谷歌开源了一个新的数据集,BoundingBox,(网址在这里)这个数据集是经过人工标注的视频数据集,自然想将它尽快地运用在实际之中,那么首先需要将其下载下来;可以看到网址上给出的是csv文件,该文件中包含有视频的URL以及一些人工标注信息,本篇博文主要就是根据这个csv文件将视频下载到本地,以供后续使用。
csv的格式截图:

考虑到python的简单易用性,决定采用python实现。那么需要解决两个问题,一是解析csv文件获得视频的URL;二是根据URL将视频下载下来,感谢万能的互联网,这两个功能都有前人已经实现了,那么我们需要做的就是使用这些轮子了。
需要有以下的环境:
1、安装了python(我的是python2.7);
2、能够访问youtube(也就是翻墙);
针对于csv文件的解析,十分简单,暂且不表,但是由URL之后,youtube视频的下载却不是那么简单,幸好在github上找到了一个开源库(链接在这里),按照该项目的操作,安装好pytube之后,在python中就可以直接将其导入进来使用,该网址还给出了使用的例子,在实际运用的过程中遇到了一点问题,在使用的时候需要指定格式与分辨率才能够下载,格式还好说,直接指定成了MP4的,但是分辨率就不能够写死了,所以我将yt.filter('mp4')[-1]强制转换成str,然后取出分辨率对应的位数,再进行下载(比较脑残)。
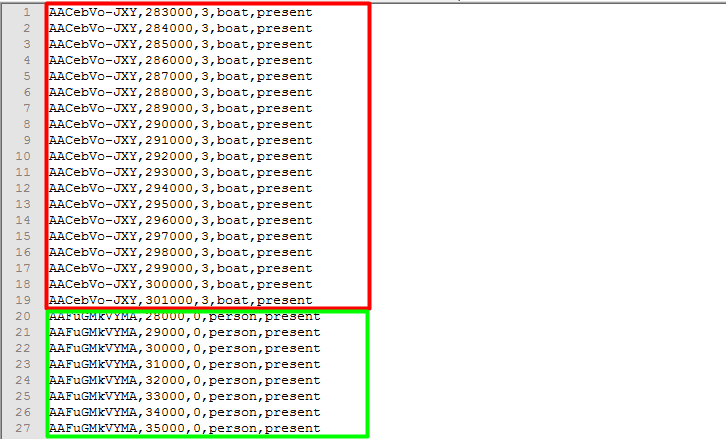
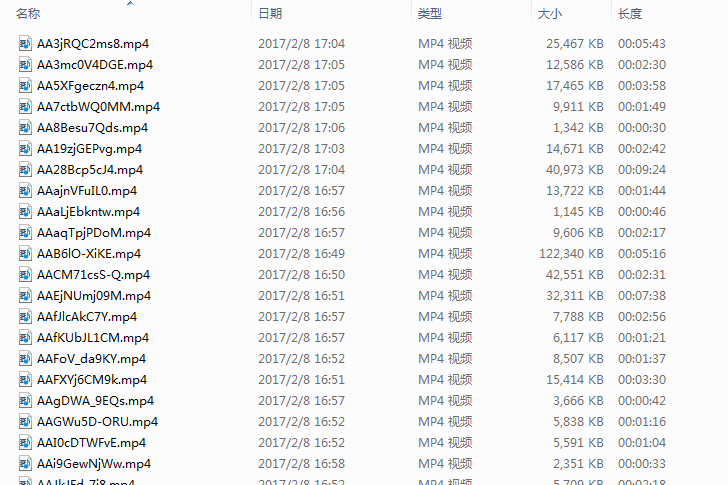
还需要注意的是直接解析csv文件,会有很多行都是同一个URL(如下图),这是需要判断一下,不同的时候再进行下载;另外,下载后存储的名字也要斟酌一下,我直接将URL中的最后一段命名视频(如下图),这样与csv文件对应比较方便,便于以后的解析与处理。
最后把代码放在这里:
1 import csv 2 from pytube import YouTube 3 4 csvfile = file('youtube_boundingboxes_detection_train.csv', 'rb') 5 reader = csv.reader(csvfile) 6 name_old = 'NULL~~' 7 for line in reader: 8 name_part = line[0] 9 name = 'http://youtu.be/' + name_part 10 if name_old != name: 11 yt = YouTube(name) 12 yt.set_filename(name_part) 13 print_out = str(yt.filter('mp4')[-1]) 14 print_out_part = print_out[23:27] 15 video = yt.get('mp4', print_out_part) 16 video.download('tmp_srx/') 17 #print(name, name_old) 18 name_old = name 19 20 csvfile.close()