numba
编译型语言和解释型语言
首先了解一下编译型语言和解释型语言(也经常叫脚本语言):
1、编译型语言,C、C++、Fortran、Pascal、Ada,由编译型语言编写的源程序需要经过编译,汇编和链接才能输出目标代码,然后由机器执行目标代码。目标代码是由机器指令组成,不能独立运行,因为源程序中可能使用了一些汇编程序不能解释引用的库函数,而库函数又不在源程序中,此时还需要链接程序完成外部引用和目标模板调用的链接任务,最后才能输出可执行代码。(例如我们编写c的时候引用了一个自定义的c库函数,则需要进行链接操作)
2、解释型语言(典型的python),解释器不产生目标机器代码,而是产生中间代码,这种中间代码与机器代码不同,中间代码的解释是由软件支持的,不能直接使用在硬件上。该软件解释器通常会导致执行效率较低,用解释型语言编写的程序是由另一个可以理解中间代码的解释程序(例如python虚拟器)执行的。和编译的程序不同的是, 解释程序的任务是逐一将源代码的语句解释成可执行的机器指令,不需要将源程序翻译成目标代码再执行。对于解释型语言,需要一个专门的解释器来执行该程序,每条语句只有在执行是才能被翻译,这种解释型语言每执行一次就翻译一次,因而效率低下;
( 对于python解释语言,有以下3方面的特性:
每次运行都要进行转换成字节码,然后再有虚拟机把字节码转换成机器语言,最后才能在硬件上运行。与编译性语言相比,每次多出了编译和链接的过程,性能肯定会受到影响;而python并不是每次都需要转换字节码,解释器在转换之前会判断代码文件的修改时间是否与上一次转换后的字节码pyc文件的修改时间一致,若不一致才会重新转换。
由于不用关心程序的编译和库的链接等问题,开发的工作也就更加轻松啦。
python代码与机器底层更远了,python程序更加易于移植,基本上无需改动就能在多平台上运行。)
Java解释器,java很特殊,java是需要编译的,但是没有直接编译成机器语言,而是编译成字节码,然后在Java虚拟机上用解释的方式执行字节码。Python也使用了类似的方式,先将python编译成python字节码,然后由一个专门的python字节码解释器负责解释执行字节码。
我们常见的cpython解释器是用c语言的方式来解释字节码的,而numba则是使用LLVM编译技术来解释字节码的。
例子
# -*- coding: utf-8 -*-#
# -------------------------------------------------------------------------------
# Name: numba测试
# Author: yunhgu
# Date: 2022/3/10 9:56
# Description:
# -------------------------------------------------------------------------------
from time import time
from numba import jit
import numpy as np
x = np.arange(100000, dtype=np.int32)
@jit(nopython=True)
def go_fast(a):
b = 0
for i in range(a.shape[0]):
b += i
return b
def go_fast2(a):
b = 0
for i in range(a.shape[0]):
b += i
return b
start = time()
print(go_fast(x))
print(time() - start)
start1 = time()
print(go_fast2(x))
print(time() - start1)
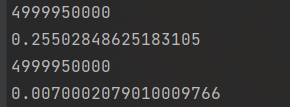
numba nopython mode 不支持numpy.int类型
Numba模式
Numba有两种模式:nopython和object。前者不使用Python运行时并生成没有Python依赖的本机代码。本机代码是静态类型的,运行速度非常快。而对象模式使用Python对象和Python C API,而这通常不会显着提高速度。在这两种情况下,Python代码都是使用LLVM编译的。
什么是LLVM?
LLVM是一个编译器,它采用代码的特殊中间表示(IR)并将其编译为本机(机器)代码。编译过程涉及许多额外的传递,其中LLVM编译器可以优化IR。LLVM工具链非常擅长优化IR,因此它不仅可以编译Numba的代码,还可以优化它。
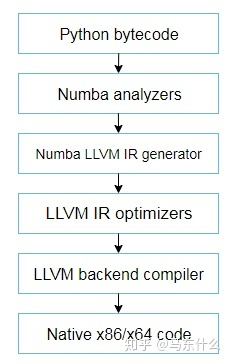
整个系统大致如下:
Numba的优点:
- 便于使用
- 自动并行化
- 支持numpy操作和对象
- 支持调用GPU
Numba的缺点: - debug非常麻烦
- 无法在nopython模式下与Python及其模块进行交互,numba目前在nopython模式下支持python模块有限,比如pandas是不支持的,但- 是不支持意味着无法加速并不意味着不能运行。
- 对python中的类class支持有限