一.HPA说明
HPA(Horizontal Pod Autoscaler)是kubernetes的一种资源对象,能够根据某些指标对在statefulset、replicacontroller、replicaset等集合中的pod数量进行动态伸缩,使运行在上面的服务对指标的变化有一定的自适应能力。
HPA目前支持四种类型的指标,分别是Resource、Object、External、Pods。其中在稳定版本autoscaling/v1只支持对CPU指标的动态伸缩,在测试版本autoscaling/v2beta2中支持memory和自定义指标的动态伸缩,并以annotation的方式工作在autoscaling/v1版本中。
注意:Pod的自动缩放不适用于无法缩放的对象。
HPA的API有三个版本:
[root@k8s001 ~]# kubectl api-versions | grep autoscal
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
- autoscaling/v1:只支持基于CPU指标的缩放。
- autoscaling/v2beta1:支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)的缩放。
- autoscaling/v2beta2:支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)和ExternalMetrics(额外指标)的缩放。
参考链接:https://v1-17.docs.kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/
二.度量指标详细说明
下面,基于具体的示例进行说明:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
# HPA的伸缩对象描述,HPA会动态修改该对象的pod数量
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
# HPA的最小pod数量和最大pod数量
minReplicas: 1
maxReplicas: 10
# 监控的指标数组,支持多种类型的指标共存
metrics:
# Object类型的指标
- type: Object
object:
metric:
# 指标名称
name: requests-per-second
# 监控指标的对象描述,指标数据来源于该对象
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
# Value类型的目标值,Object类型的指标只支持Value和AverageValue类型的目标值
target:
type: Value
value: 10k
# Resource类型的指标
- type: Resource
resource:
name: cpu
# Utilization类型的目标值,Resource类型的指标只支持Utilization和AverageValue类型的目标值
target:
type: Utilization
averageUtilization: 50
# Pods类型的指标
- type: Pods
pods:
metric:
name: packets-per-second
# AverageValue类型的目标值,Pods指标类型下只支持AverageValue类型的目标值
target:
type: AverageValue
averageValue: 1k
# External类型的指标
- type: External
external:
metric:
name: queue_messages_ready
# 该字段与第三方的指标标签相关联
selector:
matchLabels:
env: "stage"
app: "myapp"
# External指标类型下只支持Value和AverageValue类型的目标值
target:
type: AverageValue
averageValue: 30
- metrics中target字段:target总共有3种类型:Utilization、Value、AverageValue。
- Utilization:表示平均使用率
- Value:表示实际值
- AverageValue:表示平均值
- metrics中type字段:type字段总共有4种类型:Object、Pods、Resource、External。
- Object:这里指的是指定kubernetes内部对象的指标,数据需要第三方adapter提供,只提供Value和AverageValue类型的目标值。
- Pods:这里指的是伸缩对象(stagefulSet、replicaController、replicaSet)底下的Pods的指标,数据需要第三方的adapter提供,并且只运行AverageValue类型的目标值。
- Resource:这里指的是当前伸缩对象下的pod的cpu和memory指标,只支持Utilization和AverageValue类型的目标值。
- External:这里指的是kubernetes外部的指标,数据需要第三方的adapter提供,只支持Value和AverageValue类型的目标值。
三.HPA动态伸缩原理
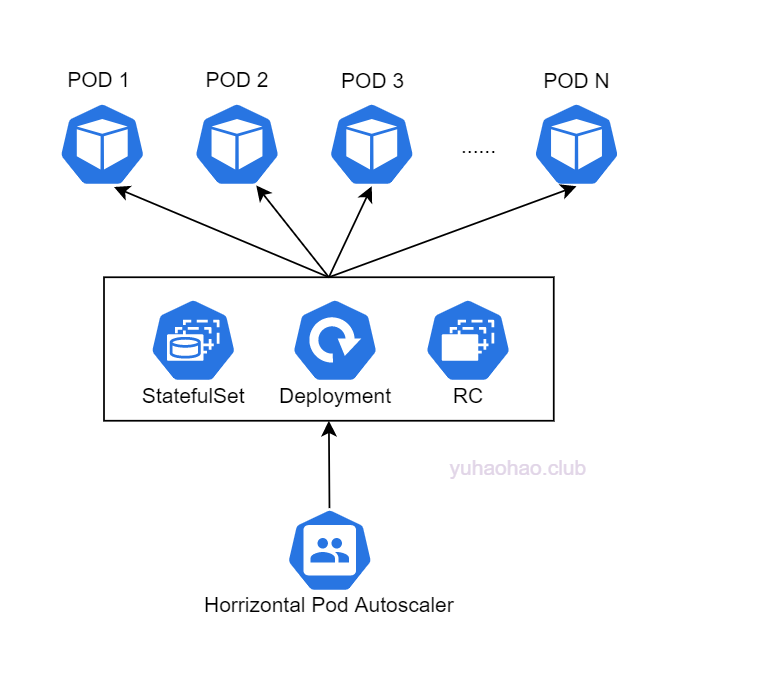
