分析core不是一件容易的事情。试想,一个系统运行了很长一段时间,在这段时间里,系统会积累大量正常、甚至不正常的状态。这个时候如果系统突然出现了一个问题,那这个问题十有八九跟长时间积累下来的状态有关系。分析core,就是分析出问题时,系统产生的“快照”,追溯历史,找出问题发生源头。这有点像是从案发现场,推导案发经过一样。
soft lockup!
今天这个“案件”,我们从soft lockup说起。
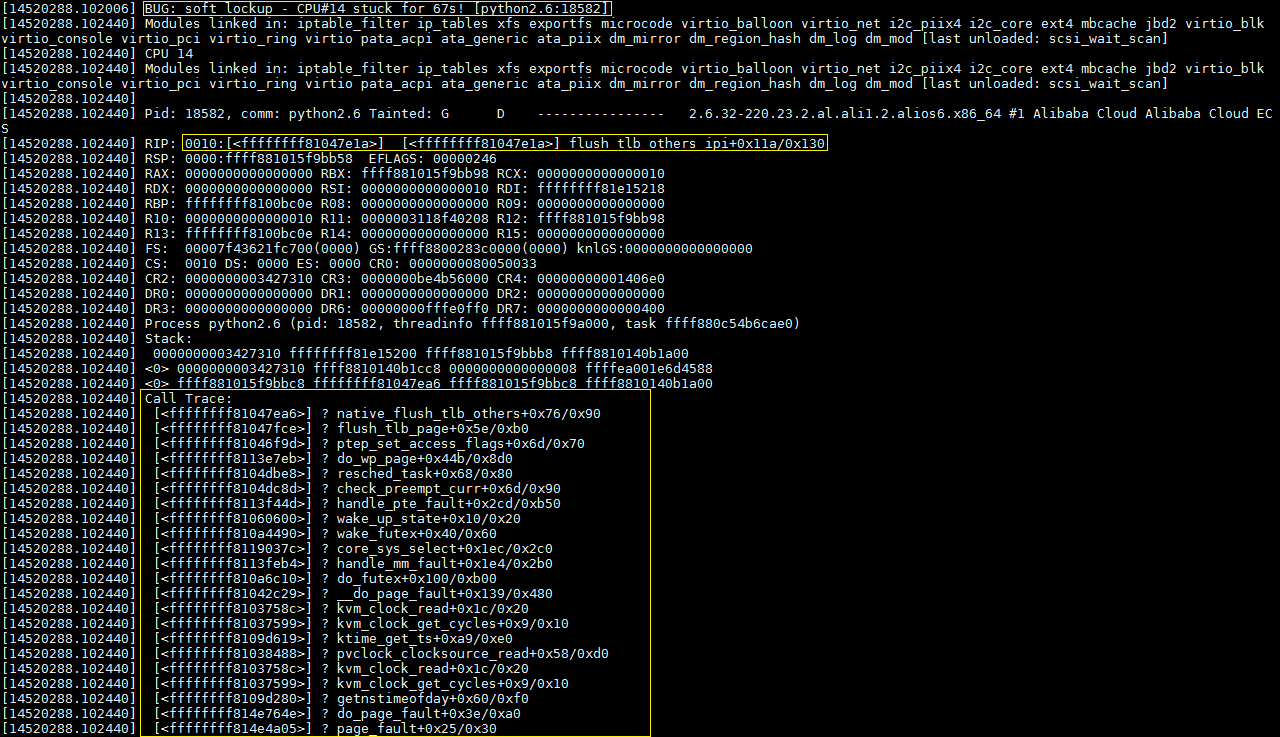
soft lockup是内核实现的夯机自我诊断功能。这个功能的实现,和线程的优先级有关系。
这里我们假设有三个线程A、B、和C。他们的优先级关系是A<B<C。这意味着C优先于B执行,B优先于A执行。这个优先级关系,如果倒过来叙述,就会产生一个规则:如果C不能执行,那么B也没有办法执行,如果B不能执行,那基本上A也没法执行。
soft lockup实际上就是对这个规则的实现:soft lockup使用一个内核定时器(C线程),周期性地检查,watchdog(B线程)有没有正常运行。如果没有,那就意味着普通线程(A线程)也没有办法正常运行。这时内核定时器(C线程)会输出类似上图中的soft lockup记录,来告诉用户,卡在cpu上的,有问题的线程的信息。
具体到这个“案件”,卡在cpu上的线程是python,这个线程正在刷新tlb缓存。
老搭档ipi和tlb
如果我们对所有夯机问题的调用栈做一个统计的话,我们肯定会发现,tlb和ipi是一对形影不离的老搭档。其实这不是偶然的。系统中,相对于内存,tlb是处理器本地的cache。这样的共享内存和本地cache的架构,必然会提出一致性的要求。如果每个处理器的tlb“各自为政”的话,那系统肯定会乱套。满足tlb一致性的要求,本质上来说只需要一种操作,就是刷新本地tlb的同时,同步地刷新其他处理器的tlb。系统正是靠tlb和ipi这对老搭档的完美配合来完成这个操作的。
这个操作本身的代价是比较大的。一方面,为了避免产生竞争,线程在刷新本地tlb的时候,会停掉抢占。这就导致一个结果:其他的线程,当然包括watchdog线程,没有办法被调度执行(soft lockup)。另外一方面,为了要求其他cpu同步地刷新tlb,当前线程会使用ipi和其他cpu同步进展,直到其他cpu也完成刷新为止。其他cpu如果迟迟不配合,那么当前线程就会死等。
