参考:https://www.cnblogs.com/renxiuxing/p/14967390.html
缓存双写不一致的问题描述的是数据库和缓存中的数据一样的问题。
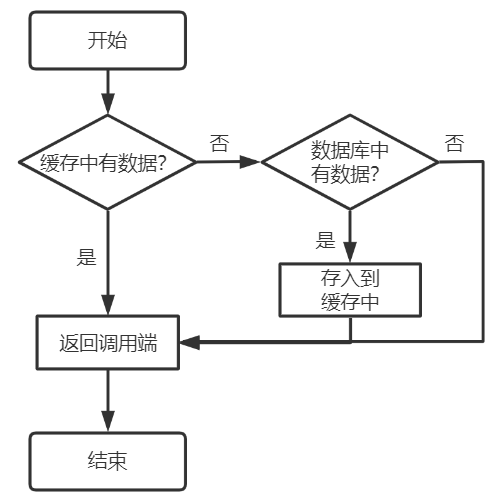
我们在调用接口去查询的时候按照下面的流程去做处理的;
数据库和缓存的更新的问题
对于更新完数据库,是更新缓存呢,还是删除缓存?又或者是先删除缓存,再更新数据库,其实大家存在很大的争议。
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。
对存入缓存的数据设置过期时间,只要到达过期时间,读请求自然会从数据库中读取新值然后回填缓存,保证是数据的最终一致;所有的写请求都以数据库为准,对缓存的操作只是尽最大努力处理到一致即可。
三种更新策略:
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库;
- 先更新数据库,再删除缓存;
先更新数据库,再更新缓存
该方案会导致不一致的原因是:请求A和请求B同时去更新;
这套方案,大家是普遍反对的。为什么呢?有如下两点原因。
- 原因一(请求A和B同时去更新)
同时有请求A和请求B进行更新操作,那么会出现:
(1)请求A更新了数据库;
(2)请求B更新了数据库;
(3)请求B更新了缓存;
(4)请求A更新了缓存;
按理说请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存,这样就导致了脏数据。
- 原因二(业务场景角度)
有如下两点:
(1)如果写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次的写请求操作都是先写入数据库,经过计算后再写入缓存,无疑是浪费性能的。显然,每次的写请求写入到数据库中之后,删除缓存更为适合,这样就不用去计算了,只有在查询的时候只计算一次就好了。
(2)如果是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,每次来的写操作都要去更新缓存,实际上好久才会读一次数据,缓存被频繁的更新都做了无用功,浪费了性能。
所以,针对缓存操作的方案还是采用 删除缓存 的方案较好;
接下来讨论的就是争议最大的,先删缓存,再更新数据库。还是先更新数据库,再删缓存的问题。
先删缓存,再更新数据库
该方案会导致不一致的原因是:同时有一个请求A进行更新操作,请求B进行查询操作。
那么会出现如下情形:
(1)请求A进行先删除缓存;
(2)请求B查询发现缓存不存在,请求B去数据库查询得到旧值,并将旧值写入缓存;
(3)请求A将新值写入数据库;
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
那么,如何解决呢?
采用延时双删策略:
(1)先删除缓存;
(2)再更新数据库;
(3)休眠1秒,再次删除缓存;
延时双删的策略还是不太好,因为休眠的这个时间不太好把控,而且影响接口的性能;若将休眠 一会,再去删除缓存的操作给异步处理了,那么可以解决性能的问题,但是若异步处理的时候失败了,还是会出现缓存不一致的问题。
先更新数据库,再删缓存
首先,先说一下。老外提出了一个缓存更新套路,名为《Cache-Aside pattern》。其中就指出
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
另外,知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出,他们用的也是先更新数据库,再删缓存的策略。
这种情况不存在并发问题么?
不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
(1)缓存刚好失效;
(2)请求A查询数据库,得一个旧值;
(3)请求B将新值写入数据库;
(4)请求B删除缓存;
(5)请求A将查到的旧值写入缓存;
如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。