HPA在kubernetes中也由一个controller控制,controller会间隔循环HPA,检查每个HPA中监控的指标是否触发伸缩条件,默认的间隔时间为15s。一旦触发伸缩条件,controller会向kubernetes发送请求,修改伸缩对象(statefulSet、replicaController、replicaSet)子对象scale中控制pod数量的字段。kubernetess响应请求,修改scale结构体,然后会刷新一次伸缩对象的pod数量。伸缩对象被修改后,自然会通过list/watch机制增加或减少pod数量,达到动态伸缩的目的。
- 对于每个pod的资源指标(如CPU),控制器从资源指标API中获取每一个HorizontalPodAutoscaler指定的pod的指标,如果设置了目标使用率,控制器会获取每个Pod中的容器资源使用情况,并计算资源使用率。如果使用原始值,将直接使用原始数据,进而计算出目标副本数。这里注意的是,如果Pod某些容器不支持资源采集,那么该控制器将不会使用该pod的CPU使用率。
- 如果pod使用自定义指标,控制器机制与资源指标类型,区别在于自定义的指标只适用原始值,而不是利用率。
- 如果pod使用的对象指标和外部指标(每个指标描述一个对象信息),这个指标将直接跟目标指标设定值相比较,并生成一个上述的缩放比例。在最新的autoscaling/v2beta2版本API中,这个指标也可以根据pod数量平分后再进行计算。通常情况,控制器从一系列的聚合API(metrics.k8s.io,custom.metrics.k8s.io和external.metrics.k8s.io)中获取指标数据。metrics.k8s.io API通常由metrics-server(这里需要额外启动)提供。
四.HPA伸缩流程
HPA的主要伸缩流程如下:
1)判断当前Pod数量是否在HPA设定的Pod数量空间中,如果不在,过小返回最小值,过大返回最大值,结束伸缩。
2)判断指标的类型,并向api server发送对应的请求,拿到设定的监控指标。一般来说指标会从下面系列聚合API中获取(metrics.k8s.io,custom.metrics.k8s.io和external.metrics.k8s.io)。其中metrics.k8s.io一般由kubernetes自带的metrics-server来提供,主要是cpu、memory使用率指标。另外两种需要第三方的adapter来提供。custom.metrics.k8s.io提供的自定义指标数据,一般与kubernetes集群有关,比如跟特定的pod相关。external.metrics.k8s.io同样提供自定义指标数据,但一般与kubernetes集群无关,许多知名的第三方监控平台提供了adapter实现上述api(如prometheus),可以将监控和adapter一同部署在kubenetes集群中提供服务。甚至能够替换原来的metrics-server来提供上述三类api指标,达到深度定制监控数据的目标。
3)根据获取的指标,使用相关的算法计算出一个伸缩系数,并乘以当前pod数量以获得期望的pod数量。这里系数是指标的期望值与目前值的比值,如果大于1表示扩容,小于1表示缩容。指数数值有平均值(AverageValue)、平均使用率(Utilization)、裸值(Value)三种类型* * 每种类型的数值都有对应的算法。注意下面事项:如果系数有小数点,统一进一;系数如果未达到某个容忍值,HPA认为变化太小,会忽略这次变化,容忍值默认为0.1。
- 这里HPA扩容算法比较保守,如果出现获取不到指标的情况,扩容时算最小值,缩容时算最大值。如果需要计算平均值,出现pod没准备好的情况,我们保守地假设尚未就绪的pods消耗了试题指标的0%,从而进一步降低了伸缩的幅度。
- 一个HPA支持多个指标的监控,HPA会循环获取所有的指标,并计算期望的pod数量,并从期望结果中获得最大的pod数量作为最终的伸缩的pod数量。一个伸缩对象在k8s中允许对应多个HPA,但是只是k8s不会报错而已,事实上HPA彼此不知道自己监控的是同一个伸缩对象,在这个伸缩对象中的pod会被多个HPA无意义地来回修改pod数量,给系统增加消耗,如果想要指定多个监控指标,可以如上述所说,在一个HPA中添加多个监控指标。
4)检查最终pod数量是否在HPA设定的pod数量范围的区间,如果超过最大值或不足最小值都会修改为最大值或者最小值。然后会向kubernetes发出请求,修改伸缩对象的子对象scale的pod数量,结束一个HPA的检查,获取下一个HPA,完成一个伸缩流程。
五.HPA适用场景
HPA适用流量波动较大,机器资源紧张,服务数量多的业务场景。
六.部署测试
这里为了演示HPA,使用一个基于php-apache镜像来定制Docker镜像,Dockerfile内容如下:
cat Dockerfile.php
FROM php:5-apache
ADD index.php /var/www/html/index.php
RUN chmod a+rx index.php
其中,index.php页面执行一些CPU密集型计算
cat index.php
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
6.1 构建Docker
# 构建docker镜像
docker build -t hpa-php:test -f Dockerfile.php .