不配合的cpu
为什么其他cpu不配合去刷新tlb呢?理论上来说,ipi是中断,中断的优先级是很高的。如果有cpu不配合去刷新tlb,基本上有两种可能:一种是这个cpu刷新了tlb,但是做到一半也卡住了;另外一种是,它根本没有办法响应ipi中断。
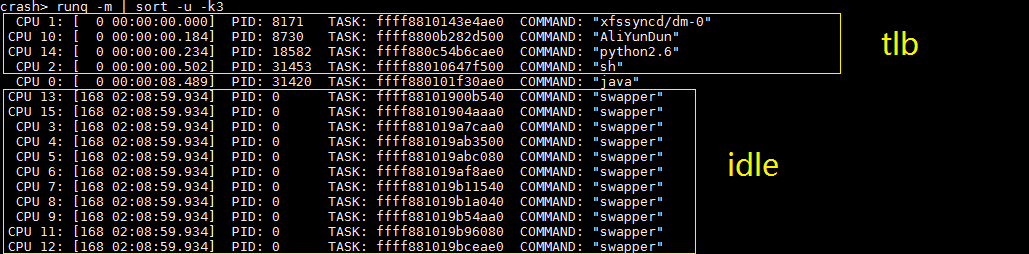
通过查看系统中所有占用cpu的线程,可以看到cpu基本上在做三件事情:idle,正在刷新tlb,和正在运行java程序。其中idle的cpu,肯定能在需要的时候,响应ipi并刷新tlb。而正在刷新tlb的cpu,因为停掉了抢占,且在等待其他cpu完成tlb刷新,所以在重复输出soft lockup记录。这里问题的关键,是运行java的cpu,这个我们在下一节讲。
java不是问题,踩到的坑才是问题
java线程运行在0号cpu上,这个线程的调用栈,满满的都是故事。我们可以简单地把线程调用栈分为上下两部分。下边的是system call调用栈,是java从系统调用进入内核的执行记录。上边的是中断栈,java在执行系统调用的时候,正好有一个中断进来,所以这个cpu临时去处理了中断。在linux内核中,中断和系统调用使用的是不同的内核栈,所以我们可以看到第二列,上下两部分地址是不连续的。
netoops持有等待
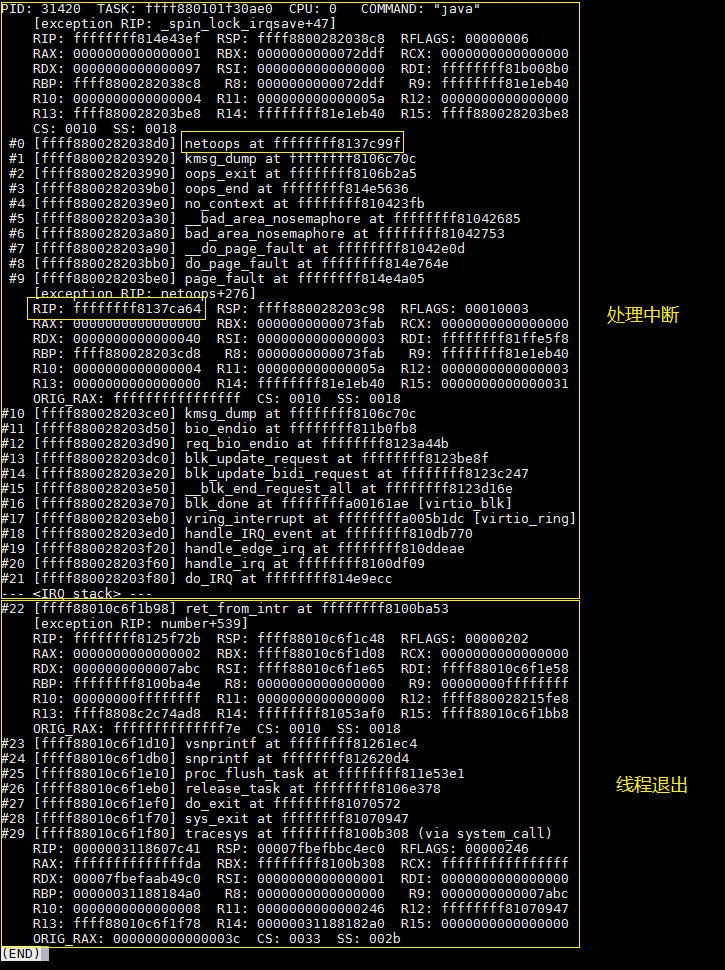
分析中断处理这部分调用栈,从下往上,我们首先会发现,netoops函数触发了缺页异常。缺页异常其实就是给系统一个机会,把指令踩到的虚拟地址,和真正想要访问的物理机之间的映射关系给建立起来。但是有些虚拟地址,这种映射根本就是不存在的,这些地址就是非法地址(坑)。如果指令踩到这样的地址,会有两种后果,segment fault(进程)和oops(内核)。
很显然netoops踩到了非法地址,使得系统进入了oops逻辑。系统进入oops逻辑,做的第一件事情就是禁用中断。这个非常好理解。oops逻辑要做的事情是保存现场,它当然不希望,中断在这个时候破坏问题现场。
接下来,为了保存现场的需要,netoops再一次被调用,然后这个函数在几条指令之后,等在了spinlock上。要拿到这个spinlock,netoops必须要等它当前的owner线程释放它。这个spinlock的owner是谁呢?其实就是当前线程。换句话说,netoops拿了spinlock,回过头来又去要这个spinlock,导致当前线程死锁了自己。
