化的难题,克服了目前网站视频素材质量参差不齐、海外平台本地化的挑战。该项目上线后,共生成视频创意若干个,为ICBU业务节省了若干的创意成本;该项目在取得业务价值的同时,所沉淀的技术创新能力也得到了业界的认可,该技术目前已经应用开源。
2、 增长(Growth)
外投预算分配
在智能预算分配1.0项目中,我们基于站内外付费流量数据的深刻洞察,提出了基于分层强化学习的智能预算分配方案,包含了3大创新点:
- 设计了预估器-求解器架构求解整体预算分配问题。
- 使用站内外渠道/国家等特征对付费渠道进行回归预估,构建模型学习环境。
- 设计了基于分层强化学习的算法求解器,高效求解预算分配问题。
通过分层强化学习等创新设计,有效克服了预算分配与强化学习领域中的稀疏奖赏与延迟奖赏问题,增加求解精度与效率。项目上线后,为付费PPC渠道cpab降低10.3%,该项目还形成了核心创新方案《基于自注意力机制的强化学习预算分配解决方案》和《基于分布式神经进化算法的多目标预算分配模型优化方案》。
horae精排
在horae 1.0项目中,我们基于对付费流量特性的深刻洞察,在付费流量场景从0开始搭建整套召回+排序体系,提出3大创新点:
- 基于站外曝光品的用户行为采集。
- 充分使用站外渠道/国家特征。
- 基于核心属性的交叉特征构建。
对付费流量进行单独建模,解决了付费流量与站内流量在分布上存在巨大差异的领域难题。同时克服了付费流量样本较少的问题,context特征大量采用站外特征,而商品特征大量采用全站统计特征,充分利用站内数据进行辅助学习。项目上线后,为ICBU展示广告业务带来了App端AB rate提升13.6%,Wap端AB rate 提升3%。
供需匹配构建
在先知(红蓝海)项目中,我们基于对买卖家数据的深刻洞察,设计出了用来度量人货匹配和供给选择的量化指标,提出了蓝海度、竞争力、丰富度三维指数, 带来了从销售驱动的供给升级为基于行业路径和买家需求的定招培育新引擎。该项目上线后,平均签单周期缩短8%,发MC15提升44%,品效是大盘2倍之多。该项目在取得业务价值的同时,也取得了技术创新,各指数综合了站内数百特征的同时,结合利用基于时序TRMF预测的未来趋势和周期性走势。
买家意愿订单确认
在Stellar项目中,我们基于卖家待确认PO单数量较大导致订单无法及时确认,影响O-P转化的业务痛点,提出基于买家质量、卖家接单偏好及订单质量等维度,基于树模型实时预测优质PO单,并解决了数据质量提升、样本不均衡、id特征及长尾类别特征等技术难题,缓解了O-P链路环节中卖家确认率低的业务难题。该项目上线后,PO单确认率提升7pt,O-P转化+1.2%。
TAO商家智能运营
在TAO拉新项目中,我们发现在供应链运营场景,拍档的人力是有限的,但是客户规模不断在增长,如何在有限的人力情况下提升拍档的人效,我们提出通过大数据的学习及模型可解释能力,预测潜客分层及千人千面诊断&Action,为拍档提供傻瓜式的行动指引,项目中使用SHAP、子模型等可解释技术方案,并将算法解释转换为可执行的Action。该项目上线后,为ICBU业务带来了,TAO拉新转化率+8.46%,累计贡献GMV提升的业务价值。
物流费用精准预测
在尼斯湖双十二买家物流五折项目中,我们发现传统的营销运营是广撒网式的做法,由于与自然转化客群有较大的交集会造成较多的预算浪费,因此我们首先通过对具备采购需求严肃买家支付卡点的分析洞察,进而提出在营销预算有限的情况下,通过算法精准预测物流费用敏感的支付增量人群的创新点。该项目上线后,为ICBU业务带来了月均支付增量买家数提升,和ROI提升的业务价值。
3、匹配(Matching)
动态网络表征学习