# 保存docker镜像成tar
docker save hpa-php:test -o php.tar
# 导入docker镜像到各个节点
docker load -i php.tar
6.2 创建php的yaml文件
[root@k8s001 php]# cat php.yaml
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: php
spec:
selector:
matchLabels:
run: php
replicas: 1
template:
metadata:
labels:
run: php
spec:
containers:
- name: php
image: hpa-php:test
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
limits:
cpu: 400m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php
labels:
run: php
spec:
ports:
- port: 80
selector:
run: php
# 部署php服务
[root@k8s001 php]# kubectl apply -f php.yaml
# 查看php服务是否部署成功
[root@k8s001 php]# kubectl get pod
NAME READY STATUS RESTARTS AGE
php-58b79cd964-gxcnc 1/1 Running 0 56s
6.3 创建HPA
由上面可见,php服务正在运行。我们使用kubectl autoscale创建自动缩放器。实现对php的deployment创建的pod的自动扩缩容。下面的命令会创建一个HPA,HPA将会根据CPU资源指标进行增加或者减少副本数:
# 给deployment创建HPA
[root@k8s001 php]# kubectl autoscale deployment php --cpu-percent=50 --min=1 --max=10
说明:这里我们让副本数维持到1-10个,所有的Pod的平均CPU使用率维持在50%(这里我们运行时pod请求的cpu为200m核,说明平均CPU使用为100m核)
# 查看HPA创建的详情
[root@k8s001 php]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php Deployment/php 0%/50% 1 10 1 29s
说明:这里由于我们没有给服务器增加负载,CPU当前消耗为0(TARGET列显示了由相应deployment控制的所有Pod的平均值)。
6.4 对php进行压测
说明:这里是针对CPU进行压测。
# 这里启动一个容器,并将无限查询循环发送php服务
kubectl run v1 -it --image=busybox /bin/sh
# 登录到容器,执行以下操作
/ # while true; do wget -q -O- http://php.default.svc.cluster.local; done
等待一分钟左右,我们查看HPA的负载情况:
[root@k8s001 php]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php Deployment/php 264%/50% 1 10 1 16m
上面可以看到,CPU消耗已经达到264%,每个pod的目标cpu使用率是50%,因此php这个deployment创建的pod副本数将调整为6个副本,为什么是6个副本,因为264/50=5.28
[root@k8s001 php]# kubectl get pod
NAME READY STATUS RESTARTS AGE
php-58b79cd964-7p9nj 1/1 Running 0 41s
php-58b79cd964-gxcnc 1/1 Running 0 24m
php-58b79cd964-hcnnv 1/1 Running 0 56s
php-58b79cd964-krmgd 1/1 Running 0 56s
php-58b79cd964-pngqw 1/1 Running 0 56s
php-58b79cd964-s86h5 1/1 Running 0 41s
[root@k8s001 php]# kubectl get deployment php
NAME READY UP-TO-DATE AVAILABLE AGE
php 6/6 6 6 25m
说明: 这里需要几分钟来稳定副本数。因为负载情况不同,因此最终副本数可能会有差异。
6.5 停止对php服务压测,查看HPA是否会对php缩容
这里我们停止向php这个服务发送查询请求,在busybox镜像创建容器的终端中,通过Ctrl+C中断while进程,几分钟后查看结果:
# 此时CPU利用率已经降到0,所以HPA将自动缩减副本数量至1。
[root@k8s001 php]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php Deployment/php 0%/50% 1 10 6 25m
php Deployment/php 0%/50% 1 10 6 25m
php Deployment/php 0%/50% 1 10 3 26m
php Deployment/php 0%/50% 1 10 3 26m
php Deployment/php 0%/50% 1 10 1 27m
# 查看deployment数
[root@k8s001 php]# kubectl get deployment php
NAME READY UP-TO-DATE AVAILABLE AGE
php 1/1 1 1 36m
注意:这里自动缩容需要几分钟。
同理,基于内存的缩容也可以参考此示例进行。这里我们就不进行演示说明了。