验证上边的结论,我们当然可以去读代码。但是有另外一个技巧。我们可以看到netoops函数在踩到非法地址的时候,指令rip地址是ffffffff8137ca64,而在尝试拿spinlock的时候,rip是ffffffff8137c99f。很显然拿spinlock在踩到非法地址之前。虽然代码里的跳转指令,让这种判断不是那么的准确,但是大部分情况下,这个技巧是很有用的。
缺页异常,错误的时间,错误的地点
这个线程进入死锁的根本原因是,缺页异常在错误的时间发生在了错误的地点。对netoops函数的汇编和源代码进行分析,我们会发现,缺页发生在ffffffff8137ca64这条指令,而这条指令是inline函数utsname的指令。下图中框出来的四条指令,就是编译后的utsname函数。
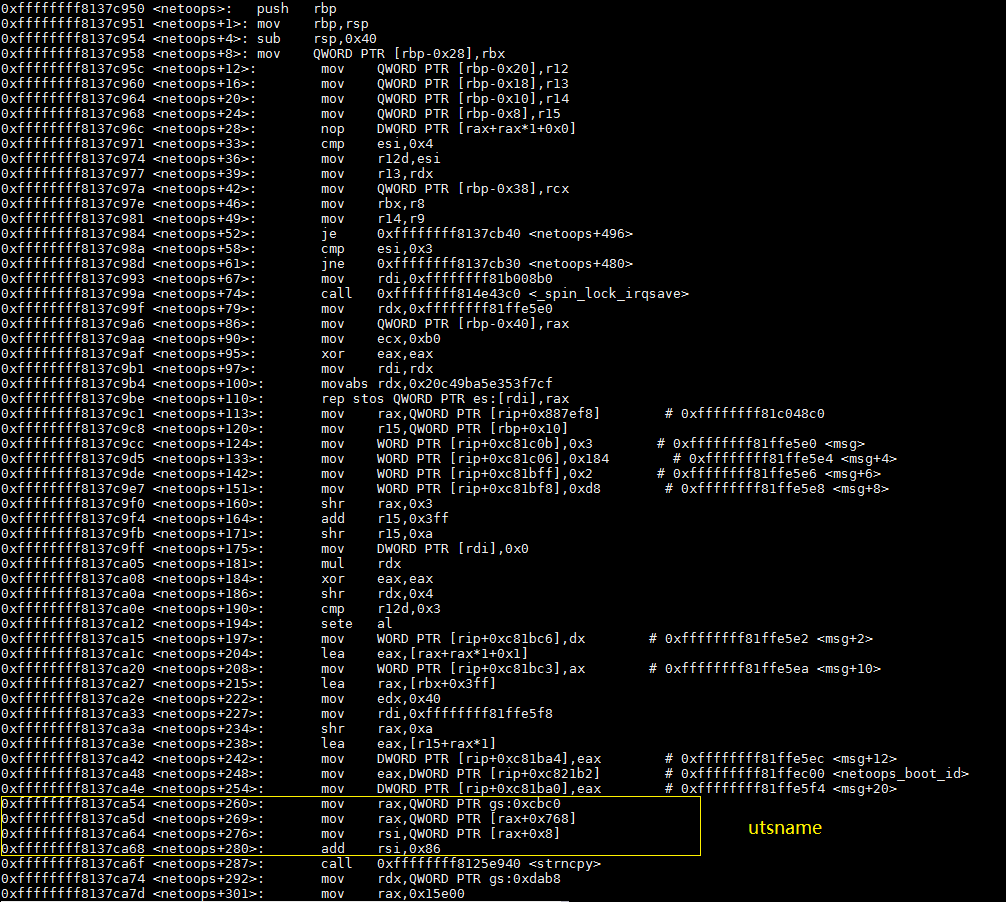
而utsname函数的源代码其实就一行。
return ¤t->nsproxy->uts_ns->name;
这行代码通过当前进程的task_struct指针current,访问了uts namespace相关的内容。这一行代码,之所以会编译成截图中的四条汇编指令,是因为gs寄存器的0xcbc0项,保存的就是current指针。这四条汇编指令做的事情分别是,取current指针,读nsproxy项,读uts_ns项,以及计算name的地址。第三条指令踩到非法地址,是因为nsproxy这个值为空值。
空值nsproxy
我们可以在两个地方验证nsproxy为空这个结论。第一个地方是读取当前进程task_sturct的nsproxy项。另外一个是看缺页异常的时候,保存下来的rax寄存器的值。保存下来的rax寄存器值可以在图三中看到,下边是从task_struct里读出来的nsproxy值。

正在退出的线程
那么,为什么当前进程task_struct这个结构的nsproxy这一项为空呢?我们可以回头看一下,java线程调用栈的下半部分内容。这部分调用栈实际上是在执行exit系统调用,也就是说进程正在退出。实际上参考代码,我们可以确定,这个进程已经处于僵尸(zombie)状态了。因而nsproxy相关的资源,已经被释放了。
namespace访问规则