在DyHAN(动态图向量检索)项目中,我们发现买家在寻源过程中在不断尝试寻找更有效的供应商,导致买卖家形成的关系图随着时间推移在不断演进。而之前基于静态图的模型无法捕捉这种变化,因此我们提出了基于动态图的表征学习方法,解决了电商表征建模领域节点信息不断演进带来的问题。该项目在ICBU商品详情页跨店推荐上线后,核心的询盘转化率提升3.54%,创建订单转化率提升14.23%;该项目在取得业务价值的同时,所沉淀的技术创新也得到了业界认可,沉淀的《Dynamic Heterogeneous Graph Embedding using Hierarchical Attentions》和《Modeling Dynamic Heterogeneous Network for Link Prediction using Hierarchical Attention with Temporal RNN》论文,分别被ECIR2020和ECML-PKDD2020会议收录 。
深度多兴趣网络
在DMIN(深度多兴趣排序建模)项目中,我们基于ICBU买家特点,发现部分零售商和采购商,其采购商品往往横跨多个类目,且在多个类目的偏好程度随时间出现变化。我们基于DIN模型,提出多层次的多兴趣抽取网络模型,提升了模型动态建模买家多兴趣的精准性。该项目在ICBU推送推荐场景上线后,曝光点击率提升10.4%,买家订单转化率提升13%;该项目在取得业务价值的同时,所沉淀的技术创新也得到了业界认可,沉淀的《Deep Multi-Interest Network for Click-through Rate Prediction》论文,被CIKM’20会议收录。
向量召回
跨境B类搜索场景下用户搜索词更加多样化、表达更加专业化,基于传统的关键字召回技术零少问题很严重,搜索长尾流量占比将近30%。从2018年开始,ICBU搜索就开始着手探索向量召回技术,用空间向量距离来进行相似度估计,从语义层面进行最相关(距离最近)产品的召回。今年ICBU搜索首次尝试利用BERT模型结构,自研FashionBERT做到更细粒度的多模态匹配,目前已经基本解决ICBU搜索的零少问题。
在项目中,我们将商品图像用于召回,即将Query和item image的对应关系转化为图文匹配。我们提出FashionBERT图文匹配模型,直接将图像split相同大小的Patch,然后将Patch作为图像的token,和文本进行拟合。同时增加wordpiece来解决oov问题,query graph attention(GAT)来增加长尾Query的泛化能力。我们在电商领域FashionGen数据集,对比了主流图文匹配技术,FashionBERT取得非常明显的提升,目前论文《FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval》已被SIGIR2020 Industry Track接收。
语义搜索
ICBU用户搜索词更加多样化表达更加专业化,召回和匹配一直是ICBU网站的搜索优化重点。2020年上半年我们完成了语义搜索1.0(向量召回3.0+语义匹配1.0)的升级,基本解决了相关性零少问题和缓解了关键字字面匹配局限问题,但是从通过人工达标分析case,发现当前链路依然存在Query理解不足-类目预测不准;核心词提取不准;关键相关性和语义相关性融合方式欠佳等三个问题;针对这些问题,我们融合三个子项目ICBU NER 1.0,类目预测2.0和相关性2.0(融合优化+NER调档)。进行联合优化,取得了非常不错的业务结果:高相关商品曝光占比提升6%,搜索相关性零少下降8%,点击提升+0.65%,询盘提升1.44%,支付转化提升6.30%。
类目预测
对于ICBU而言,类目预测算法的应用场景非常广泛。在搜索系统中,类目预测结果是商品相关性的重要判定标准,会直接影响搜索结果的召回和排序。对于搜索广告而言,类目预测也直接影响买家体验和广告主效果。因此我们针对ICBU类目预测算法中存在的核心问题进行了重点优化:
