cookie操作
爬取豆瓣个人主页
# -*- coding: utf-8 -*- import scrapy class DoubanSpider(scrapy.Spider): name = 'douban' #allowed_domains = ['www.douban.com'] start_urls = ['https://www.douban.com/accounts/login'] #重写start_requests方法 def start_requests(self): #将请求参数封装到字典 data = { 'source': 'index_nav', 'form_email': '15027900535', 'form_password': 'bobo@15027900535' } for url in self.start_urls: yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) #针对个人主页页面数据进行解析操作 def parseBySecondPage(self,response): fp = open('second.html', 'w', encoding='utf-8') fp.write(response.text) #可以对当前用户的个人主页页面数据进行指定解析操作 def parse(self, response): #登录成功后的页面数据进行存储 fp = open('main.html','w',encoding='utf-8') fp.write(response.text) #获取当前用户的个人主页 url = 'https://www.douban.com/people/185687620/' yield scrapy.Request(url=url,callback=self.parseBySecondPage)
因为要进行登录操作,所以一定要使用post请求进行表单提交,那么就必须重写start_requests()方法;观察代码就可以发现,当登录成功之后再次请求个人主页,不再需要
刻意地处理cookie,那是因为scrapy已经帮我们省去了这样的操作:第一次请求返回的cookie会在第二请求发送的时候被携带。
代理
import scrapy class ProxydemoSpider(scrapy.Spider): name = 'proxyDemo' #allowed_domains = ['www.baidu.com/s?wd=ip'] start_urls = ['https://www.baidu.com/s?wd=ip'] def parse(self, response): fp = open('proxy.html','w',encoding='utf-8') fp.write(response.text)
配置好配置文件,然后再执行,在proxy.html文件中就会看到本机ip的浏览器页面,ip就是真实的本机ip。
那如何更改ip呢?就用到了代理,在scrapy中使用代理操作需要对下载中间件下手。
那么什么是下载中间件呢?
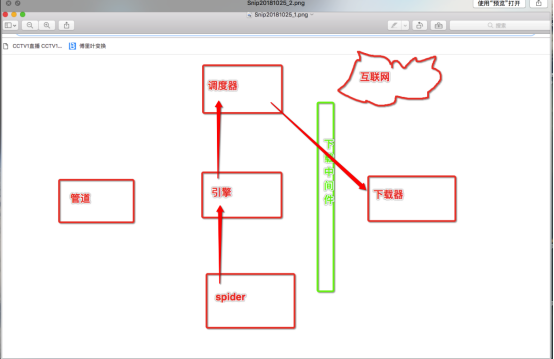
下载中间件的作用就是拦截请求,将请求的ip进行更换。
流程:
1. 下载中间件类的自制定
a) 继承object
b) 重写process_request(self,request,spider)的方法
2. 配置文件中进行下载中间价的开启。
middlewares.py 就是下载中间件的定义文件
from scrapy import signals #自定义一个下载中间件的类,在类中实现process_request(处理中间价拦截到的请求)方法 class MyProxy(object): def process_request(self,request,spider): #请求ip的更换 request.meta['proxy'] = "https://178.128.90.1:8080" # 这里需要一个有效的代理ip
开启下载中间件
# Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'proxyPro.middlewares.MyProxy': 543, # 数字大小代表优先级 }
再次执行,打开页面发现ip就被更改了!