最后我们简单看一下nsproxy的访问规则。规则一共有三条,netoops踩到空指针的原因,某种意义上来说,是因为它间接地违背了第三条规则。netoops通过utsname访问进程的namespace,因为它在中断上下文,所以并不算是访问当前的进程,也就是说它应该查空。另外我加亮的部分,进一步佐证了上一小节的结论。
/** the namespaces access rules are:** 1. only current task is allowed to change tsk->nsproxy pointer or* any pointer on the nsproxy itself** 2. when accessing (i.e. reading) current task's namespaces - no* precautions should be taken - just dereference the pointers** 3. the access to other task namespaces is performed like this* rcu_read_lock();* nsproxy = task_nsproxy(tsk);* if (nsproxy != NULL) {* / ** * work with the namespaces here* * e.g. get the reference on one of them* * /* } / ** * NULL task_nsproxy() means that this task is* * almost dead (zombie)* * /* rcu_read_unlock();**/
回顾
最后我们复原一下案发经过。开始的时候,是java进程退出。java退出需要完成很多步骤。当它马上就要完成自己使命的时候,一个中断打断了它。这个中断做了一系列的动作,之后调用了netoops函数。netoops函数拿了一个锁,然后回头去访问java的一个被释放掉的资源,这触发了一个缺页。因为访问的是非法地址,所以这个缺页导致了oops。oops过程禁用了中断,然后调用netoops函数,netoops需要再次拿锁,但是这个锁已经被自己拿了,这是典型的死锁。再后来其他cpu尝试同步刷新tlb,因为java进程关闭了中断而且死锁了,它根本收不到其他cpu发来的ipi消息,所以其他cpu只能不断的报告soft lockup错误。
原文链接
本文为云栖社区原创内容,未经允许不得转载。