- 文本语义分类模型由fasttext升级到了BERT。
- 借助ICBU在NER技术上的沉淀,通过Query中关键NER属性词组召回相应类目。
类目预测算法优化取得了不错的效果:
- 离线评测指标:0档位top1类目准确率+5%, 0档位整体类目准确率+2.4%,0档位类目召回提升了12.0%。
- 打包语义搜索项目整体,搜索业务指标影响:PC端 L-D +0.65%,L-AB +1.44%,L-P +6.30% ;APP端 L-D +0.69%,L-AB +1.93%,L-P +1.96%。
- 对于广告业务指标影响:预算分桶下pv2f +2%,rpm+1%,badcase降低3.4%。
跨语言向量召回
我们利用全新的跨语言向量召回技术,跨越Query翻译的障碍,极大丰富搜索召回结果,促进转化效率的提升。该创新技术通过基于大规模平行数据的跨语言预训练模型EcomLM,解决不同语言难以映射到同一语义空间的难题。结合商业表征以及用户行为信息的间接交互模型,克服了传统双塔模型信息隔离的问题。实验结果表明,通过跨语言向量召回,搜索零少结果率下降至1%以下,V1.0版本多语言整体L-AB +1.34%,L-P +4.2%。此外,我们在语种识别、Query翻译、多语言语义相关性模型等模块也有一定的技术积累,旨在打造一套完整的跨语言搜索解决方案。
结构化理解
ICBU作为国际B类跨境贸易的战场,在当前网站的关键词相关性部分仍存在这个一些问题,例如匹配准度不够、中心词提取错误、类目预测准确率低。以中心词提取模块为例,在关键词匹配的错误中,中心词提取错误占了40%,不仅如此,中心词提取也缺乏提取Query或title中关键属性的能力,例如用户搜索商品时指定的颜色、规格等,这些都是中心词提取模块所欠缺的,因此从国际站搜索的角度来看,迫切需要NER工具来提升目前的关键词匹配准确行。
首先,我们通过与达摩院多语言NLP基础团队的合作将NER直接用于搜索匹配中,通过NER来对Query与商品之间实现属性匹配,基于NER模型的属性匹配,不仅解决了中心词提取模块准确率低的问题,同时也能够通过对其Query与offfer中的相同属性,从而给予用户更加精准的搜索体验。另一方面,NER也赋能ICBU中的其他业务,如类目预测等、新属性发现、CPV属性扩充等,在新的季度,我们也会将NER搜索算法的各个方面,如深度语义匹配,个性化召回等。
三 、一些思考
1 、数据与算法
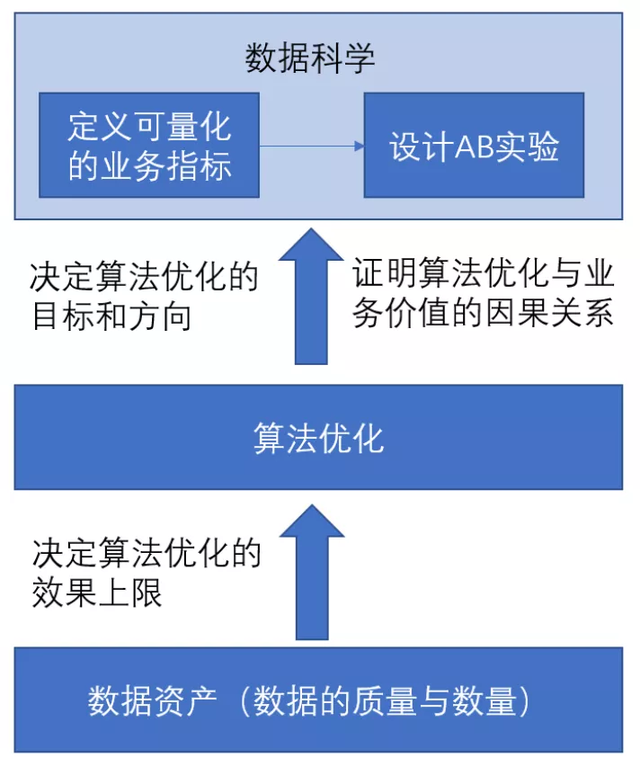
对于业务技术团队而言,数据,可以从两个方面去理解它:
- 数据科学(业务指标和因果推断)——用来回答“算法要去向何方以及如何判断算法做的事情是否成功”的一个可量化的标准。
- 数据资产——买卖家的行为和整个业务连路上沉淀下的所有数据资产。
数据资产和算法的关系可以理解为:数据资产是燃料,算法是引擎,引擎的输出取决于燃料的质量和数量。或者说,数据资产是底层的基础,算法是上层的应用,算法离开了数据资产的养分,就是无源之水无本之木。
数据科学和算法的关系可以理解为:数据科学是确定方向和目标、定义问题、指路明灯,是立靶子。而算法做的事情是在定了方向和目标之后,如何高效率地去标准靶子,去高效率地追逐目标。
结合这两个角度来看,算法和数据,密不可分,数据科学为算法定义了问题和目标方向,而数据资产又为算法提供了燃料,供算法充分挖掘并使得算法有机会去逼近数据科学指定的目标,并高效地解决数据科学所提出的问题。
2、 目标的重要性
前面刚刚说到了“数据科学为算法定义了问题和目标方向”,下面我聊聊“目标”这个话题,我拿一个真实的故事举个例子:《印尼悬赏除鼠患遭质疑:有人为领奖会养老鼠》[1]。
上面真实故事里面,初衷是好的,以OKR来举例的话,O(目标)可能是“创建卫生城市,消灭鼠患”。KR的话,有可能是:“通过科学灭鼠的方式,(消灭1000w只老鼠)收集到1000w条的老鼠尾巴。”
消灭鼠患,当然要杀死老鼠;杀死老鼠越多,鼠患消除的越彻底;而杀死老鼠越多,老鼠尾巴就应该会越多——所以我们拿“老鼠尾巴”的个数,来作为一个可量化指标来度量“消灭鼠患”这个目标完成的怎么样,似乎是一个合理的选择?问题在于落地和执行,在这个“老鼠尾巴”这个量化指标的激励下,人们在执行时,会走偏,会发生“养老鼠”这样奇葩的事情。
一个目标,对于一个业务的成败来说,其重要性,无论多么强调都不为过。
3 、对于未来AB的优化
我们B类跨境外贸在大市场(搜索推荐)算法领域的特点是什么?传统偏C类电商的搜索推荐场景下,买家的转化行为周期比较短,这个转化的目标是一个离散的目标:可以是强转化(成交),也可以是弱转化(加购、收藏、关注),但无论是强弱转化目标,算法建模的目标的都是一个离散的、脉冲式的单点的短期转化行为的概率,算法优化的目标也同样是这个离散的、脉冲式的单点的短期转化行为的数学期望的最大化。
而我们B类的跨境贸易电商场景下,一个B类买家的转化行为周期很长,这个转化的目标,不应该是一个离散的目标——比如当天是否会发生AB行为,而应该是一个连续化的目标:一个买家在未来的每一天里会发生AB的行为的概率,我们需要对这个AB在他整个生意周期当中,会留存在ICBU的概率进行连续化地建模和连续化地优化。如果说C类电商搜索推荐场景下,C类买家的整个转化行为周期比较短,因此建模和优化的目标本身应该也比较短的,是一个突兀的脉冲点的话,那么我们B类电商搜索推荐建模和优化的目标应该是一段持续稳健上升的曲线。也许是我们B类跨境贸易算法需要优化和建模的重要特点,值得我们思考。
当下的优化
简单的说,当下的优化,算法的目标是去最大化每一次曝光机会转化为一个AB行为的概率,因此算法真正需要去建模的,就是下面这个概率:

对于当下优化的反思与拆解
我们对当下的搜索推荐的算法优化的反思主要来自两个方面:

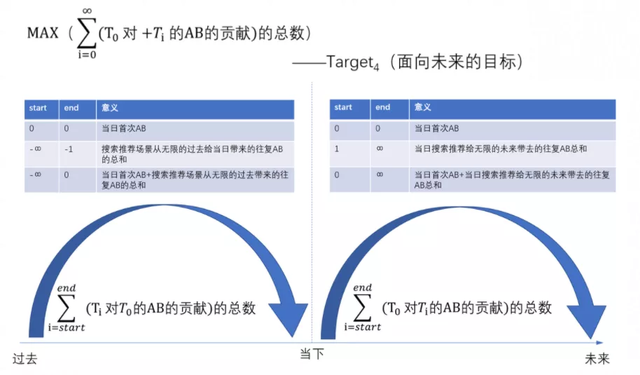
让我们再仔细回顾一下我们真正想要的Tartet 0(原目标),并对它进行一个细致的拆解:

如上图所示,我们有几个思考:
- 首先,“日均AB”可以拆解为首次AB(AB Today)+往复AB(AB Past)。
- 我们假设——在搜索推荐当下的算法策略,会影响到未来的往复AB,基于这个假设,可以将这里的往复AB,继续拆解,成一个无穷级数,从昨天(-T1)开始,一直回溯到无穷远(-T∞)的过去,然后累加,当然越久远的过去对当下的影响会越弱。
过去与未来的置换
过去的曝光我们已经无法优化了,但是未来对于我们有意义的,因此我们把经过拆解的Target 0里面的AB Past(往复AB)里面的“过去”的概念,替换为“未来”,从新生成一个值:AB Future,它度量的是当天由搜索推荐分发的所有商机对于未来贡献的往复AB的总和的一个期望。

同时基于AB Future我们提出了一个新的优化目标:Target 4

而当i=0的时候,T0对于T0的AB贡献,就是首次AB的定义,因此可以将上面的目标简写成如下的格式,i从0开始。
四 、展望
接下来,我们的几个重点包括:智能化运营&买卖家增长之间的更多联动、内容化、搜推大市场的优化目标新定义、E&E马太问题&在监管之下的调控等。接下来的一年,将是算法团队再起飞的一年,算法团队将更聚焦、做更少的事(但需要更多的人),每做一件事都做深做透,不求每件事都成功,但求每件事都有收获,无论是业务上的、技术上的,还是经验教训上的,并争取交出算法团队自身的代表作。
作者:开发者小助手_LS
本文为阿里云原创内容,未经允许不得转载